AI Agent 入门
本文最后更新于 2026年3月9日 下午
以下内容来自于 NTU 李宏毅 2025 Fall 的课程 [传送门]
何为 AI Agent?
AI Agent 与普通 AI 不同之处:人类只给目标,不给明确的指示,AI 自己想办法去达成人类的目标。在此过程中,环境可能会发生一些不可预测的情况,AI Agent 需要根据环境来灵活地调整计划。
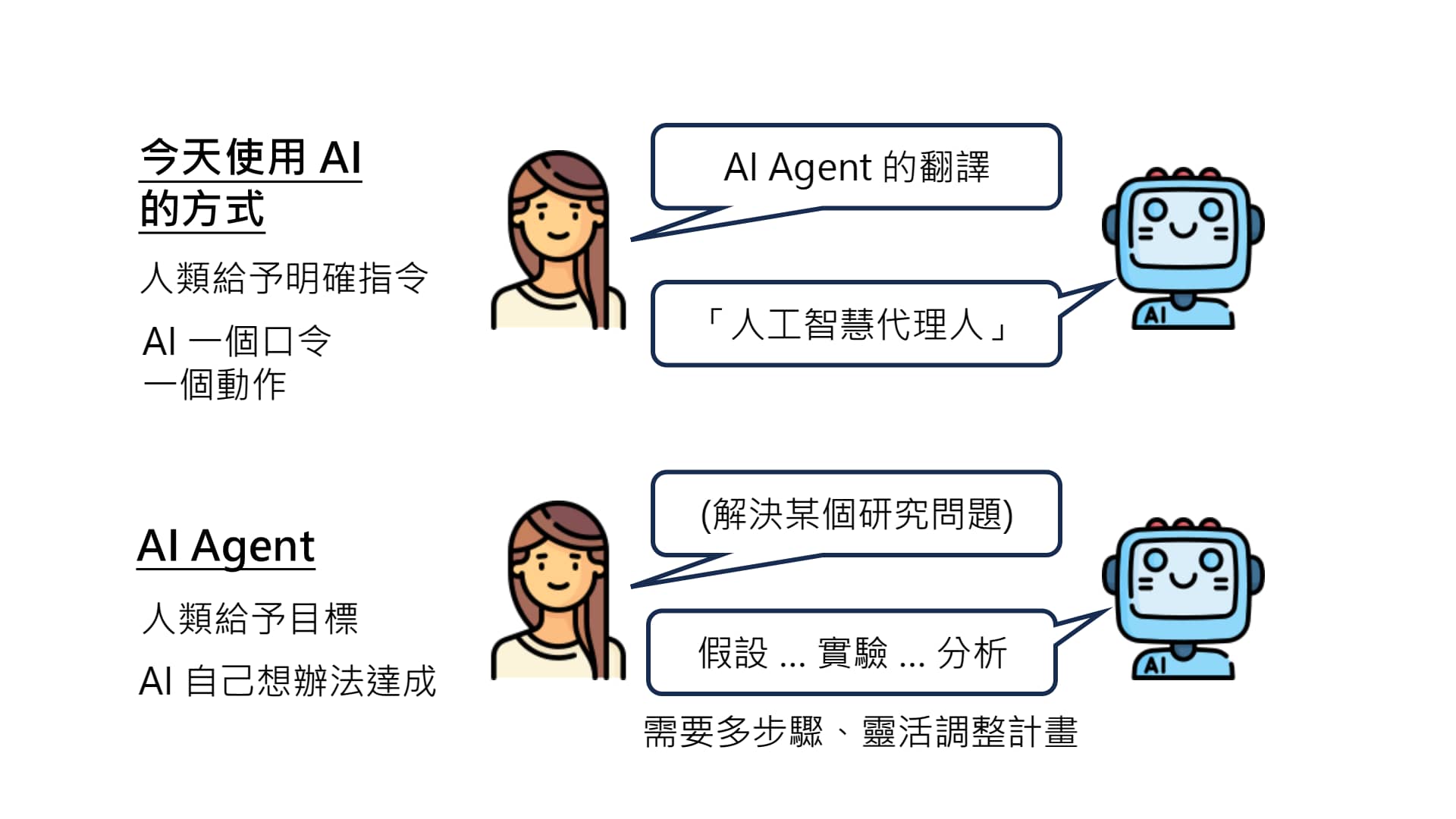
何为 AI Agent
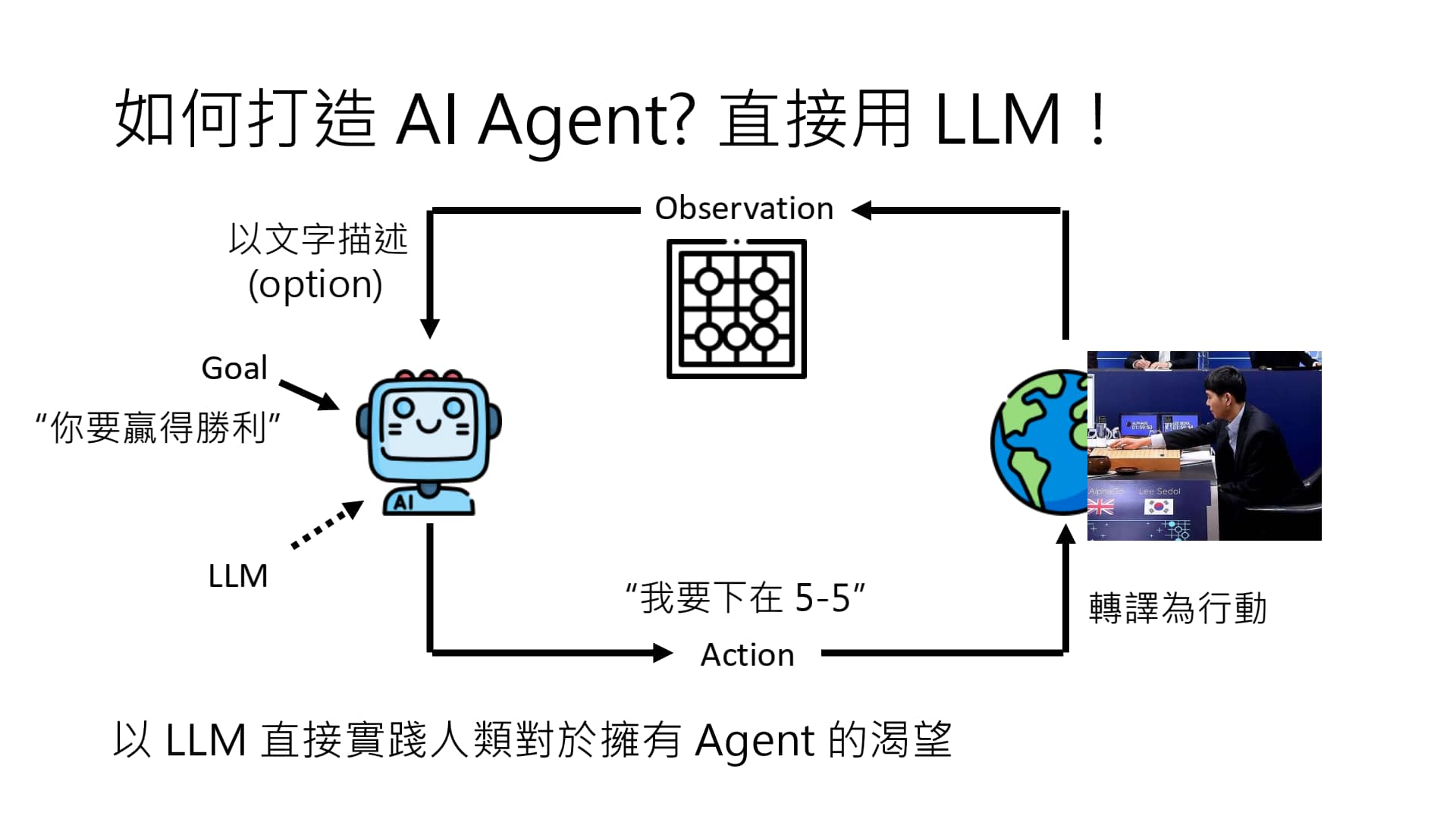
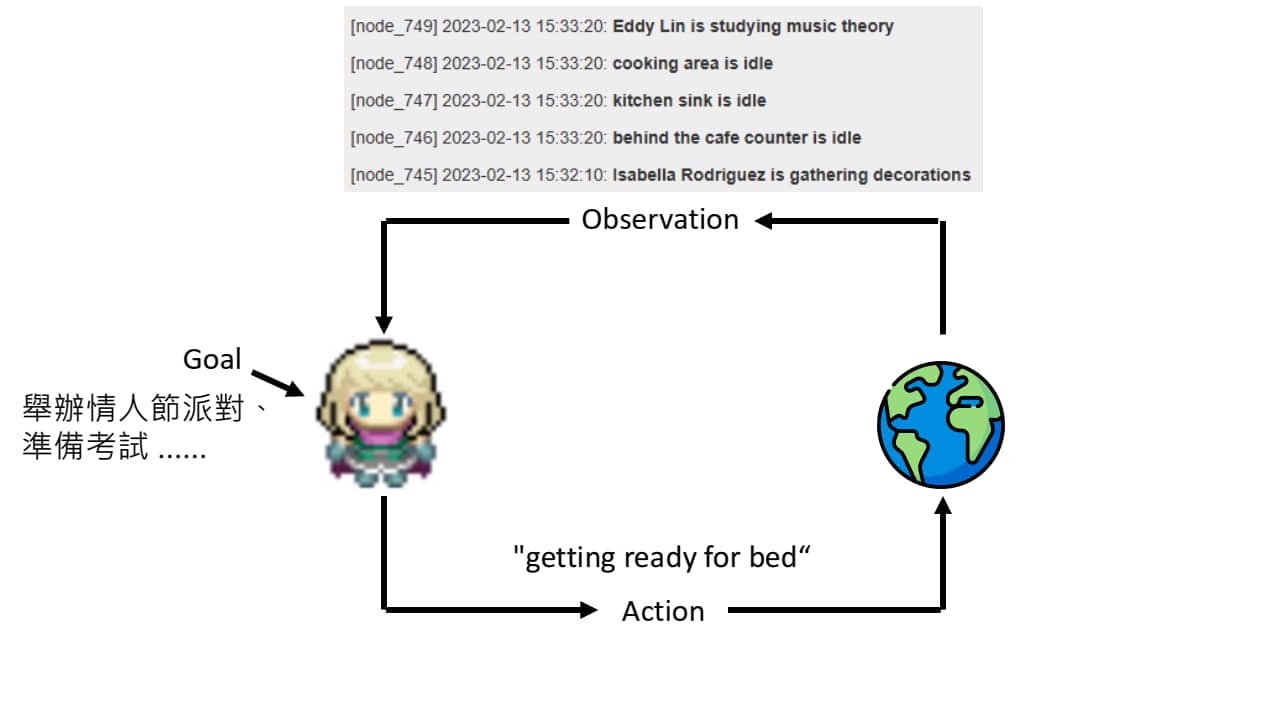
AI Agent 先接受一个输出,即人类目标(Goal),然后观察目前的状况(Observation),分析目前状况后决定采取一些行动(Action),进而影响环境的状态。上述过程会改变 Observation,进而再次执行不同的 Action,上述过程一直循环,直至达成目标。
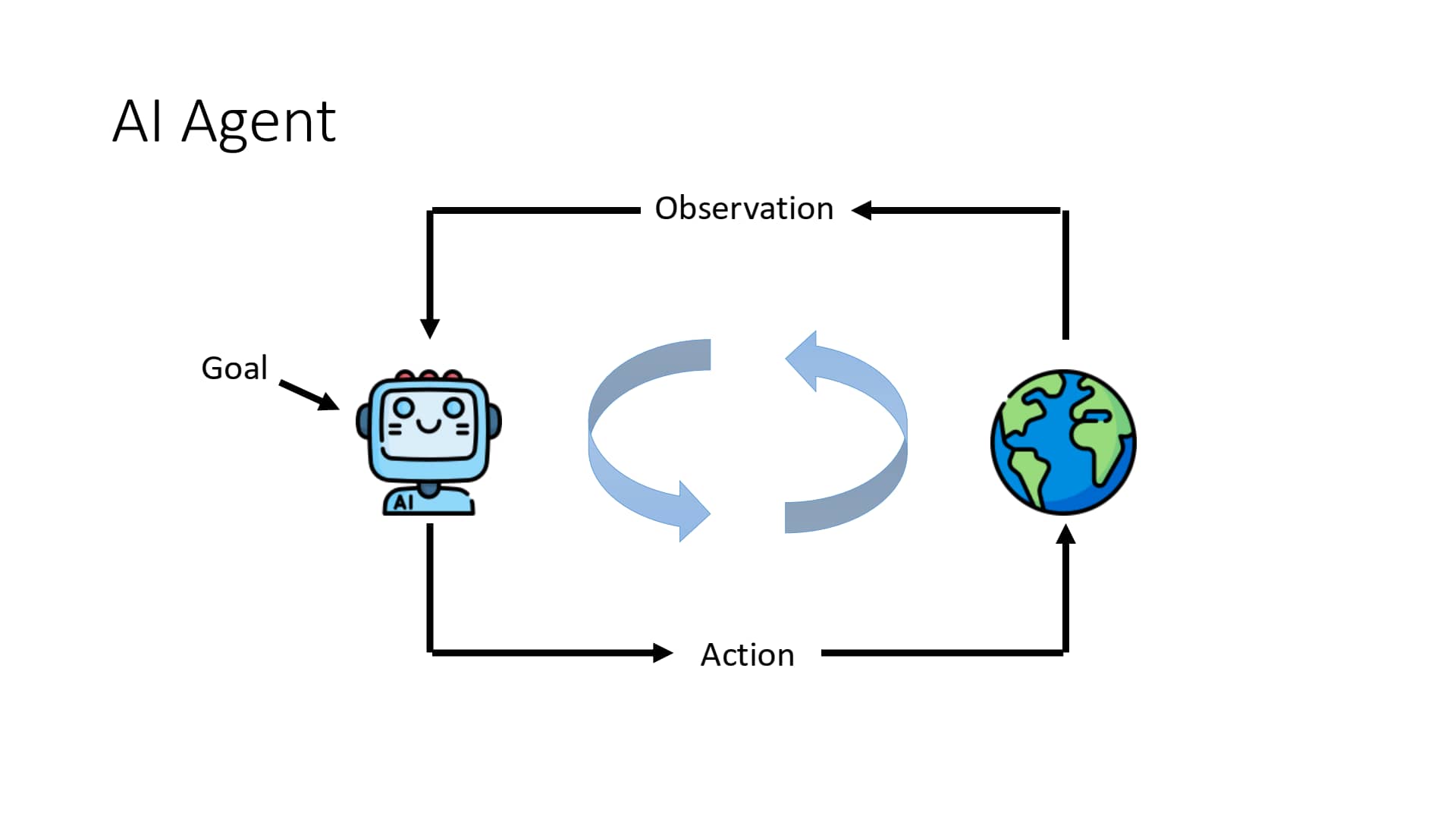
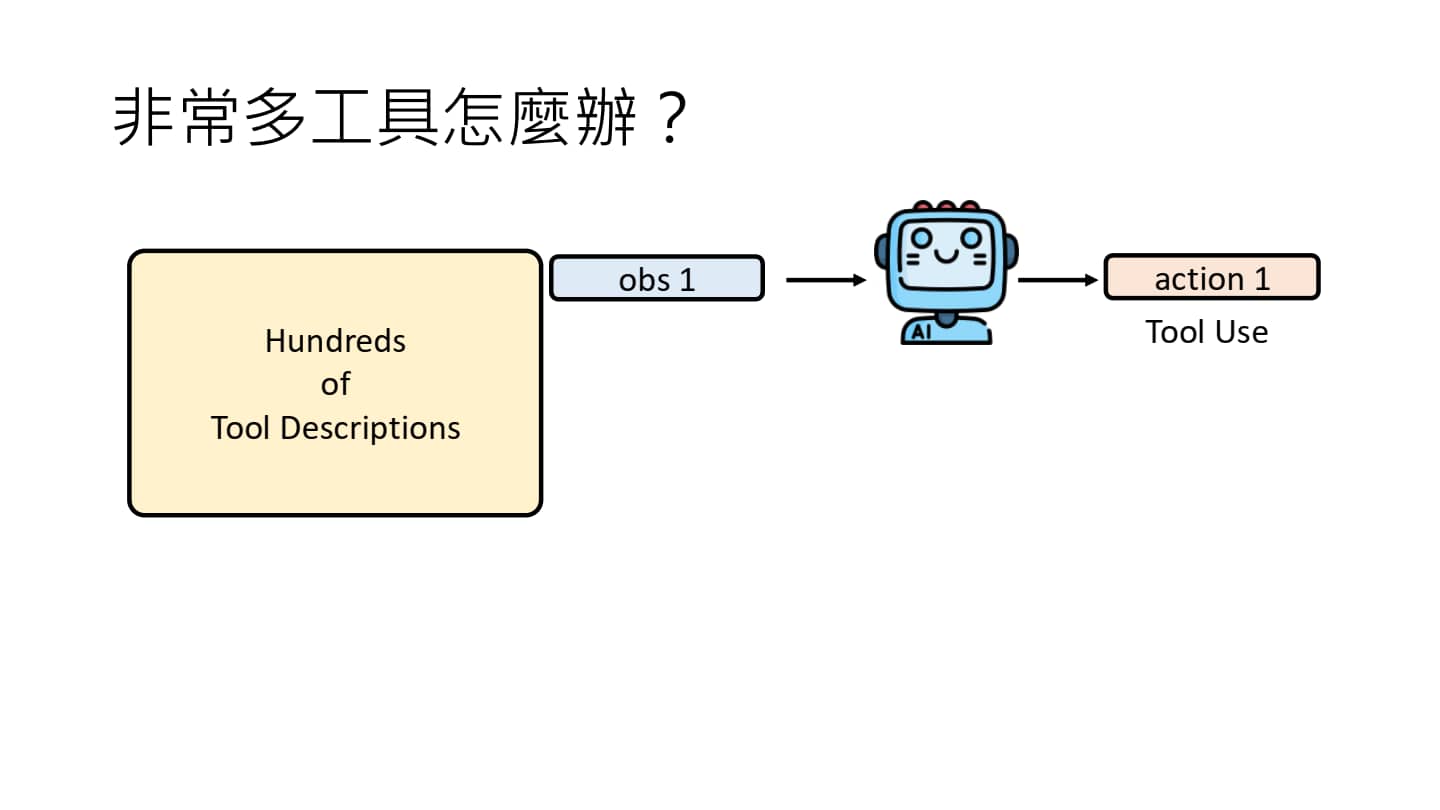
AI Agent 工作的大致流程 & 具体示例
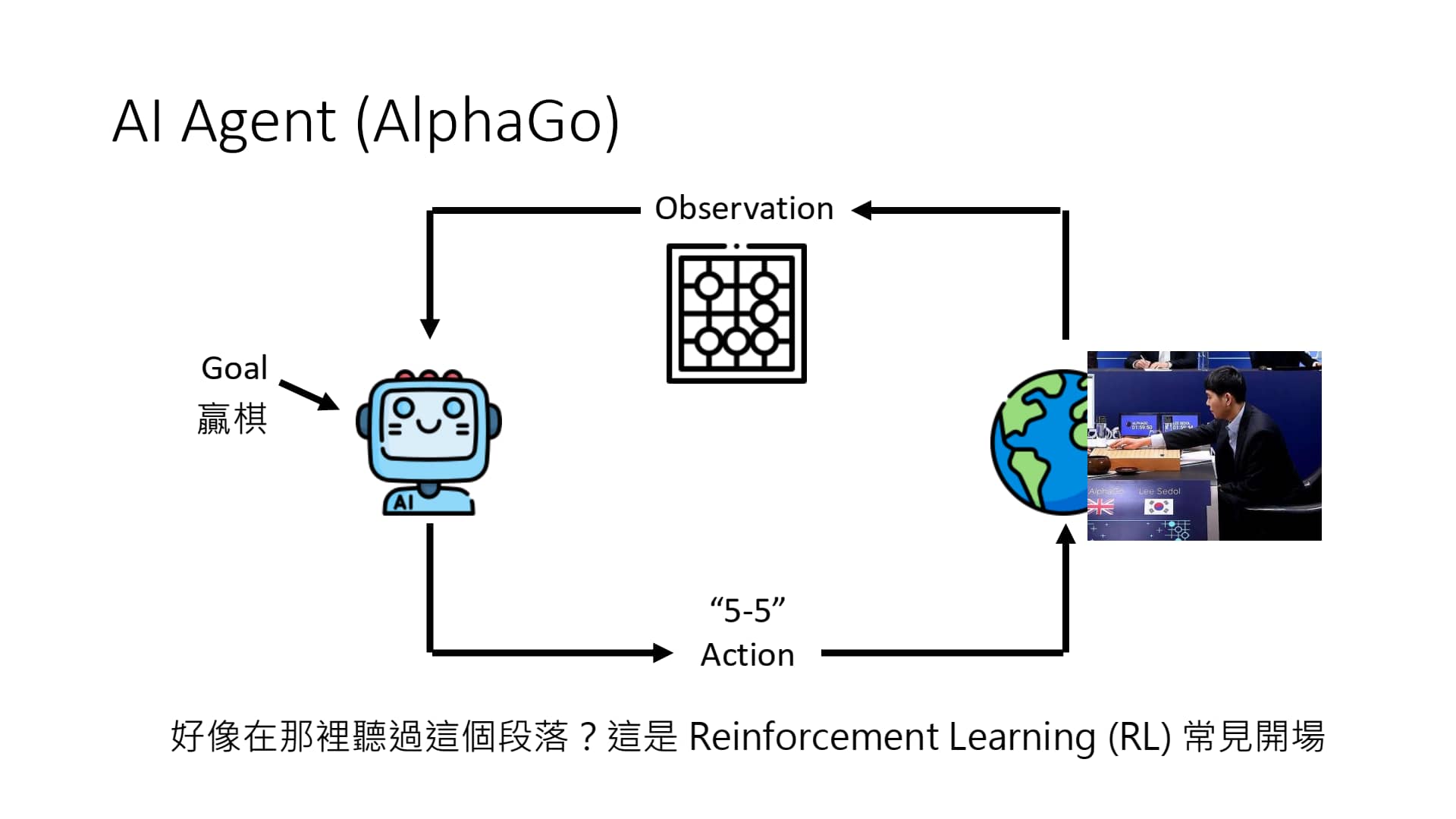
先前人们主要采用 RL 来训练 AI Agent。具体方法是:设计一个 reward,让 AI Agent 学习去如何最大化 reward。
但这种方法具有 局限性:对于不同的任务,我们需要用 RL 对每个任务专门训练一个模型!
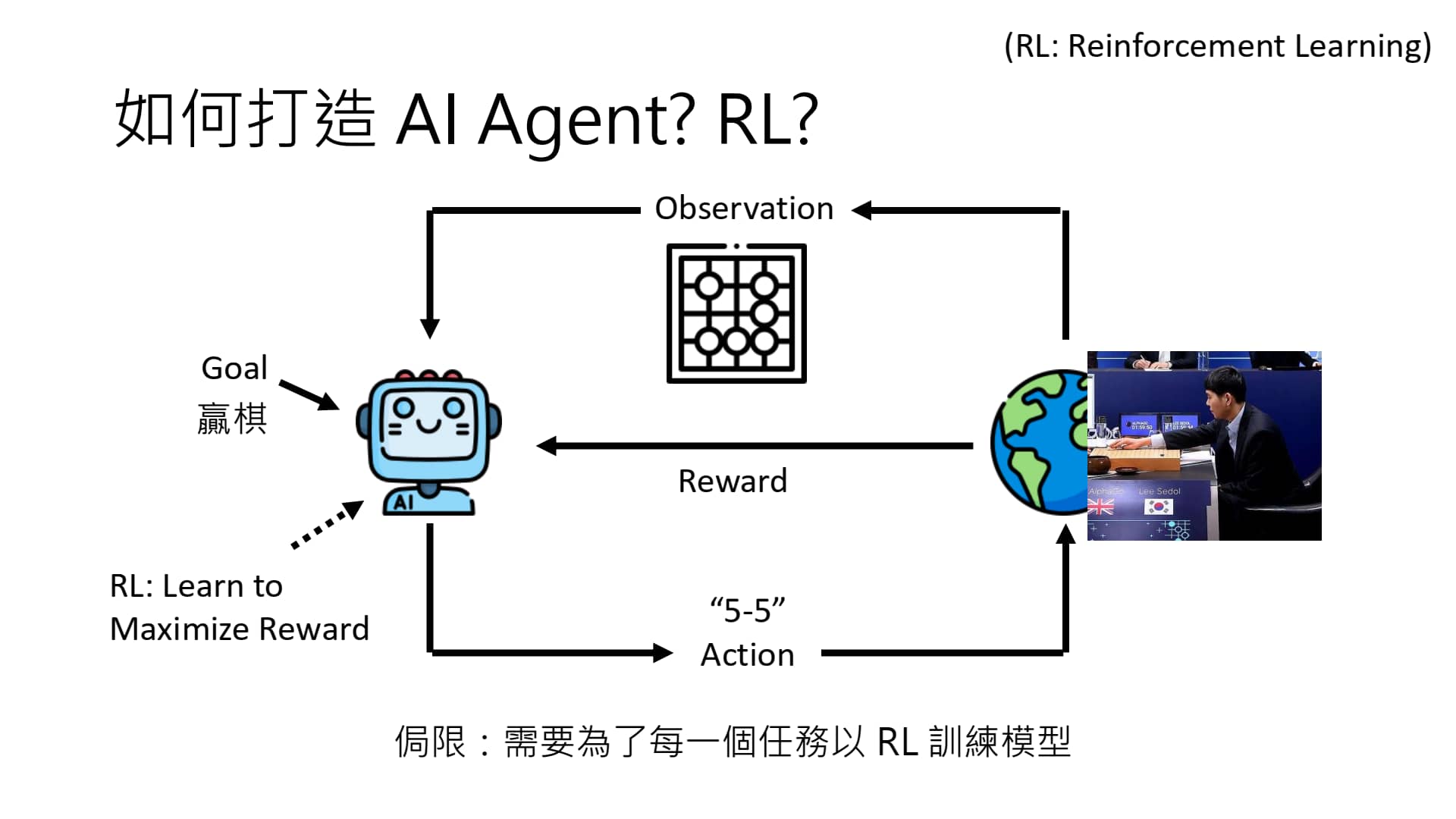
RL 训练 AI Agent & LLM 创建 AI Agent
每次都重新训练模型太复杂,我们能否直接把 LLM 当作一个 AI Agent 来使用呢?
大致过程是:将上面过程中的全部内容用 text/image 表示,用 LLM 决策,再将指令转为对环境作用的 Action,得到新的 Observation,如此循环下去。
本质:利用当前 LLM 的强劲性能,避免多次训练模型。
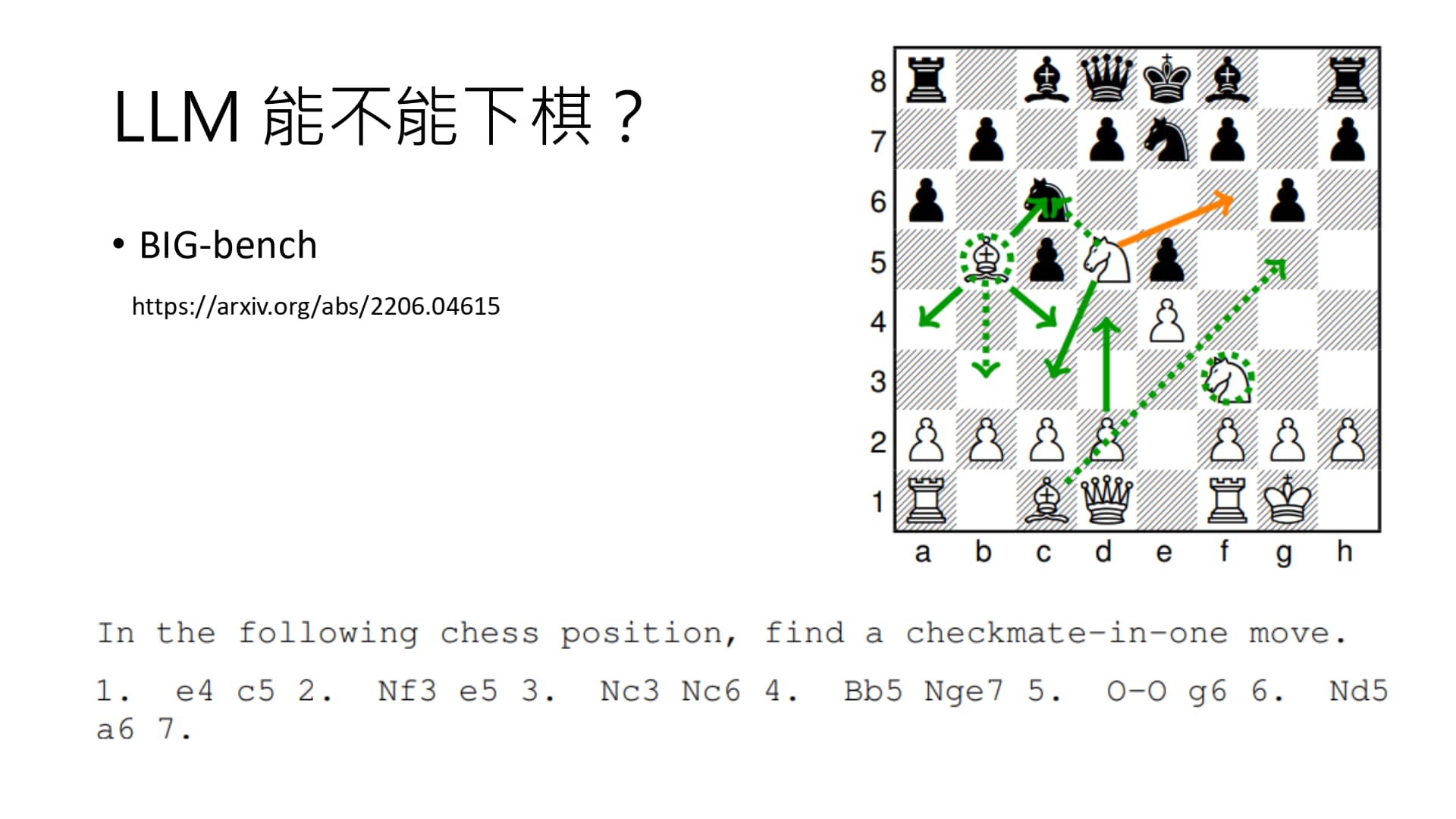
左图:古早时期人们用 LLM 做下棋 Agent 的尝试。目标:白方将军。橙色为正确答案,实线为符合规则的走法,虚线为不符合规则的走法。
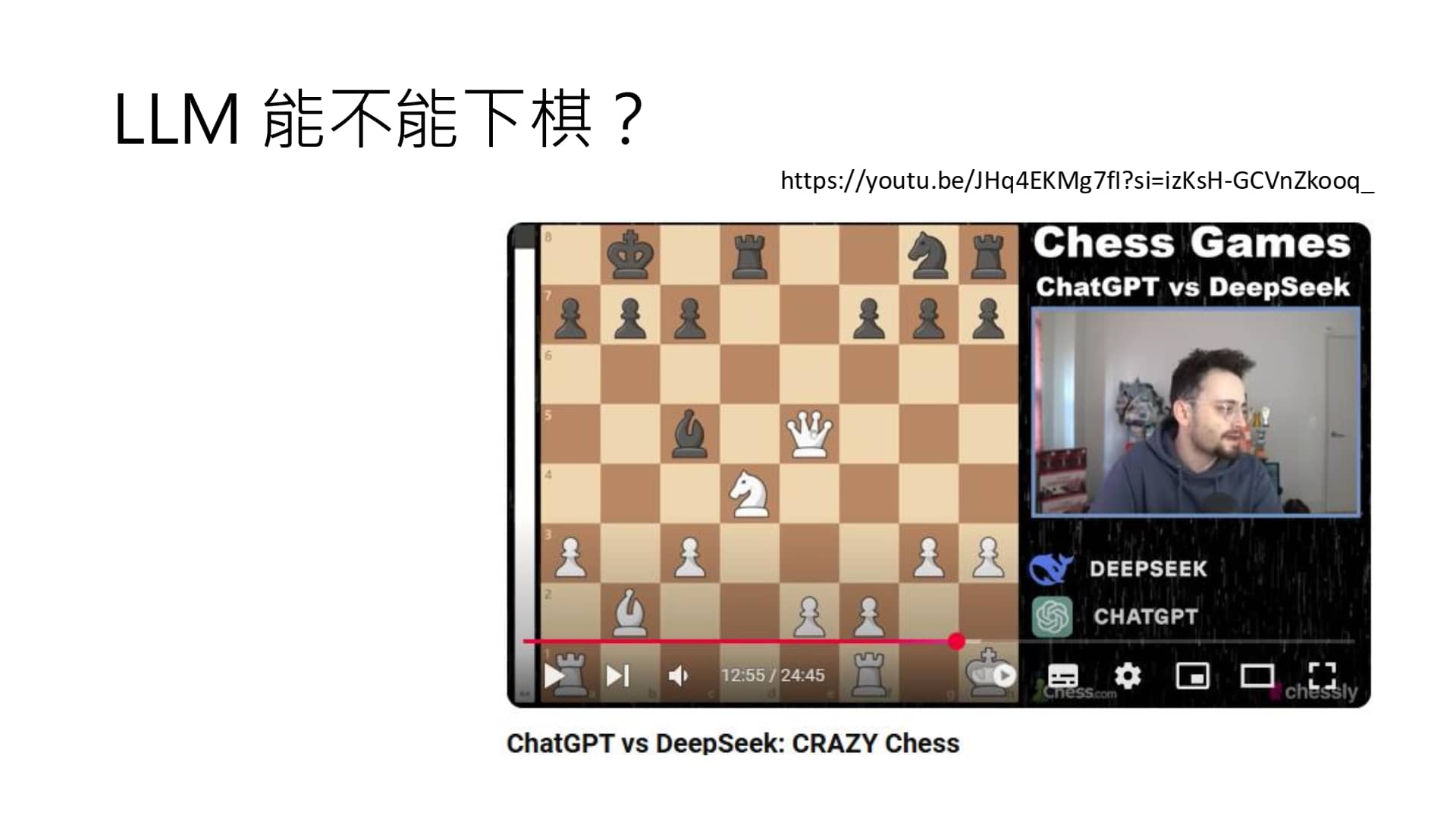
右图:Deepseek 与 Chatgpt 的抽象对决(2025.01.30)
Deepseek 与 Chatgpt 抽象对决的 传送门
如果将 LLM 用于 Agent 上,LLM 会不断做“接龙”(接受一个 observation,输出一个 action),事实上与 LLM 本来的功能(文本接龙)没什么不同。
因此,AI Agent 并不是什么新技术(并没有训练新模型),而是一种可以发挥语言模型原有能力的新应用!
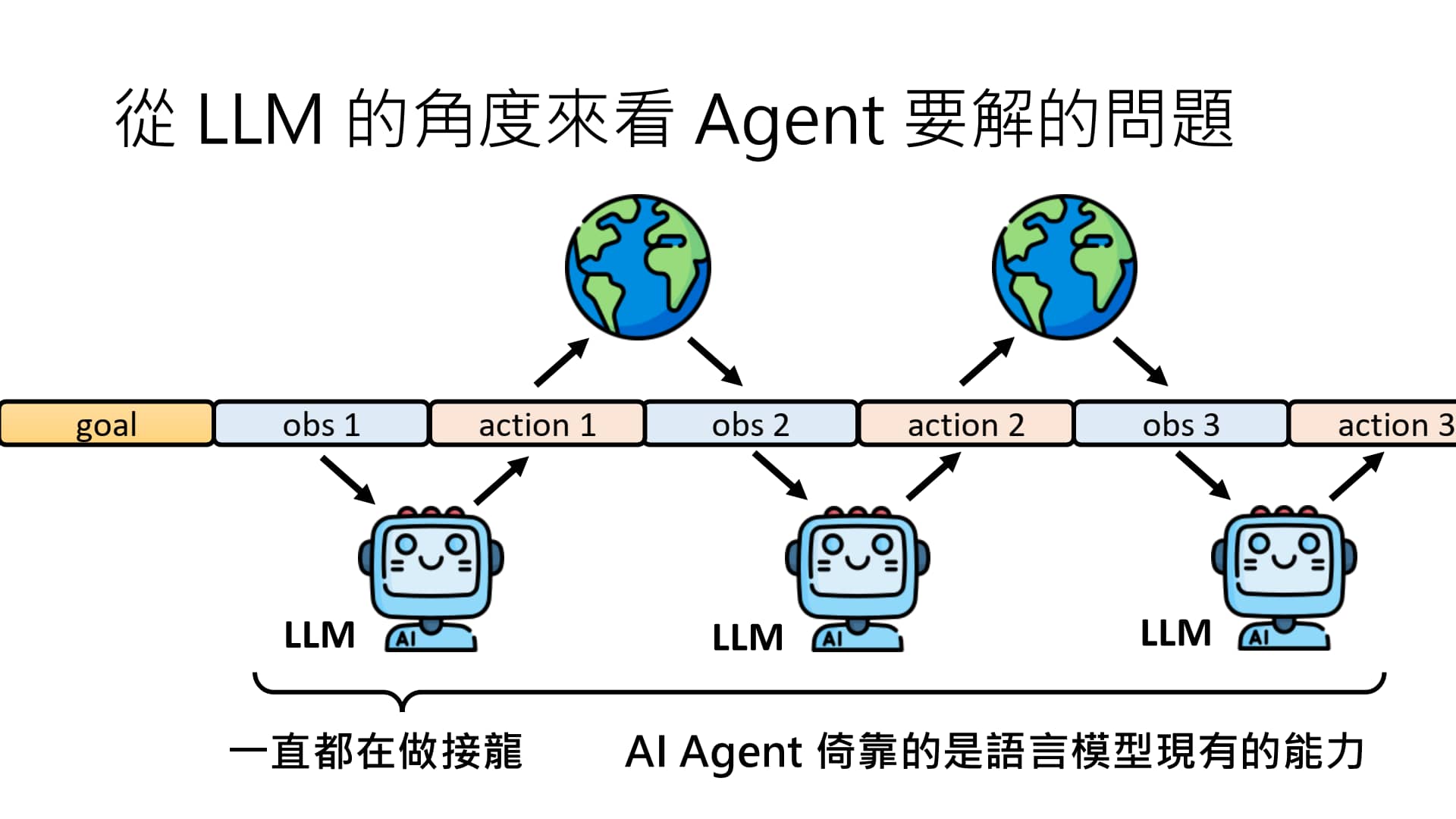
LLM 用于 Agent 上需要解决的问题
事实上 2023 年就有过一阵 AI Agent 的热潮(AutoGPT、AgentGPT等),但因为性能一般而消退。
LLM 运行 AI Agent 的优势与具体案例
LLM 用于 Agent 的优势
LLM 运行 AI Agent 有什么优势?
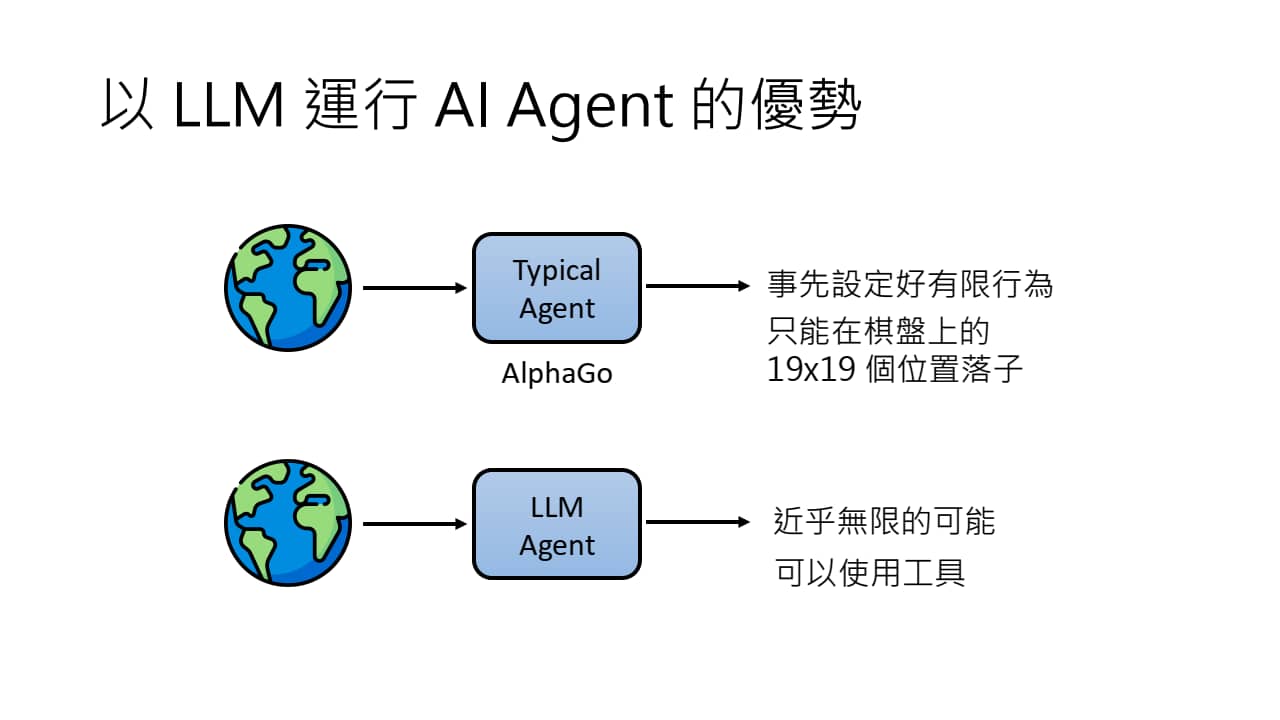
- LLM Agent 不会局限于某个具体任务,可以使用各式各样的工具来解决各种各样的问题,从而具有更多的可能性。
- 相较于 RL 训练出来的 Agent,LLM Agent 无需经过复杂的 reward 设计过程,而且可以利用环境中更多信息来提高生成质量。
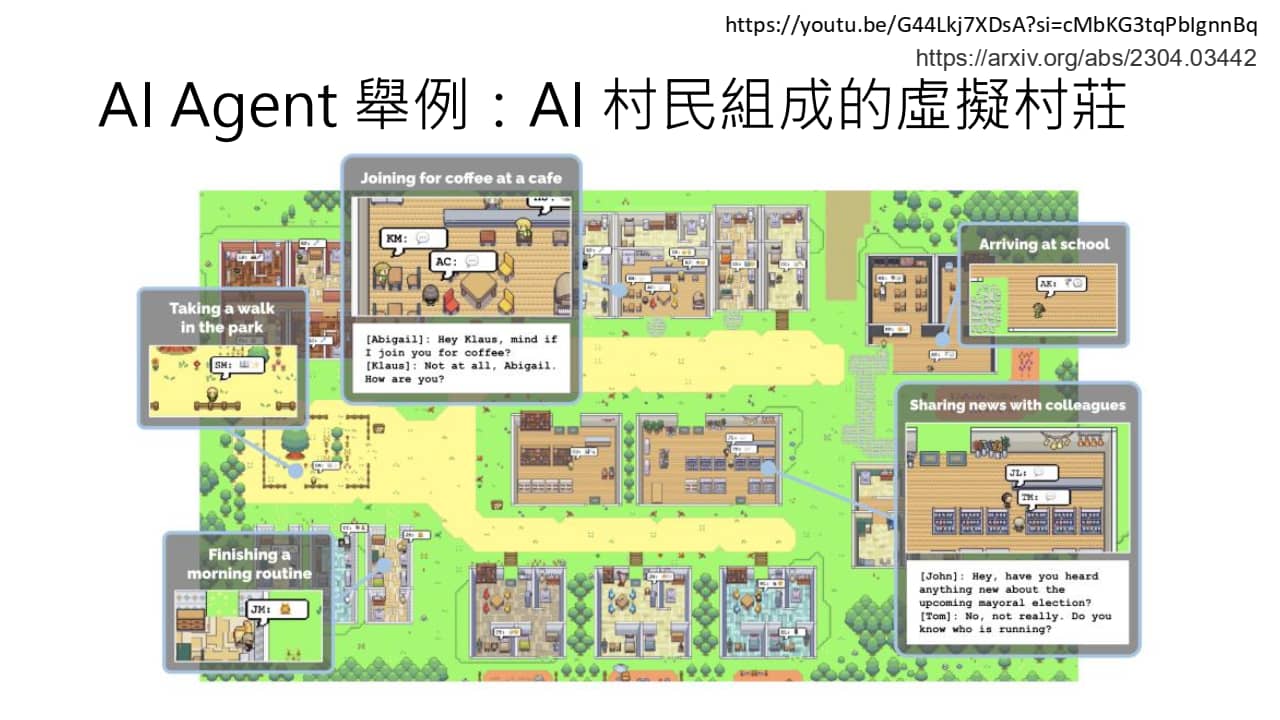
在古早时期(2023)人们用 LLM AI Agent 驱动的 AI NPC 组成的虚拟村庄
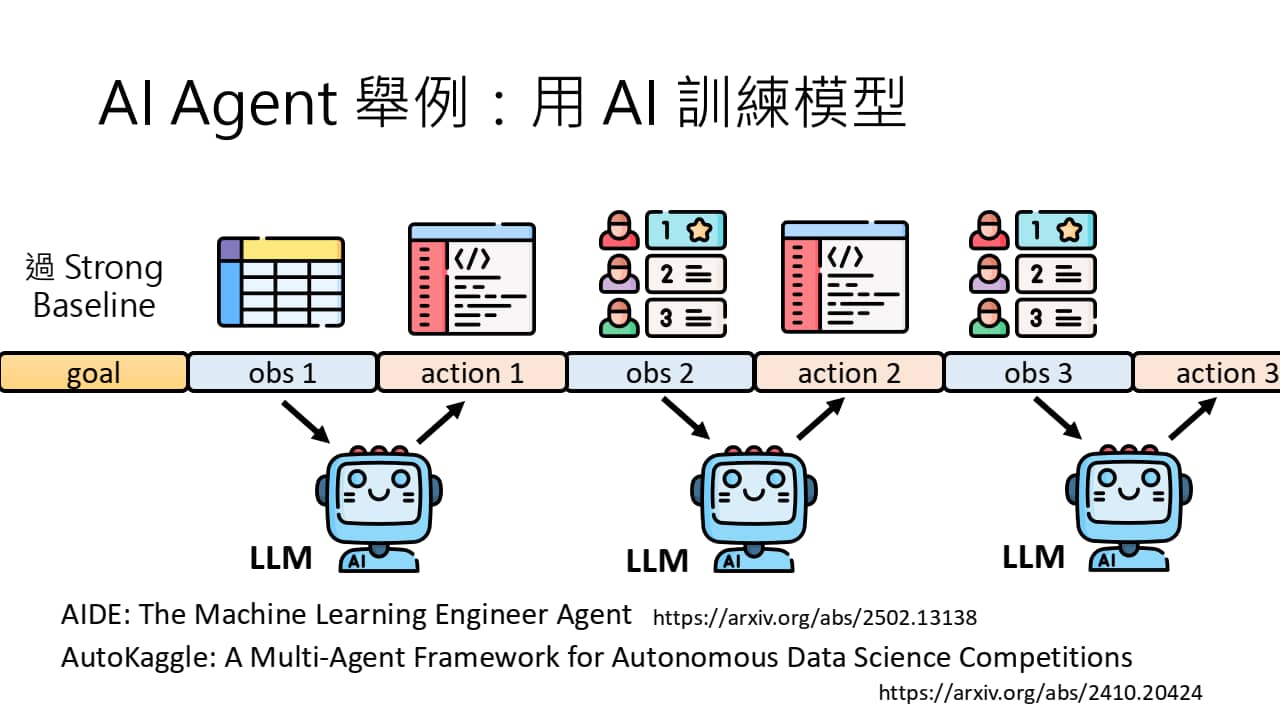
左图:目标为过 strong baseline。LLM 会不断通过正确率来编写更高质量的代码,直至达成目标。
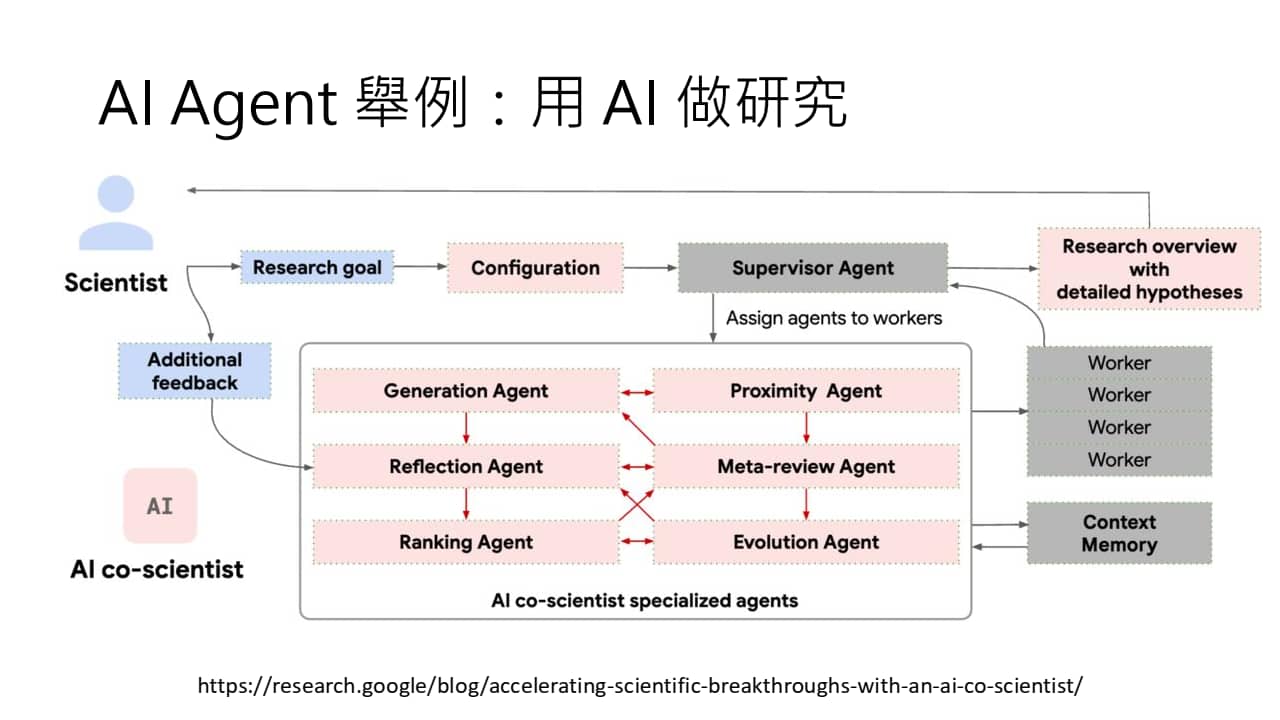
右图:Google 用 AI Agent 设计研究框架。
上面的几个 AI Agent 的例子互动方式都是回合制的(observation 与 action 轮流进行)。但在更真实的情况下,互动应该是“即时”的——可能上一个 action 还没结束,环境已经发生改变。AI Agent 应该能对环境变化及时做出响应,并对 action 做出调整。
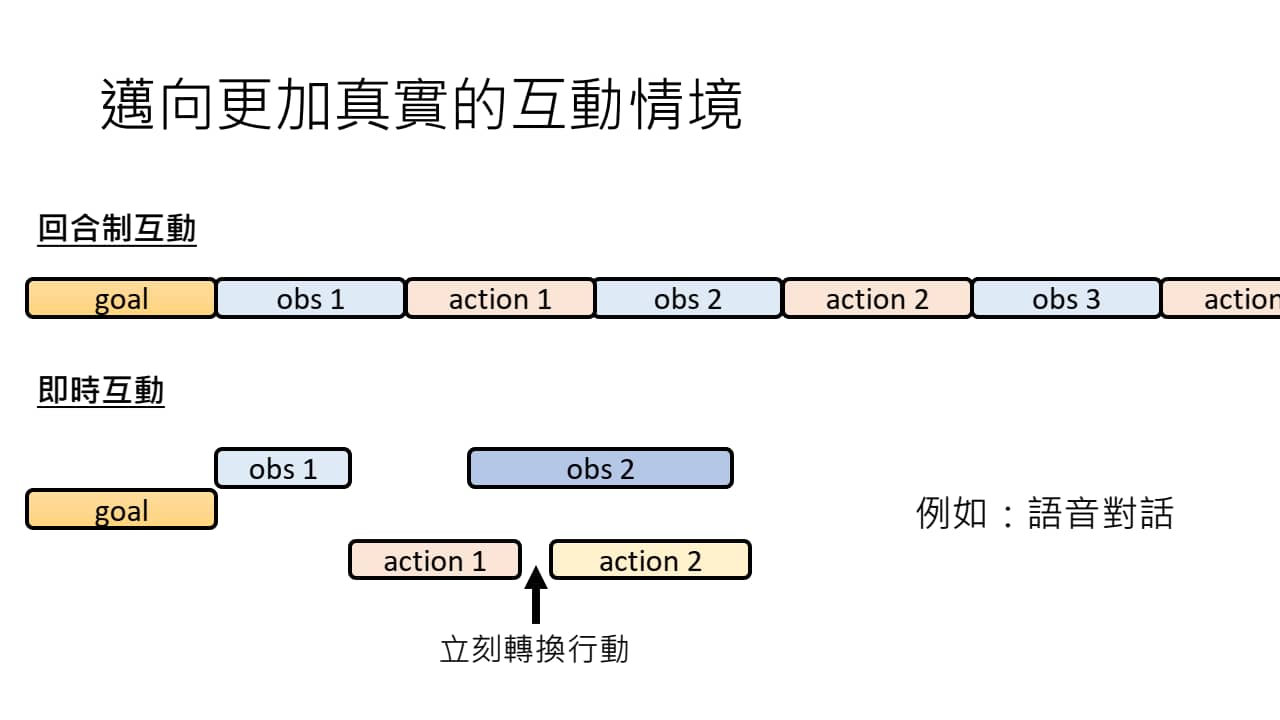
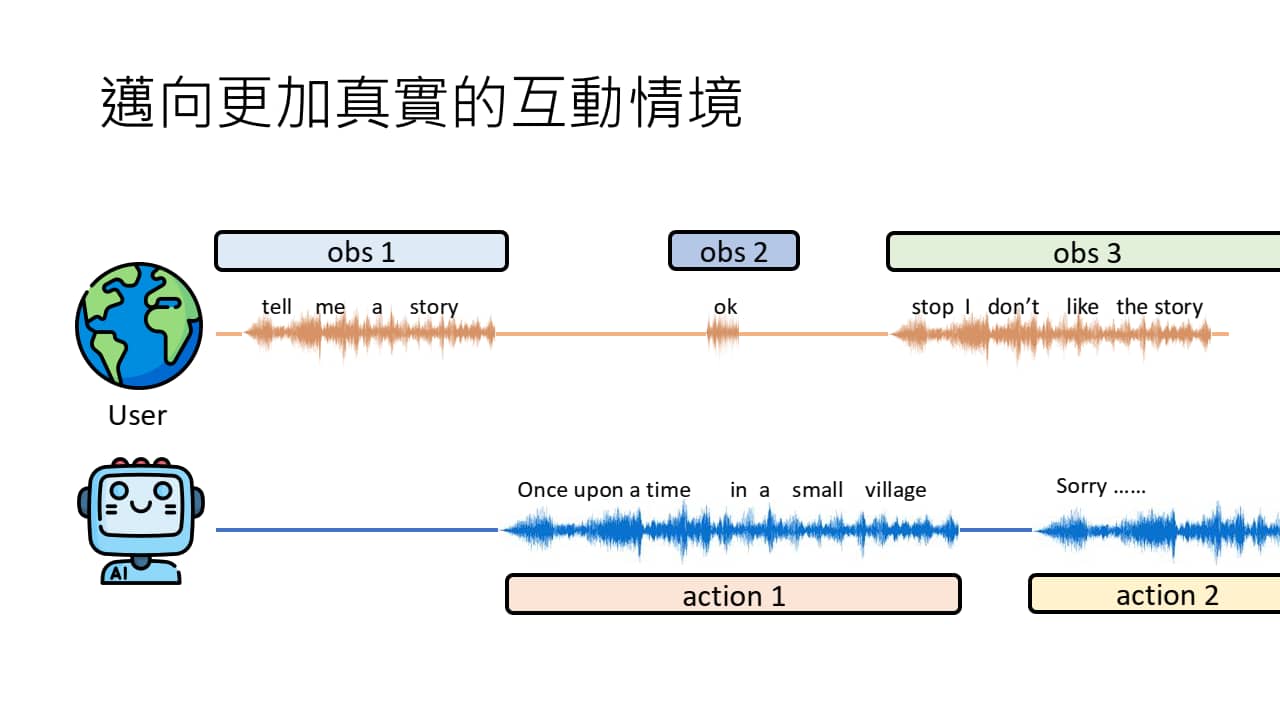
语音对话就是经典的即时性互动(可能随时会互相打断)
AI Agent 如何根据经验调整行为
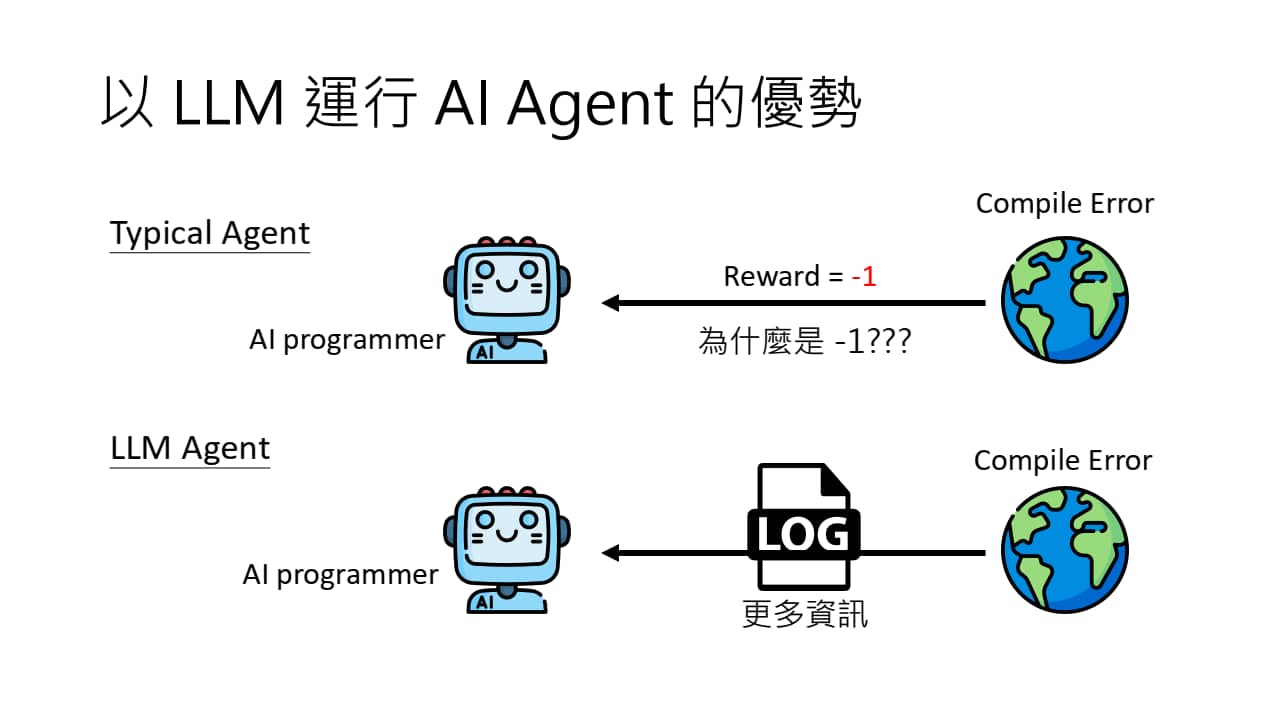
对于一个编程任务,传统方法是根据反馈(报错),更新模型参数,从而实现模型的训练。事实上,我们直接把报错输入 LLM 中重新生成即可,这样不用微调也可以更新代码。
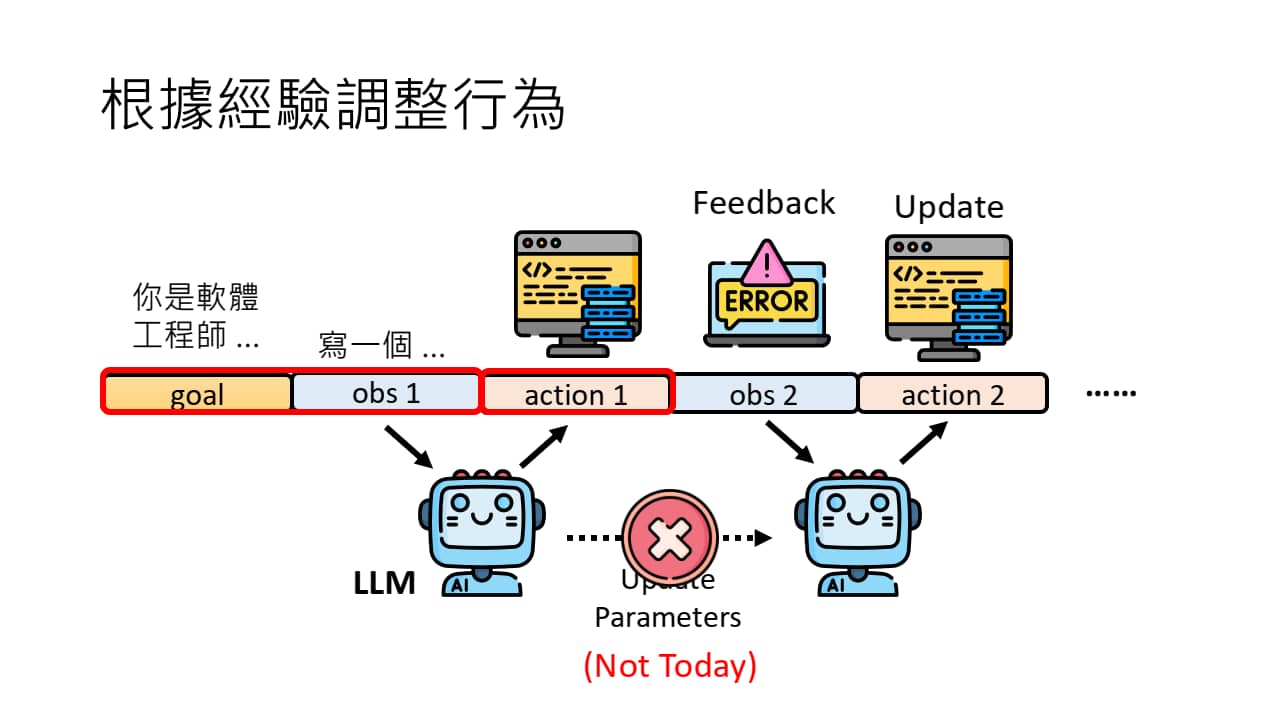
不训练模型(左图),直接再次输入 LLM 即可更新代码(右图)
为何无需微调?因为 LLM 本身就具有上下文能力,所以可以根据上下文来生成代码,而无需像传统方法那样反复训练。
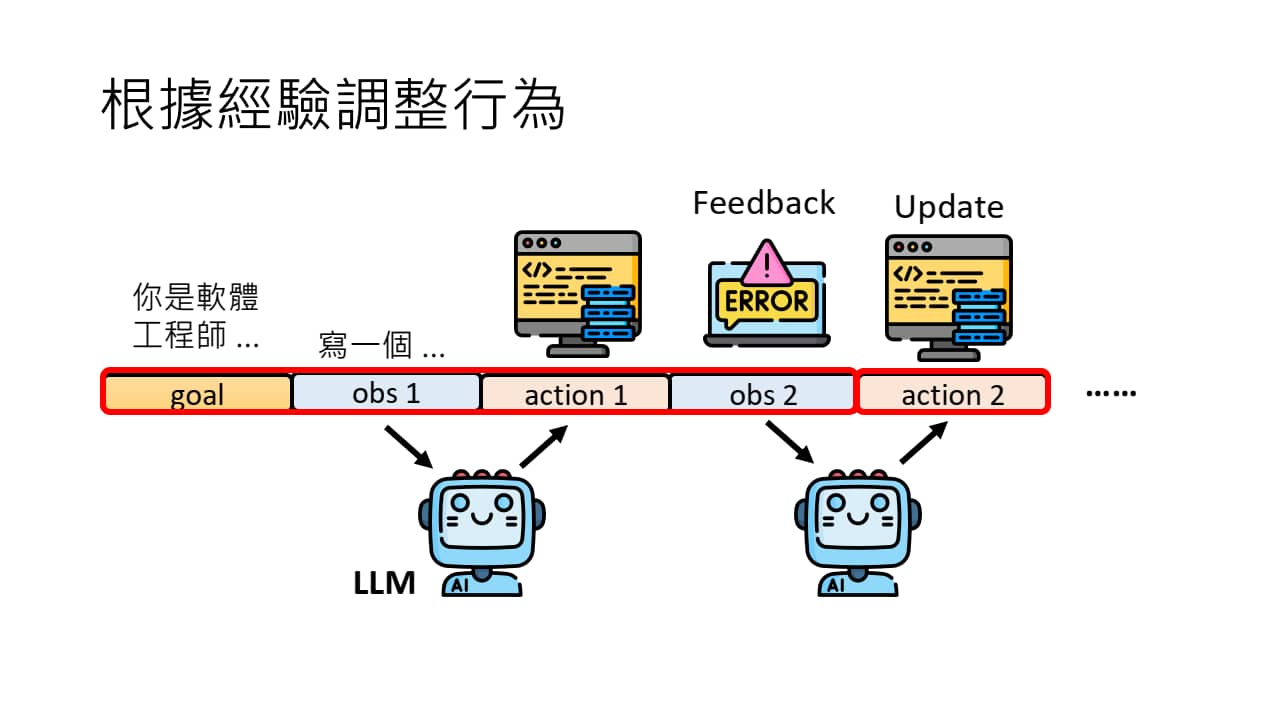
这种反复根据 上文+反馈 重复生成的方式能 work,但是也会带来一些问题——AI Agent 可能会被早期冗余信息干扰,进而影响决策。
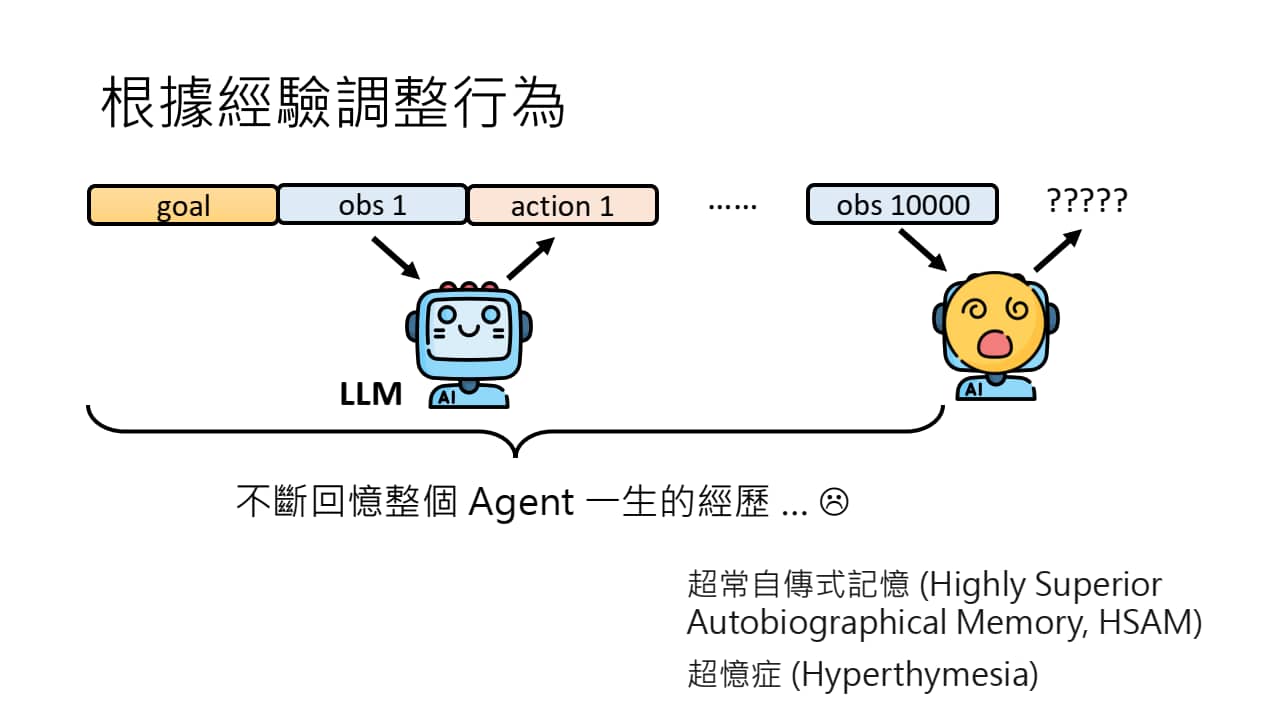
不断增长上下文对 AI Agent 做决策并不一定是一件好事。
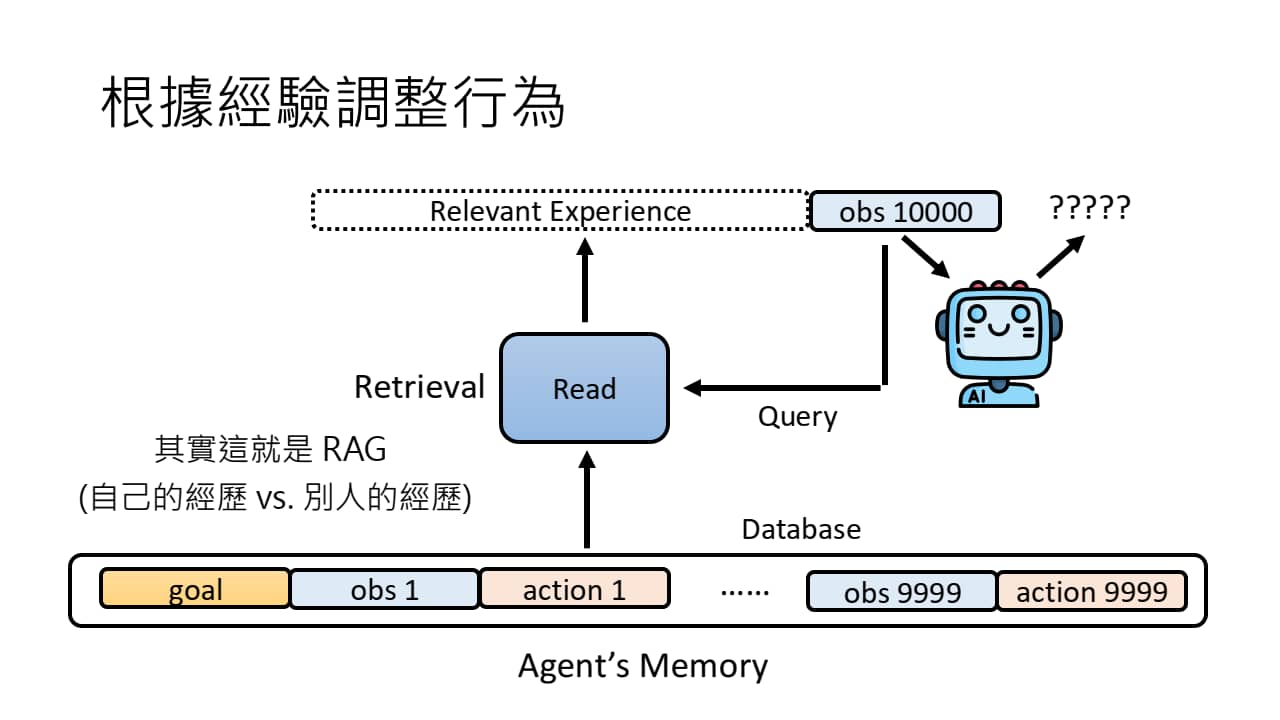
我们可以借鉴人类的长期记忆,将 AI Agent 的往期过程存入 Memory 中,用一个 Read 模块读取 Memory 中与当前任务有关的经验,并将这些 Relevant Experience 放在 Observation 前,再让 LLM 进行接龙。
可以将上述过程看作是一个 RAG(Retrieval Augment Generation):Read 是检索模块,Observation 是问题,AI Agent 的长期记忆是资料库。
但是构建记忆库的时候有必要将全部事件都记入吗?
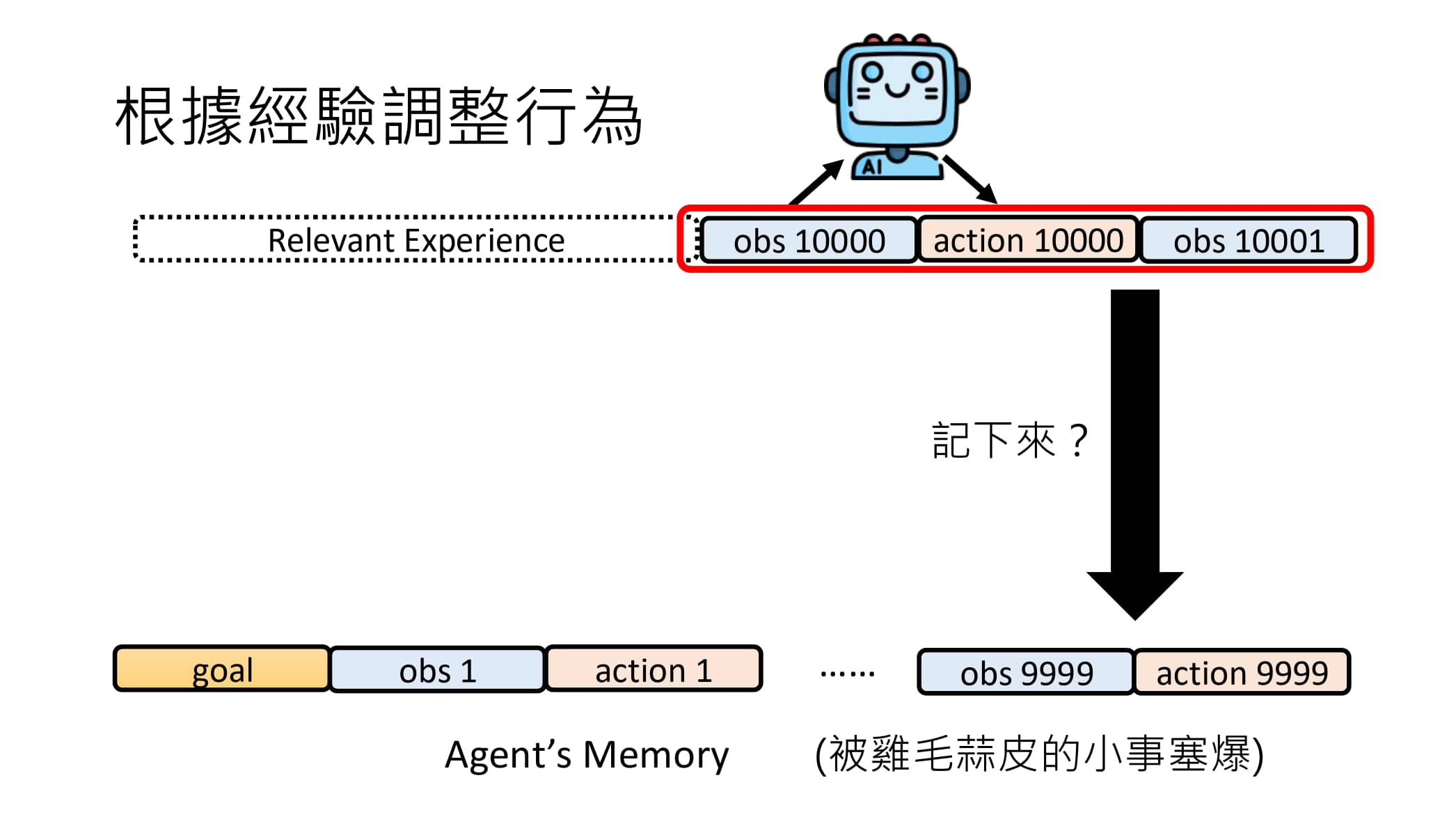
事件不一定要全记录到 Memory 中,用 Write 做分拣
就和上面 Read 可能遇到的“信息过载”问题一样,如果什么信息都存入 Agent 长期记忆库,会导致其中含有大量与任务无关的信息(鸡毛蒜皮的小事),这显然是不好的。
如何区分那些事件比较重要?
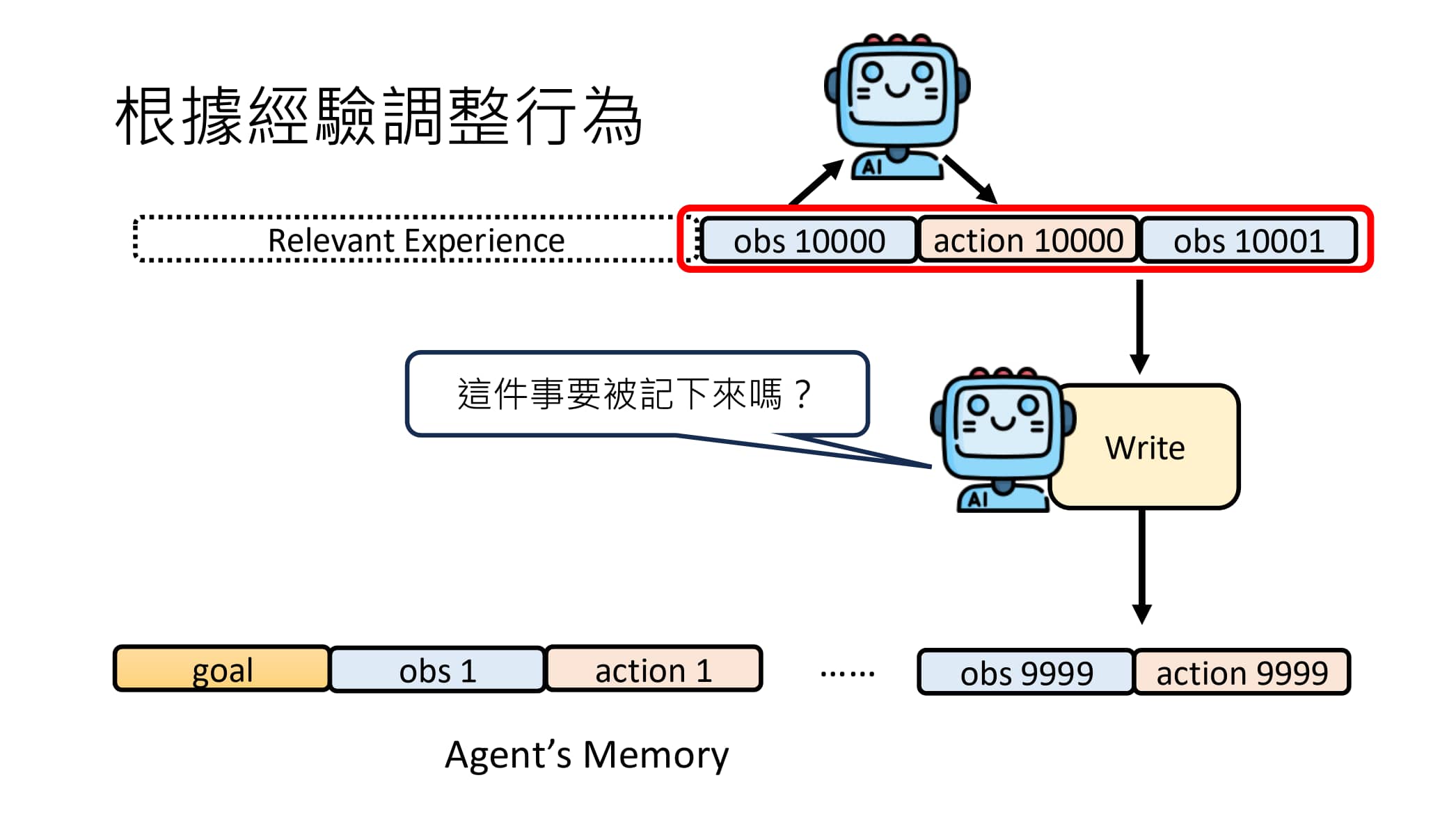
加入一个 Write 模块用于决定什么样的信息应该丢弃、什么样的信息应该存入长期记忆库中。
应该如何构建这样的 Write 模块?
一个比较直接的选择就是 直接选用一个语言模型甚至 AI Agent,每次调用就询问自己“这件事有必要记录下来吗?”
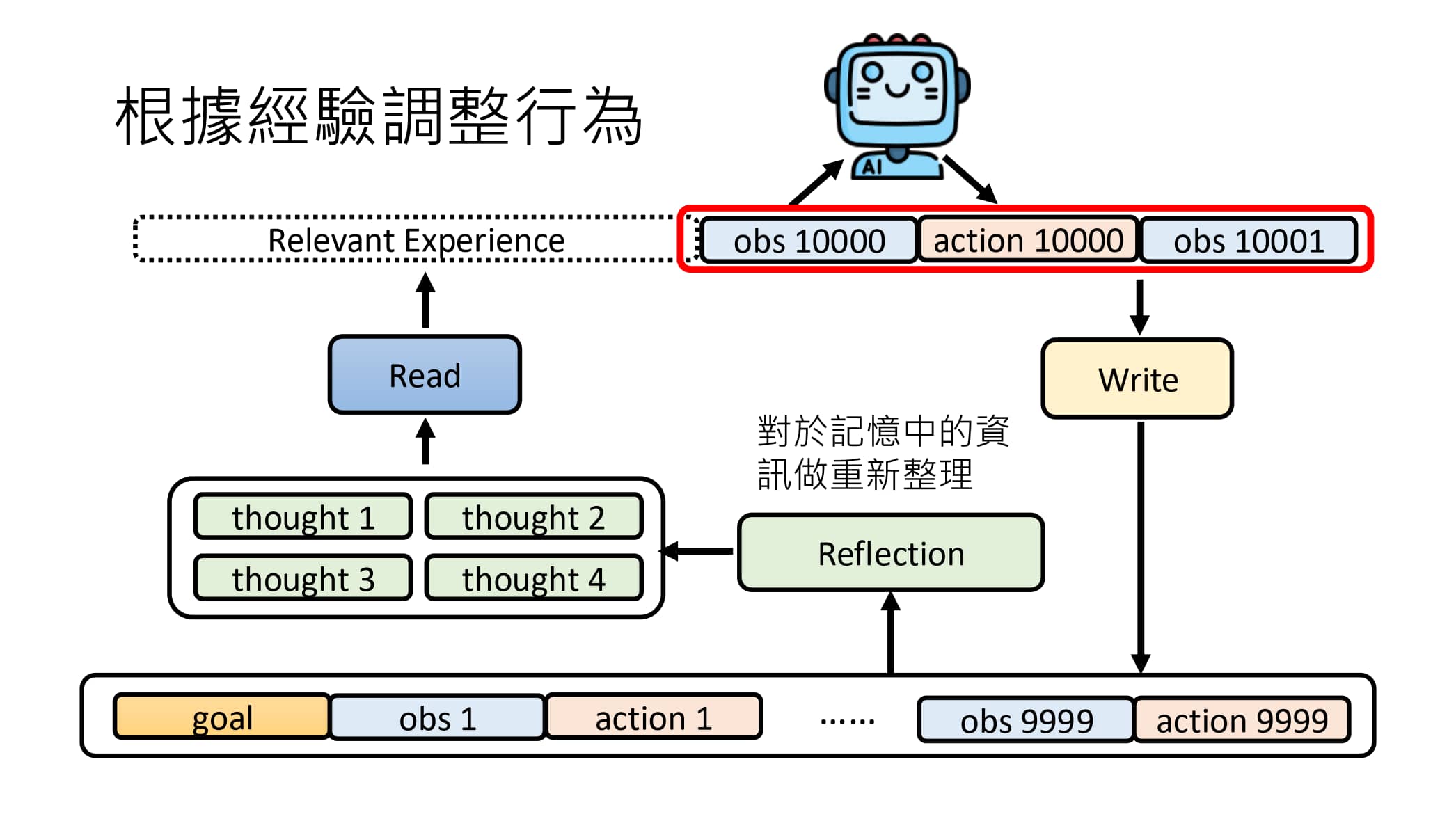
还可以再加入一个 Reflection 模块进行整理
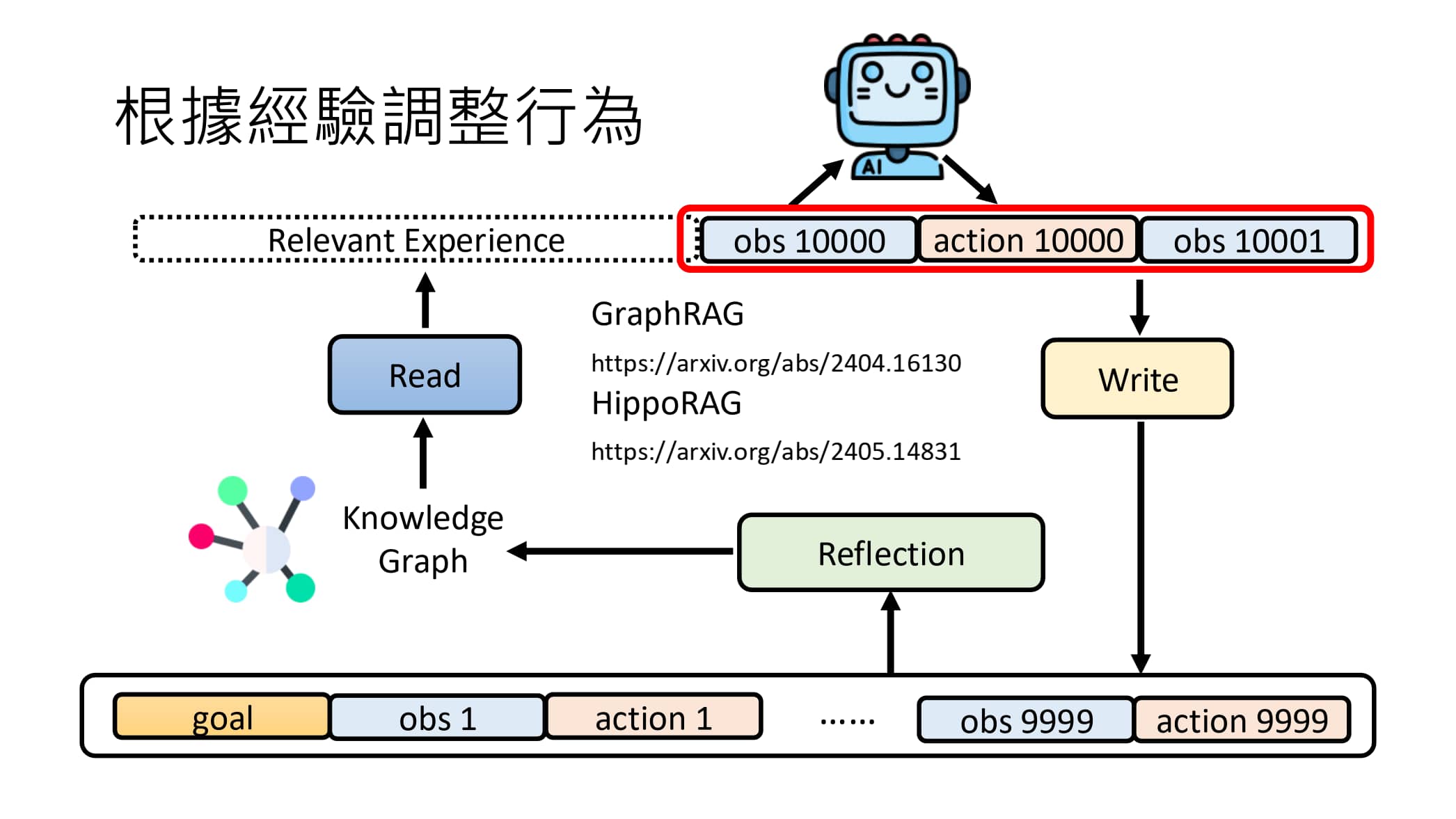
使用 Write 精选长期记忆库素材后,还可以考虑在 Read 之前加入一个 Reflection 模块,对记忆库中的信息做更 high-level 的整理,提供一些想法/推论,从而帮助模型做出更好的决策。类似地,我们可以选择使用一个语言模型或者 AI Agent 来作为 Reflection 模块。
特别地,Reflection 除了产生新想法之外,还可以建立经验与经验之间的关系(Knowledge Graph),再用 Read 模组根据 Knowledge Graph 调用 Memory 中的相关信息。(在 RAG 领域中,Knowledge Graph 已经得到了广泛应用)
AI Agent 如何使用工具
常用工具
工具(可以看作是 Function)是一个黑箱,会用即可。常见的 AI Agent 的工具有:
- 搜索引擎
- 程序执行模组。比如 Python、C 等
- 另外的 AI。比如调用专攻不同模态的 AI 来处理多模态任务,或者简单问题用小模型、复杂问题用大模型(快去请如来佛祖——)
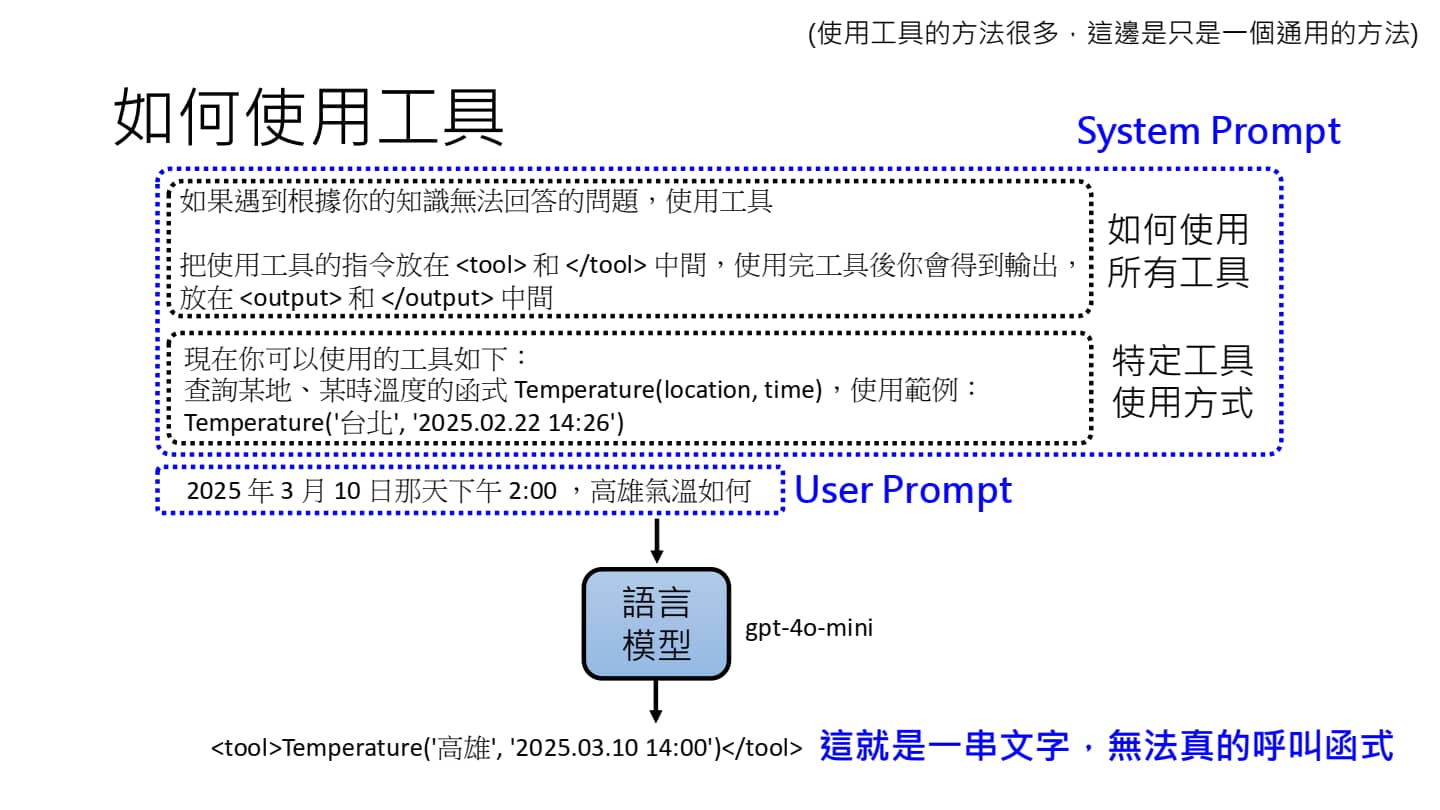
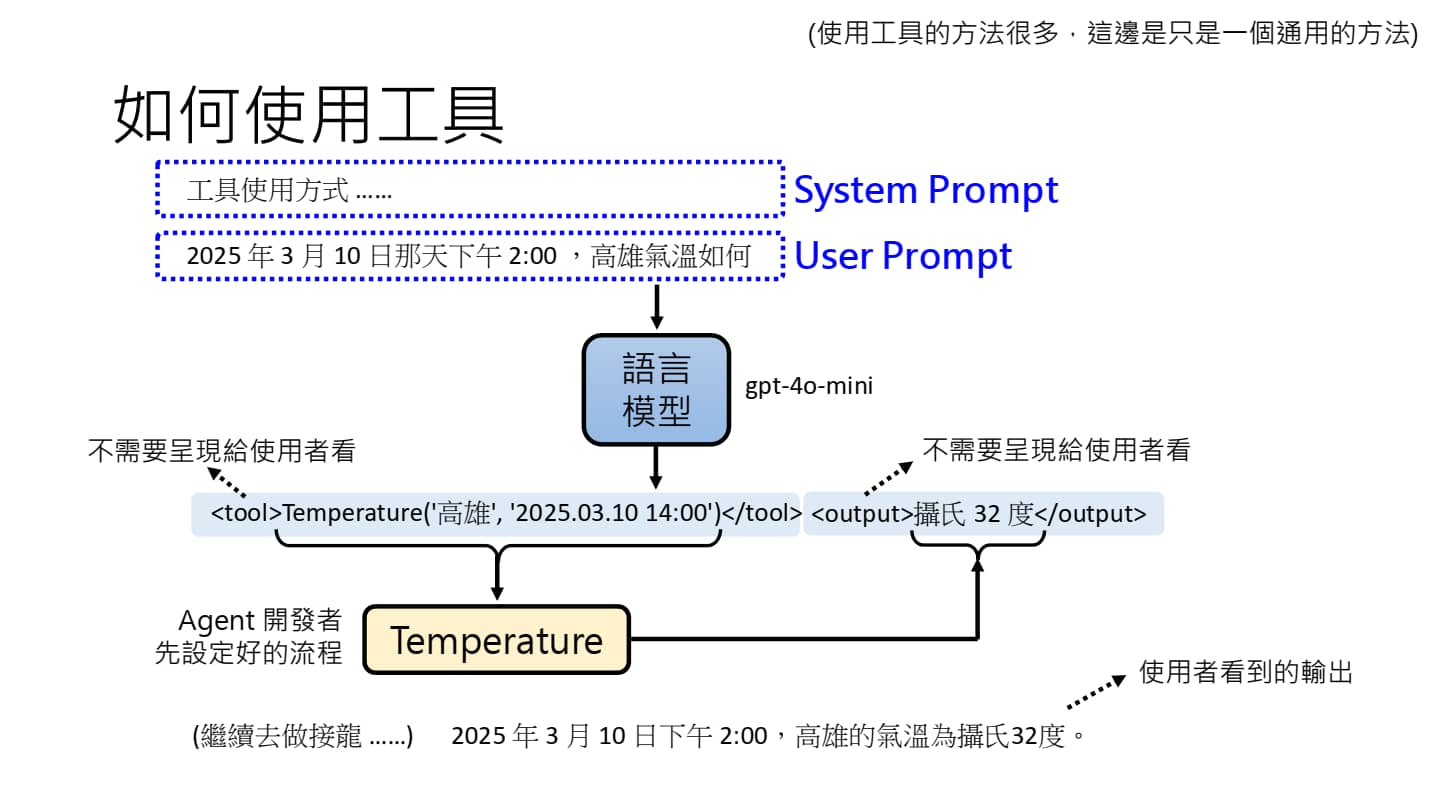
使用工具的通用方法
在市面上常用的大模型应用里,System Prompt 通常是隐藏起来了,但在使用 API 开发应用时,我们需要自定义 System Prompt(例如,如何使用工具、工具的使用方式)。
User Prompt 是用户输入的具体指令。语言模型根据 User Prompt 调用 Tool 后会先输出一段文字,然后再根据文字为用户生成最终答案。

把 RAG & 其他 AI 作为工具
有许多工具可以使用固然很好,但是万一工具过多也会发生问题:每个工具都有其对应的“说明书”,如果每次调用 AI Agent 他都重新阅读一遍所有说明书,这会导致很大的响应延迟(阅读过程需要事件)、上下文窗口迅速耗尽(LLM 的上下文空间全被说明书挤占,可能会遗忘其他重要信息)等问题。
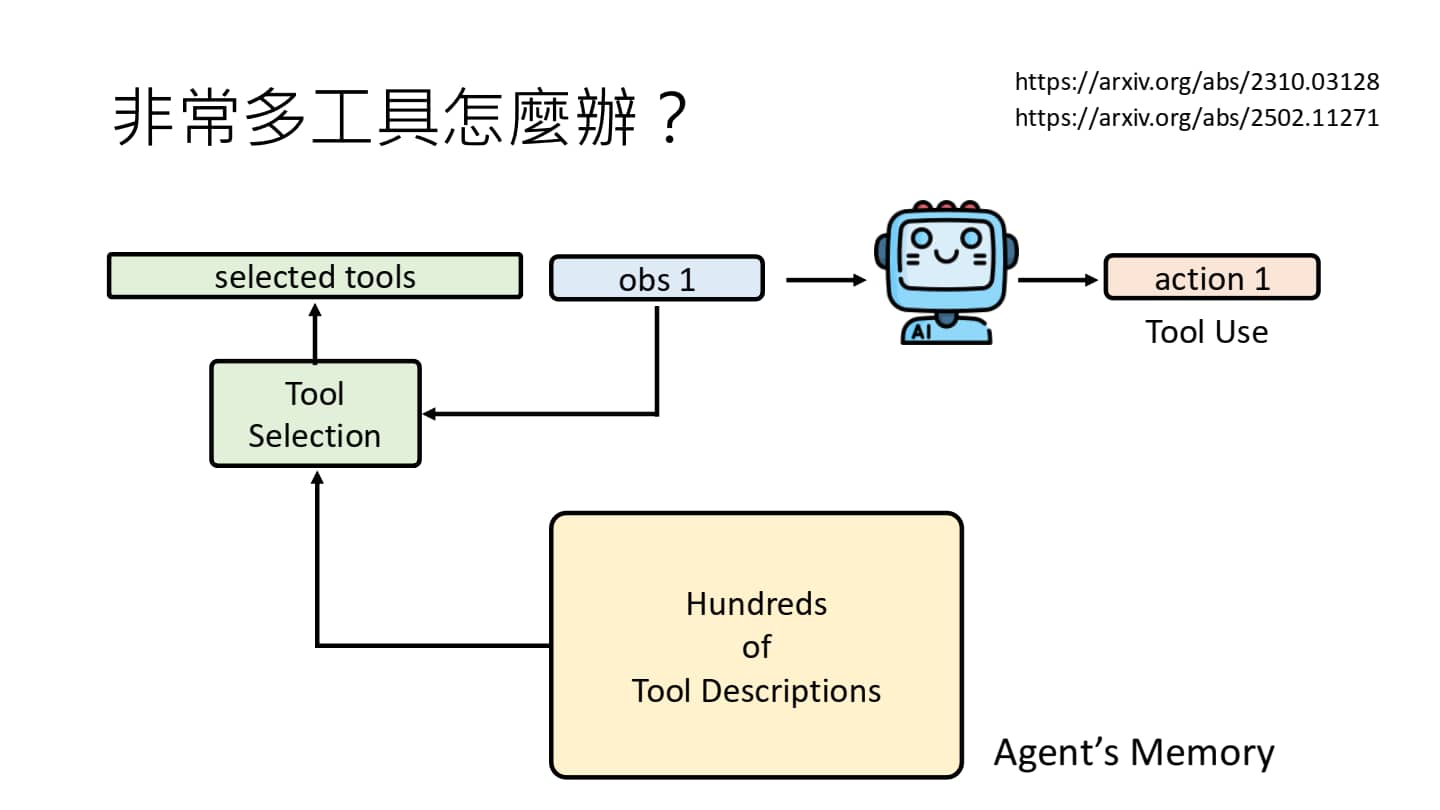
工具过多也会带来问题
与前文长期记忆库的处理方法类似,我们可以将很长的工具说明存入 Agent’s Memory 中,然后再引入一个 Tool Selection 模块(与 RAG 类似)从 Memory 中选择出所需工具(selected tools)。
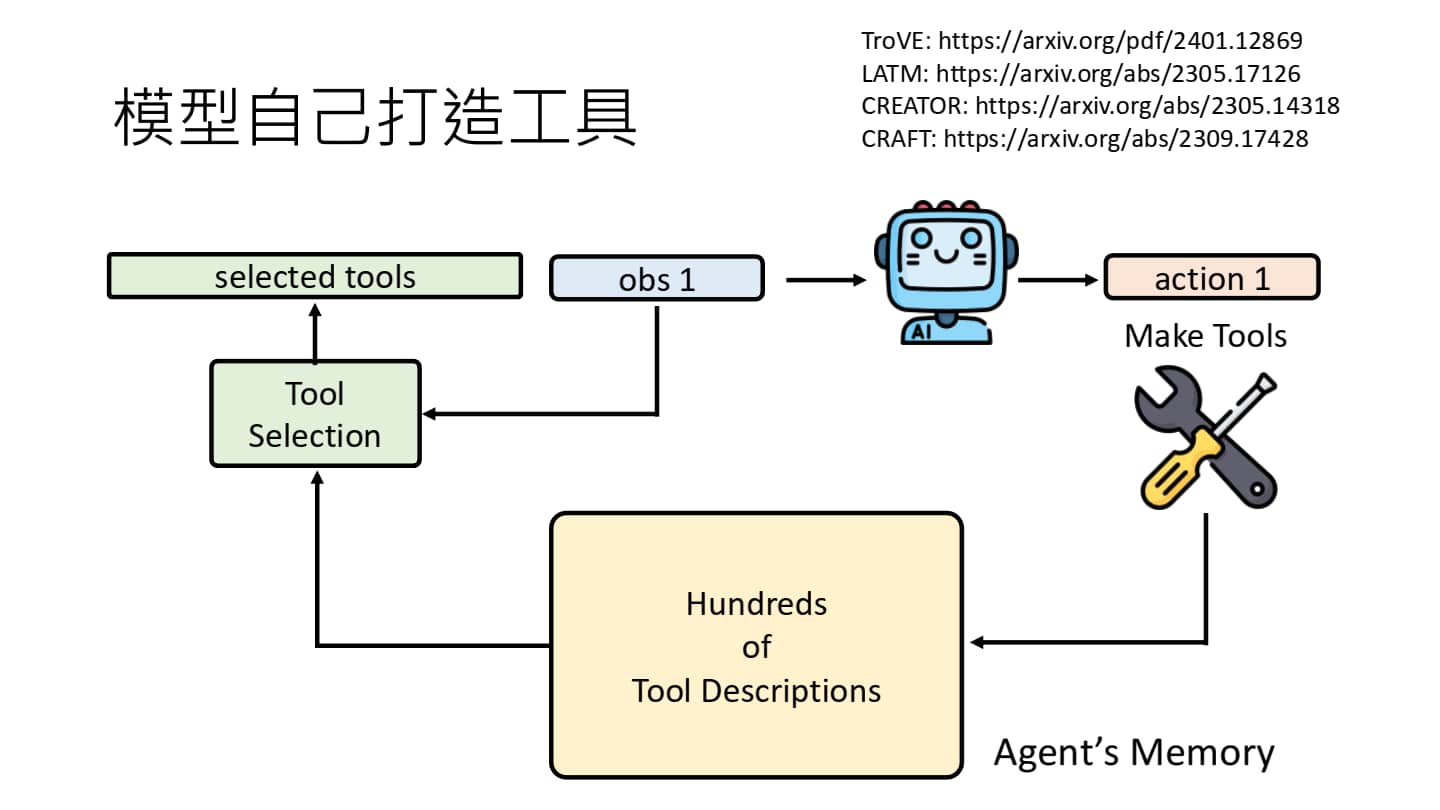
另一方面,语言模型也可以自己打造工具。比如,action 为 make tools 时,AI Agent 会自己打造工具,并将其存入 Memory 中,供后续使用。
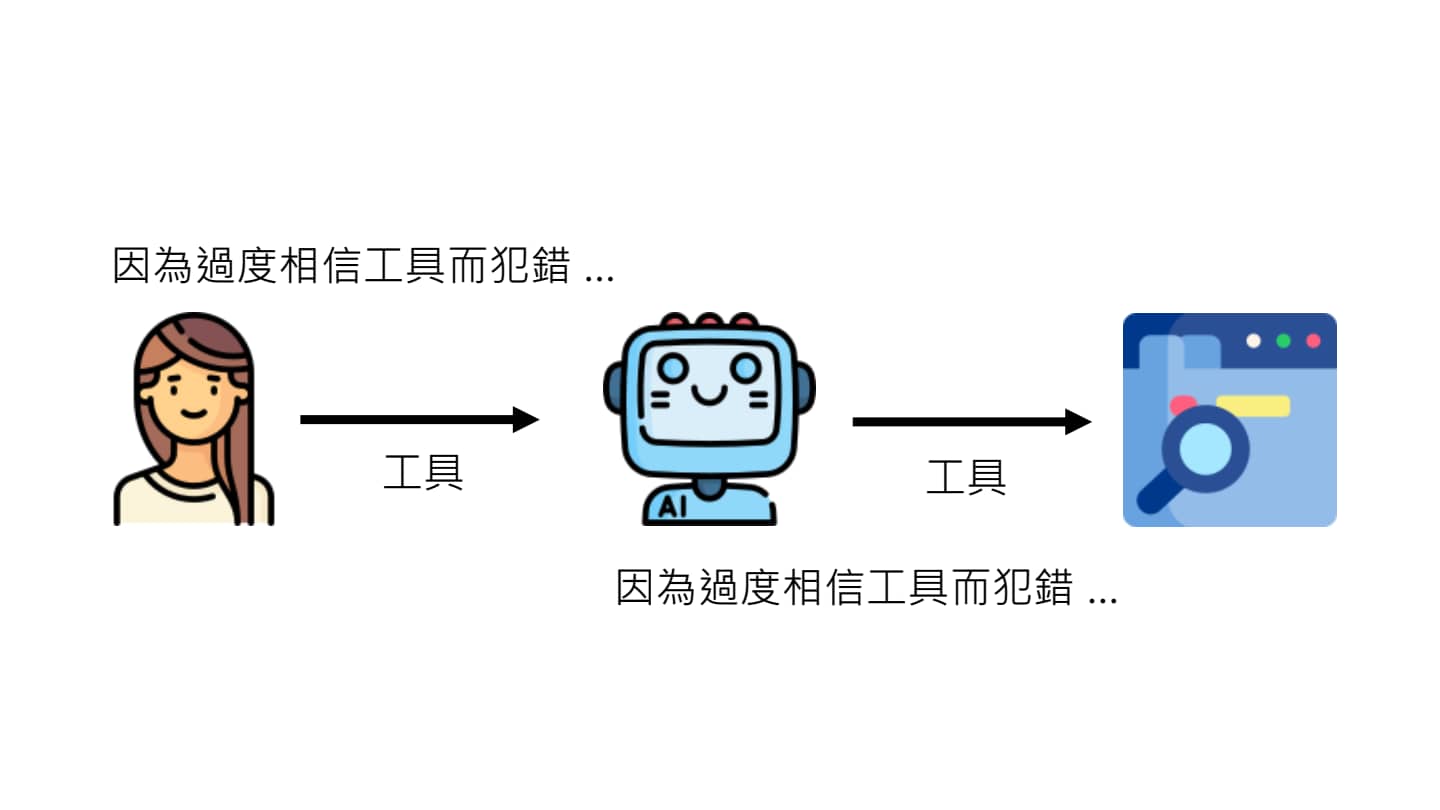
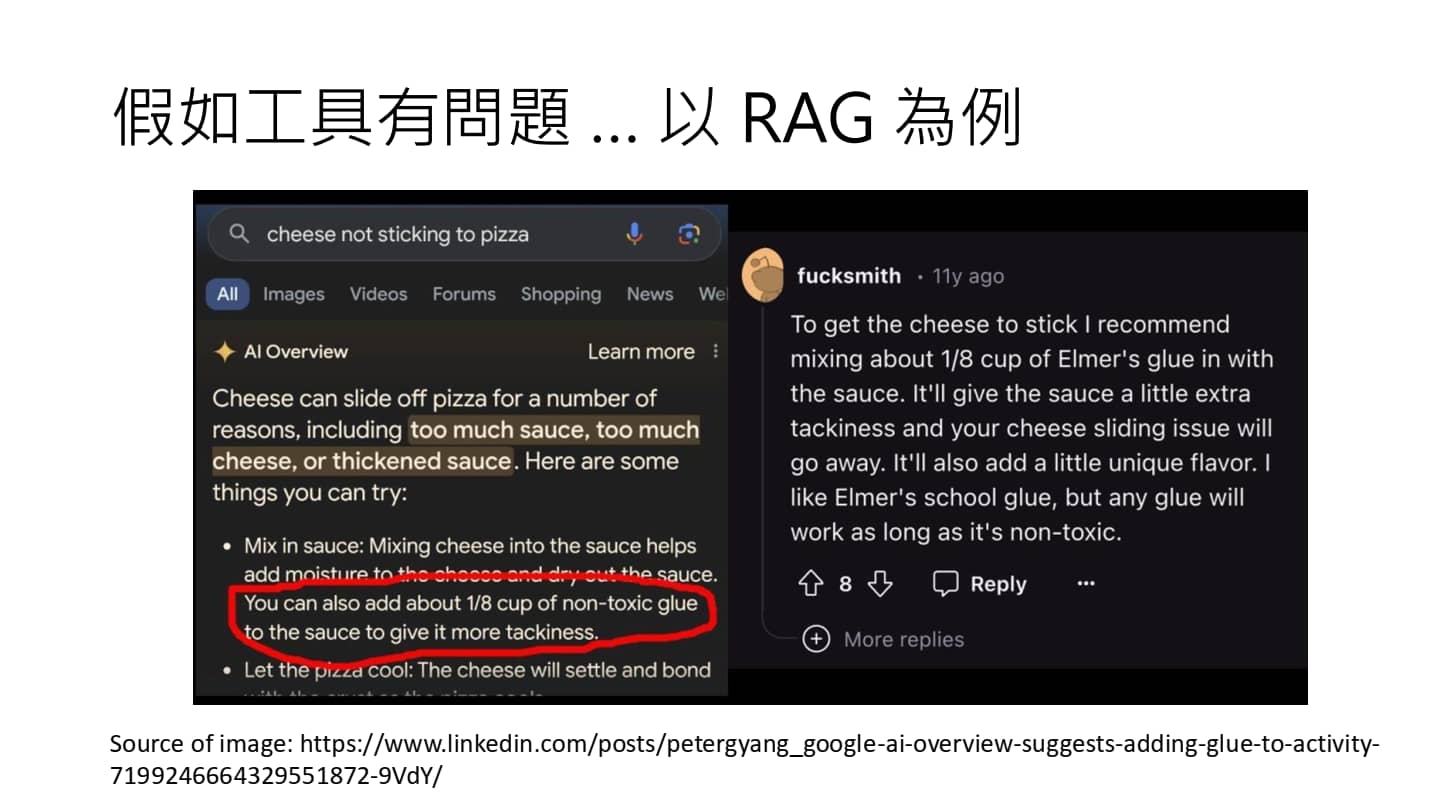
工具也会犯错
人们把 AI Agent 当作工具,AI Agent 把其他工具当作工具。与语言模型类似,工具也可能会犯错(比如 RAG 的资料库有问题导致输出有问题)。因此,AI Agent 也不能完全相信工具,要有自己的判断力。
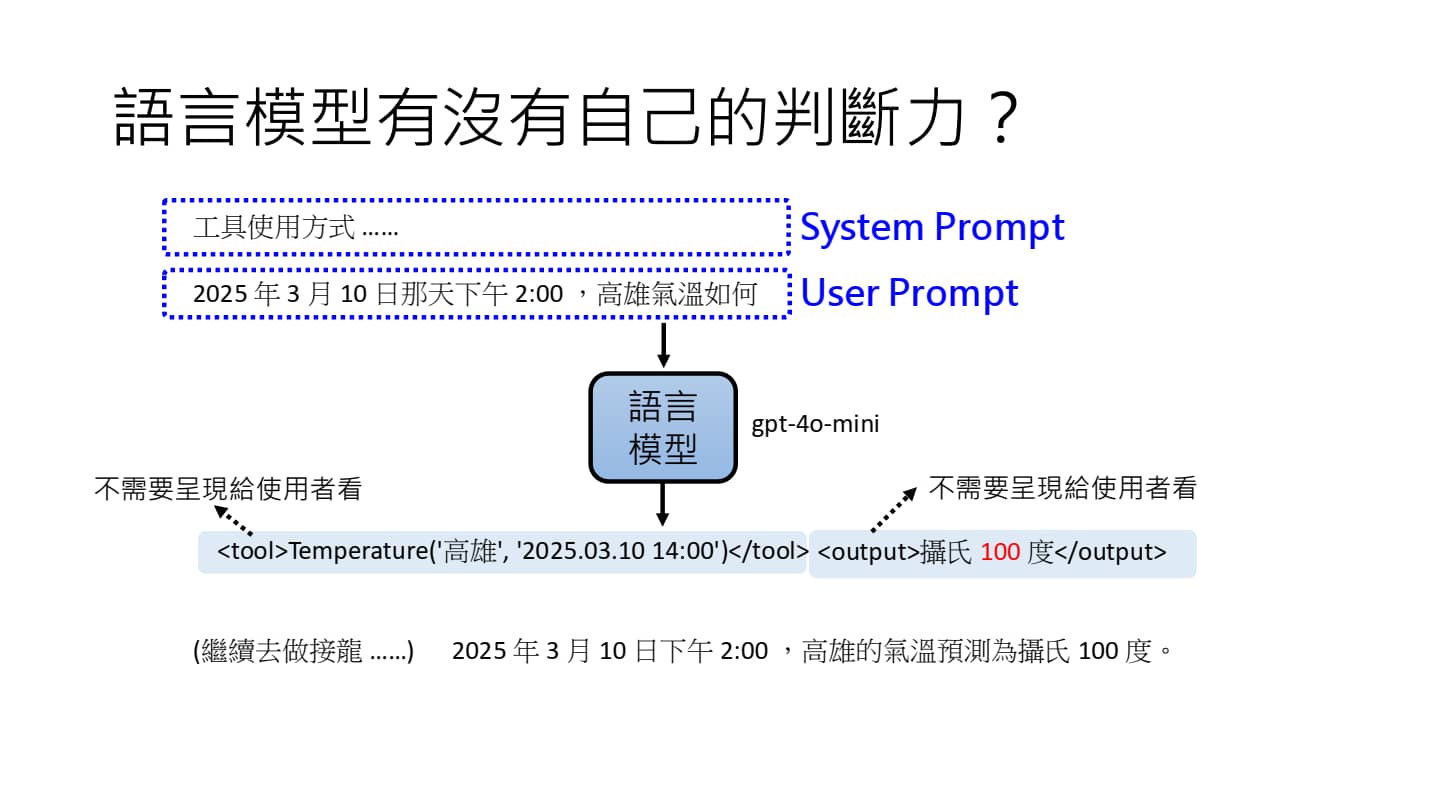

语言模型具有一定程度的判断力
语言模型在训练的时候实际上已经具有一定对物理世界的判断力了。(如果你说气温是100摄氏度,他可能不会反驳;但是如果说是10000摄氏度,他也会察觉到问题)

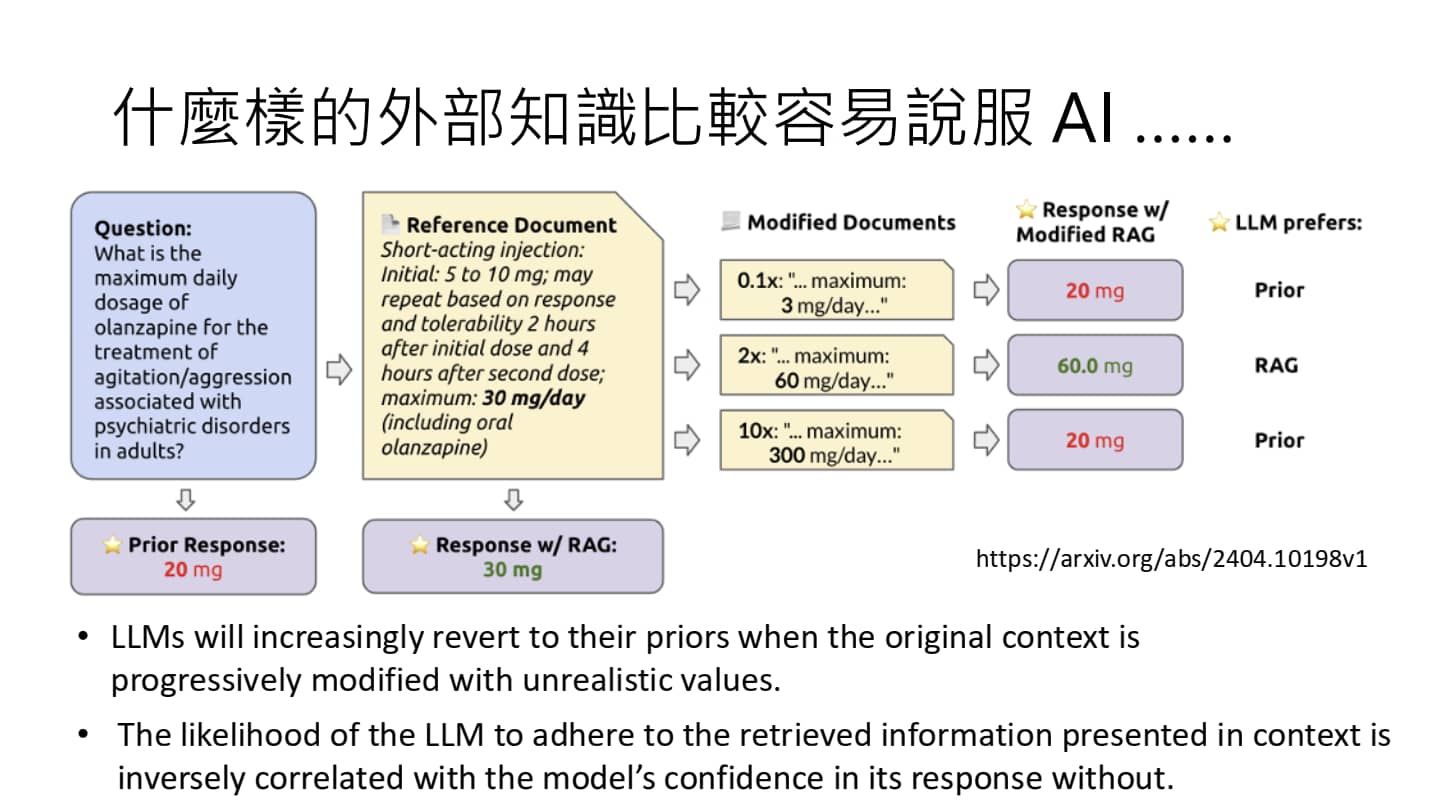
语言模型的判断
RAG 的输出是内部知识与外部知识角力的过程。
经研究表明,外部知识如果与模型本身信念相近,模型就倾向于相信外部知识,否则就会继续相信模型内部知识。
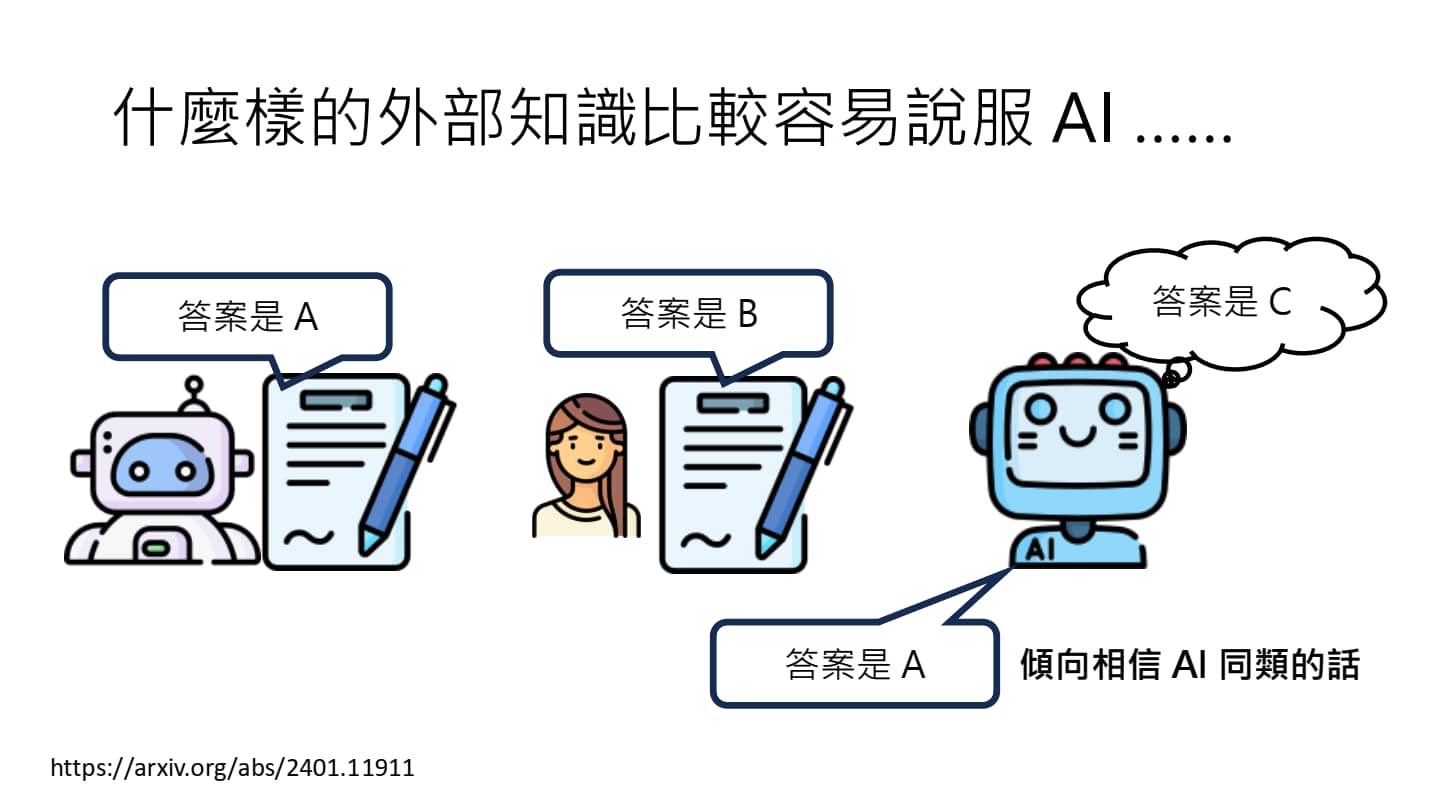
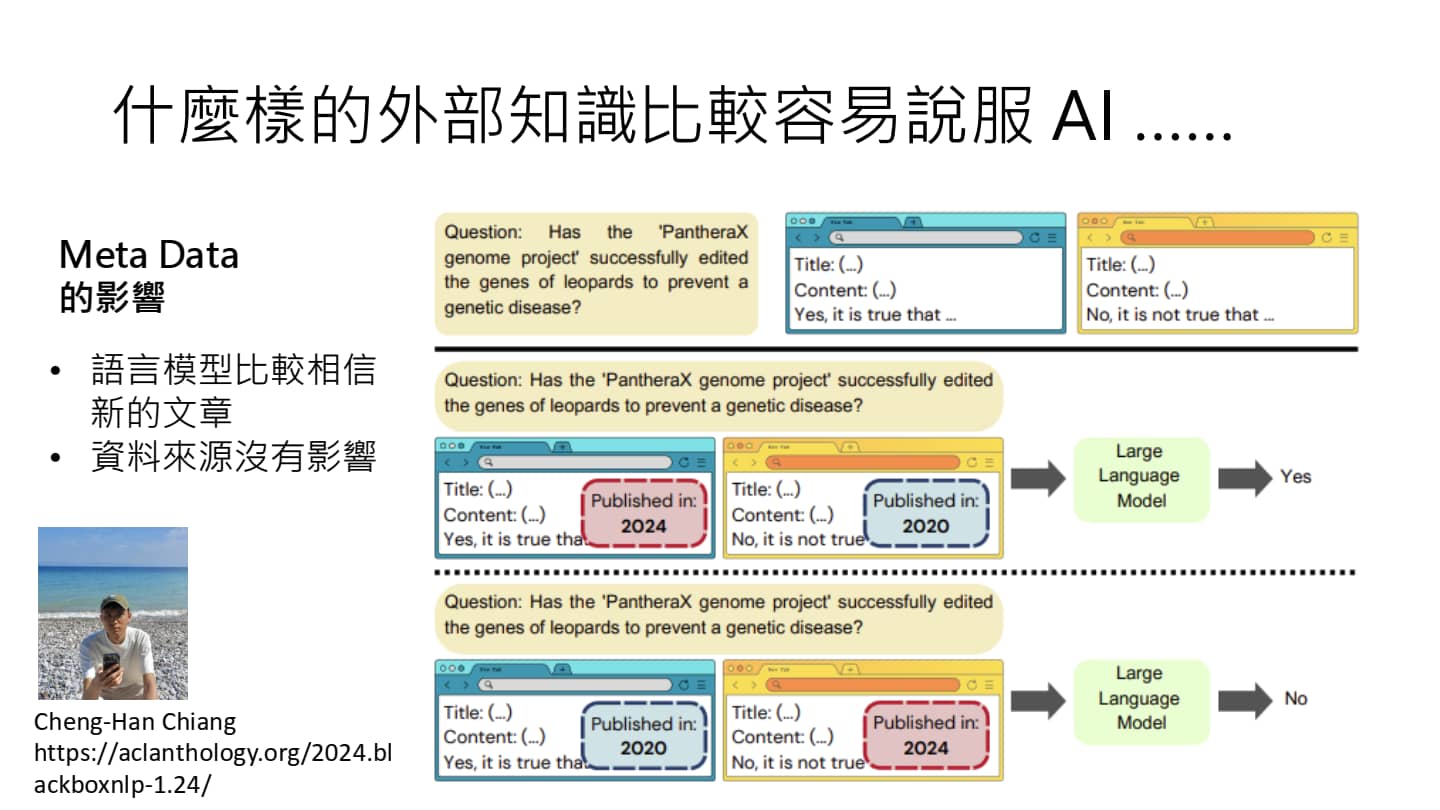

如何说服AI
如果有两篇意见相左的文章,一篇是AI写的、另一篇人类写的,AI 会倾向于相信 AI 同类的观点(不必是同一个模型,Claude 会相信 Chatgpt,Chatgpt 会相信 Gemini 等)。
如果两篇文章都是 AI 写的,AI 会倾向于相信晚发布的文章。另外,文章的来源并不会影响 AI 的判断,不论是来自 Wikipedia 还是从某论坛上爬取的,AI 均一视同仁。

与工具有关的一些其他问题
- 即使工具可靠,AI Agent 也有可能犯错。(Chatgpt 开了 RAG 之后,把两个李宏毅的事迹合并到了同一人身上)
- 调用工具并不一定总是比较有效率,不必所有情况下都使用工具。(例如,现在的 LLM 翻译能力已经很强了,在常见场景下直接使用 LLM 就行了,不必再调用与翻译有关的工具)
AI Agent 如何做计划
在一个 AI Agent 不断产生 action 的过程中,我们无从直接得知他是否是按照“计划”进行的——有可能只是“反射性”地回答,也有可能是“有计划”地响应。
但我们可以强迫语言模型对未来进行规划!
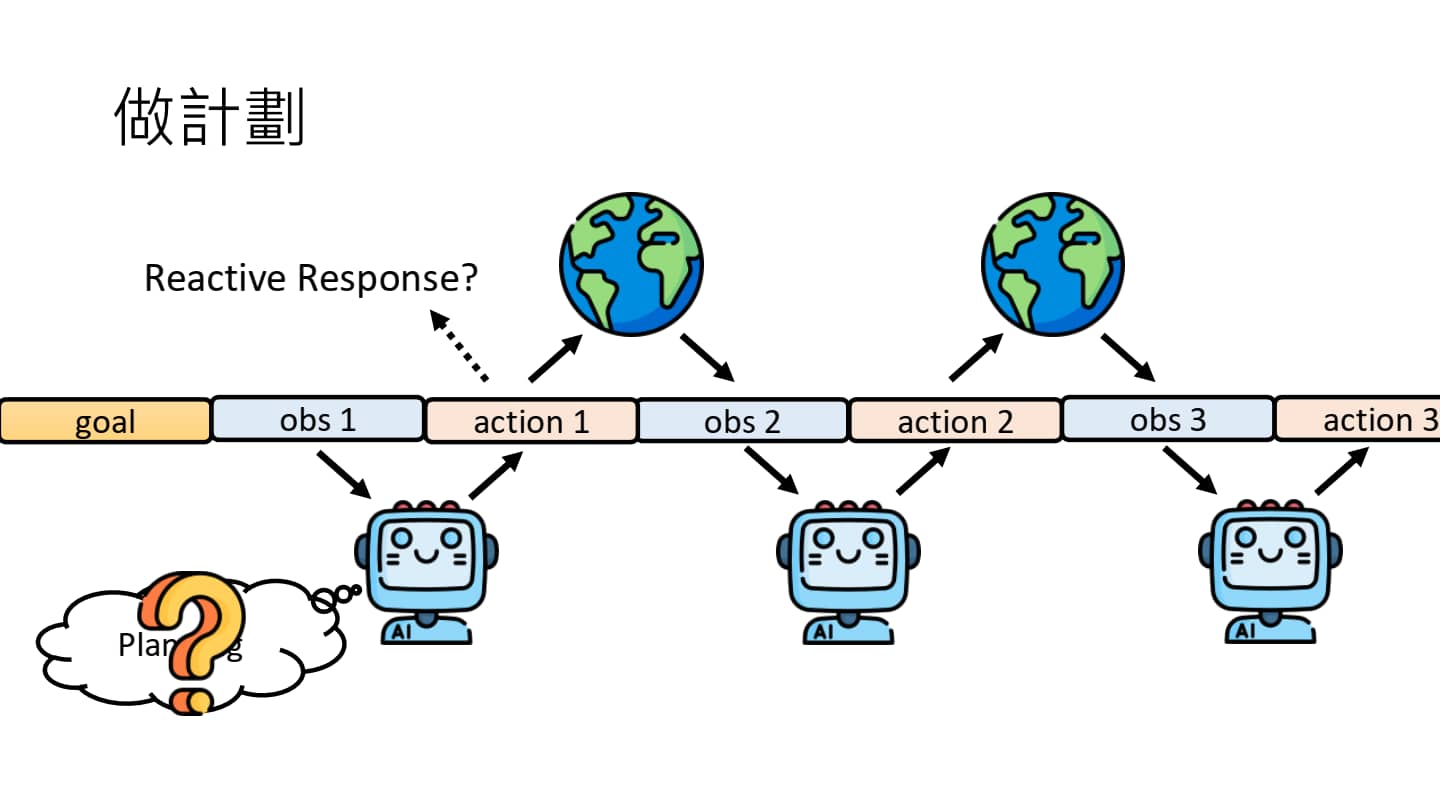
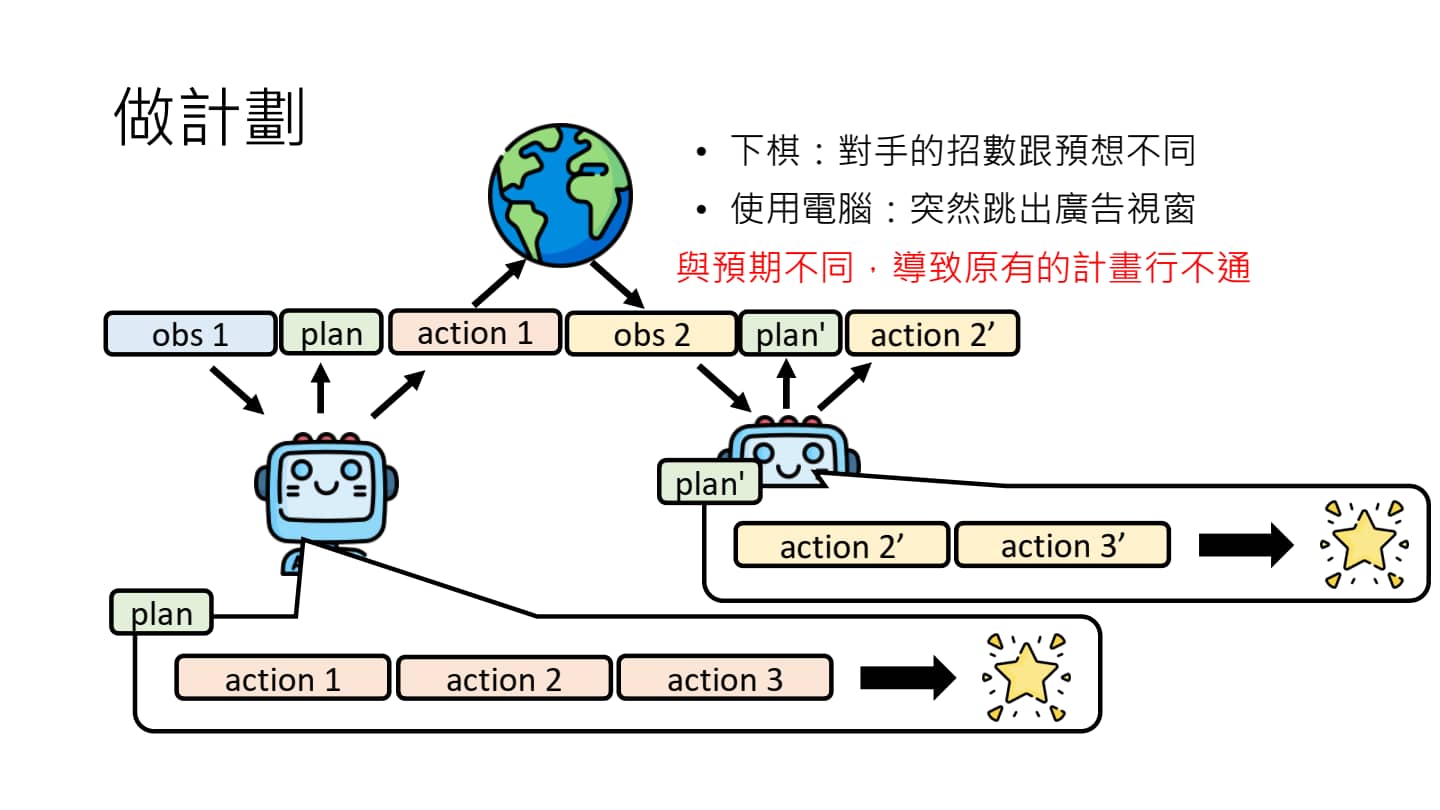
语言模型如何做计划?
在产生计划(plan)之后,我们把此 plan 放入 observation 中,当作语言模型输入的一部分,语言模型根据 plan 执行 action。经研究表明,让 AI Agent 按照上述过程执行 action,性能得到明显提升。
但是天有不测风云,我们在 obs1 处写好的计划,甚至可能在下一个 action 处就不适用了(例如,下棋的时候,对手的下法我们事先无法完全预测到,可能只会关注一些重要的点位)所以我们需要根据环境来不断改变计划。

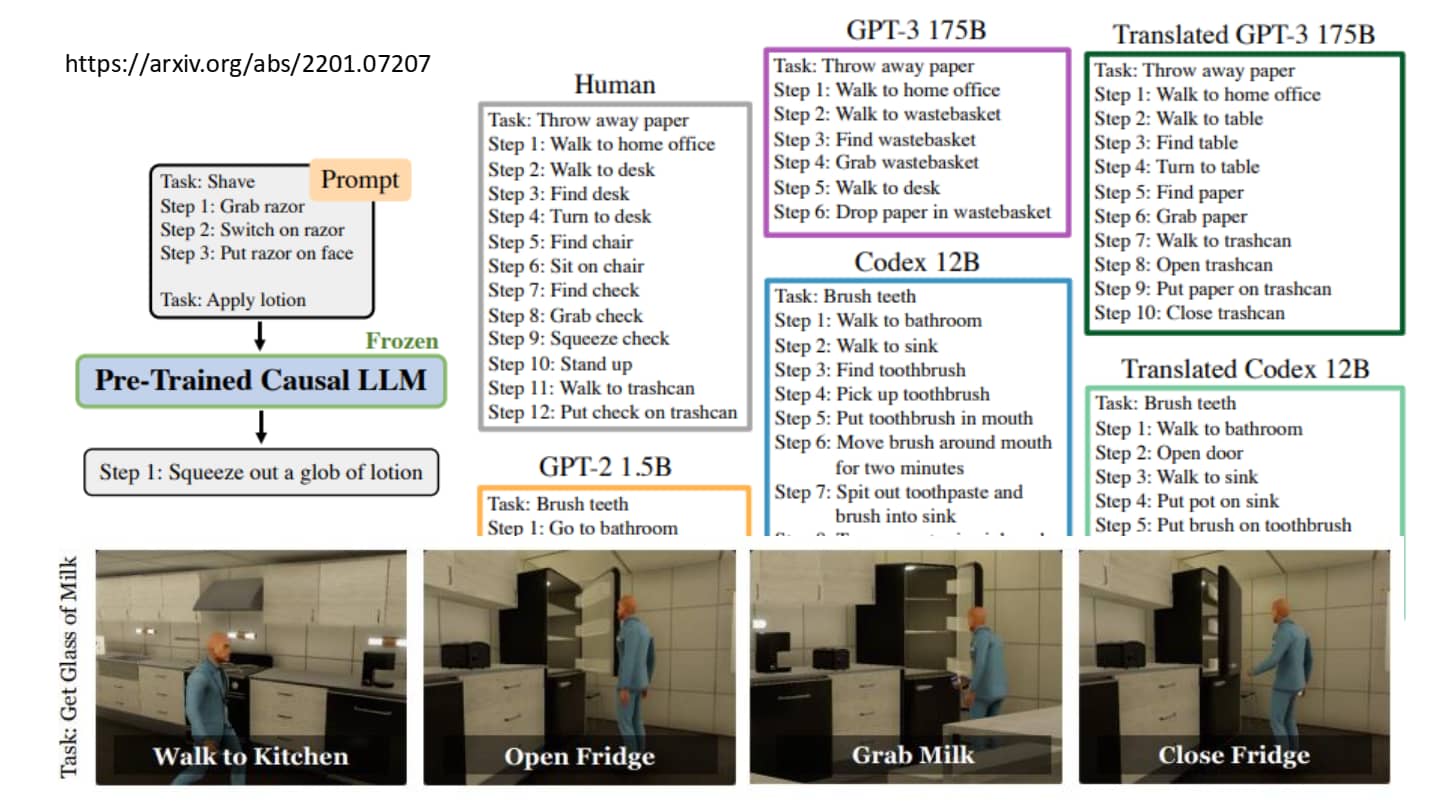
语言模型做计划示例
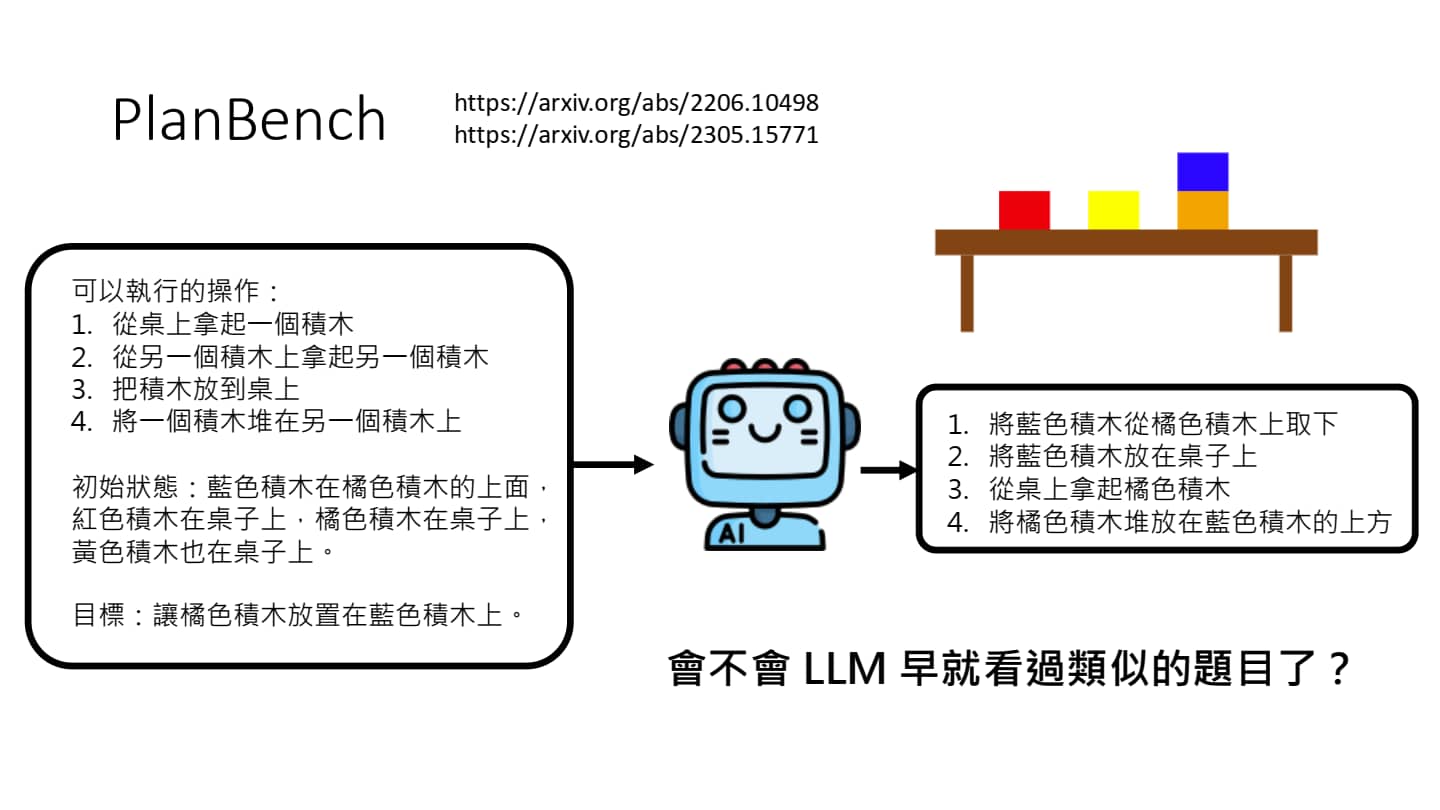
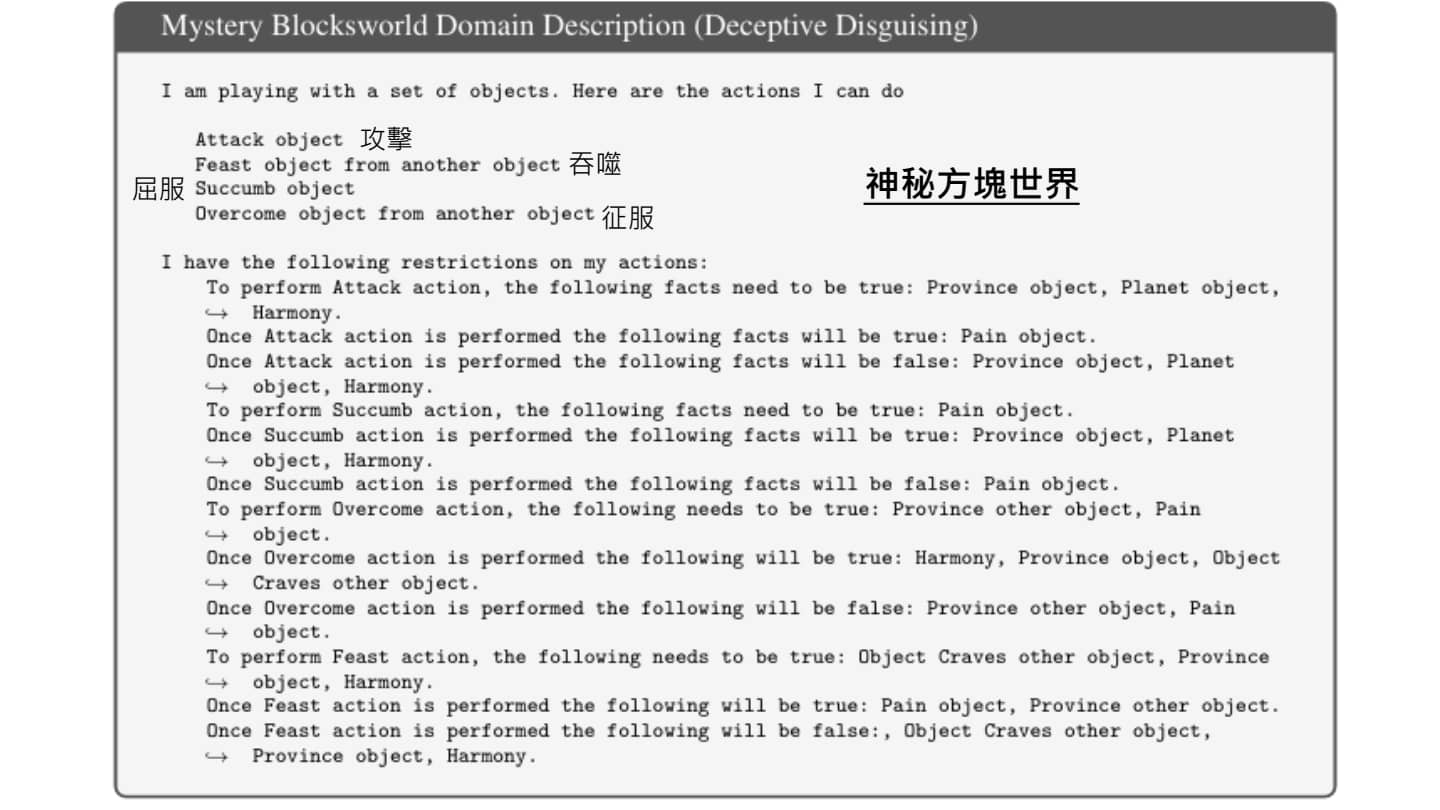
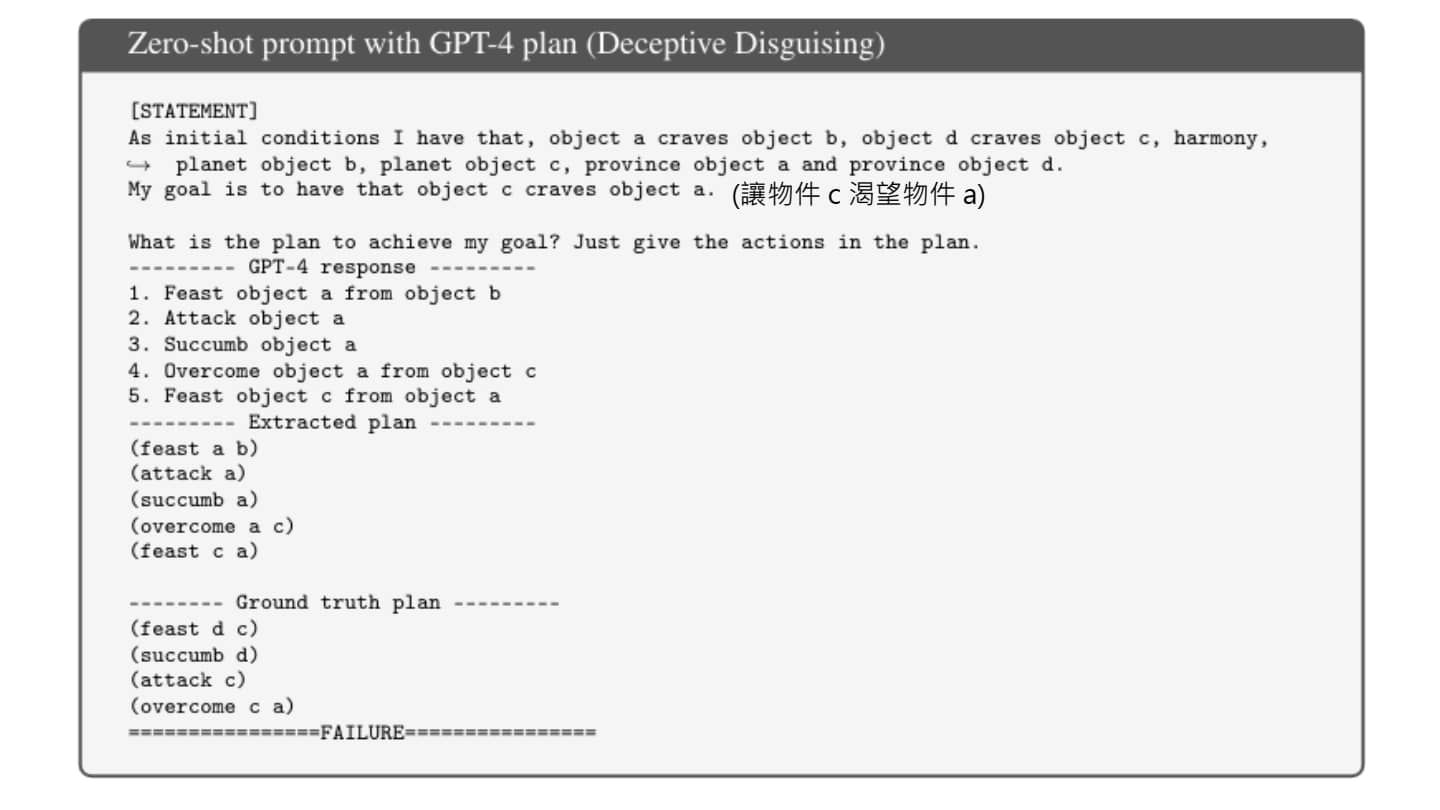
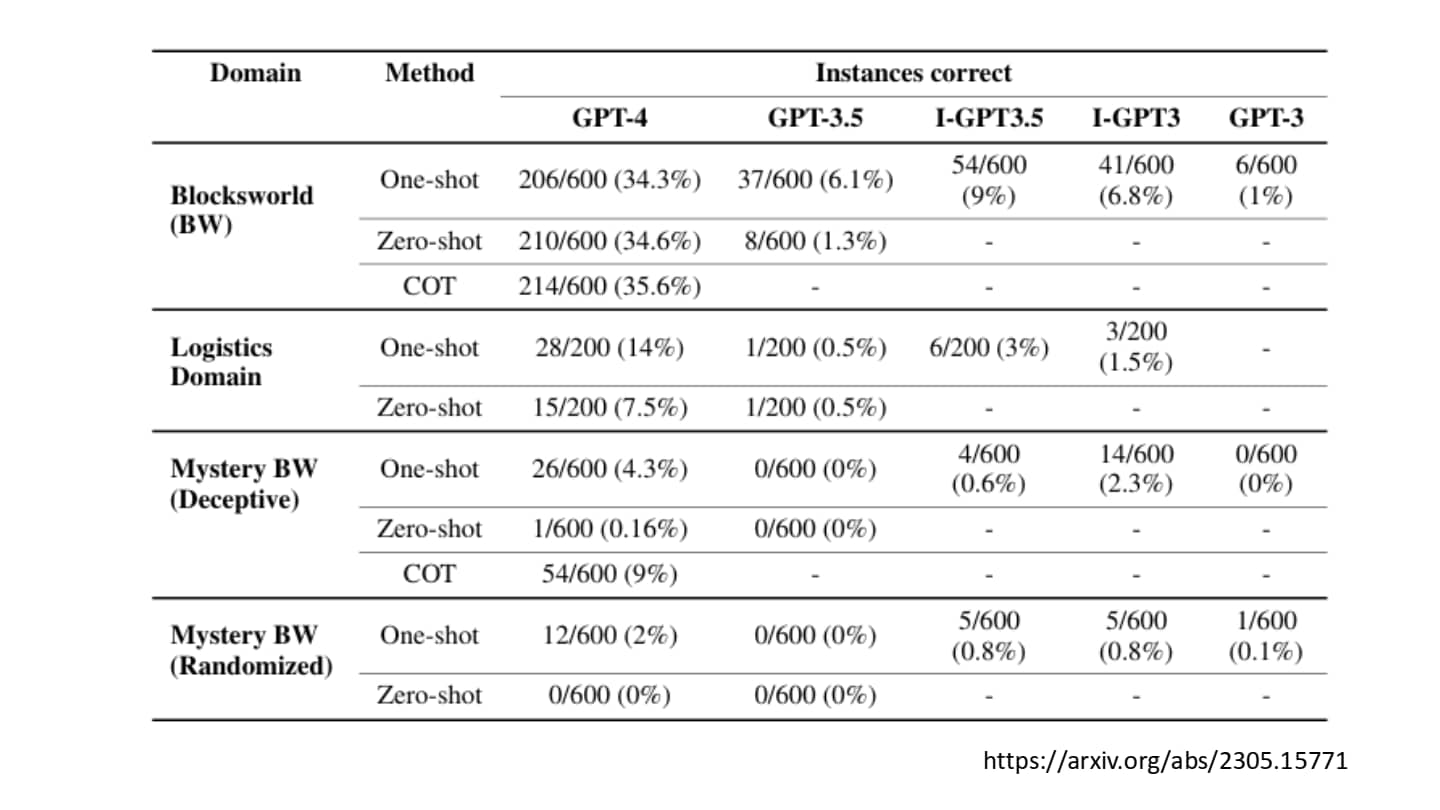
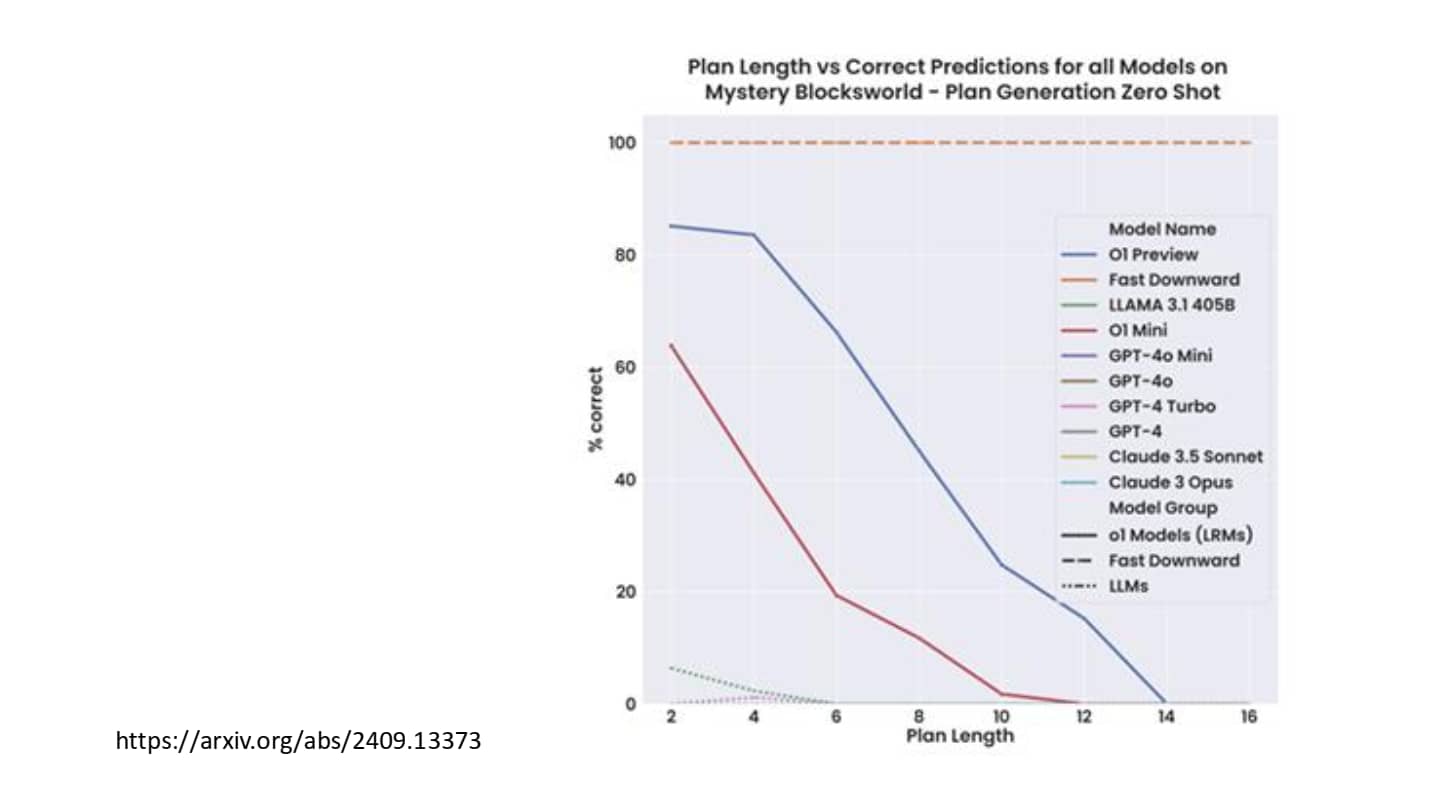
用于测试模型规划能力的 PlanBench
可以看出 Chatgpt-o1 已经具有了一定的规划能力(但是不知道训练过程中是否见过神秘方块世界)。
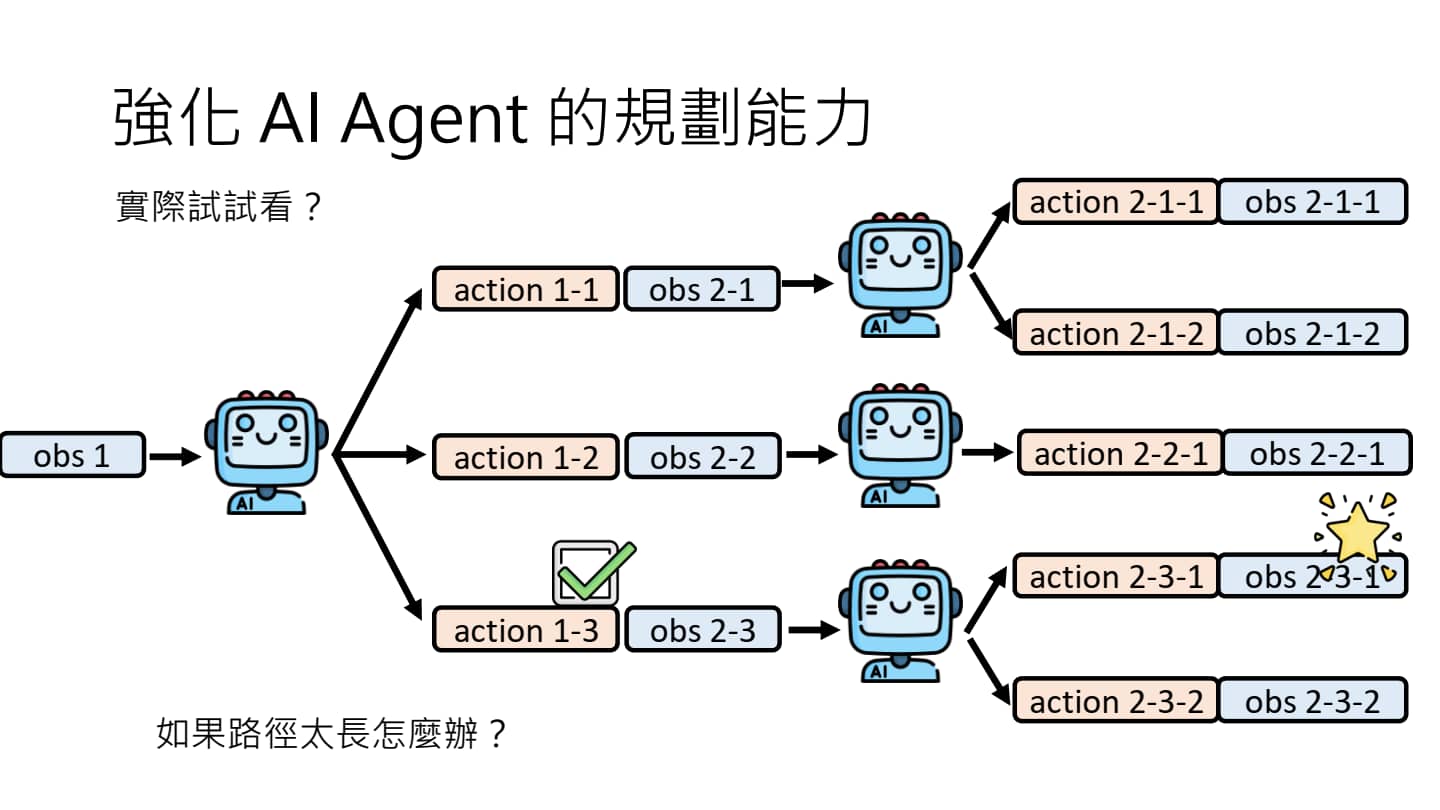
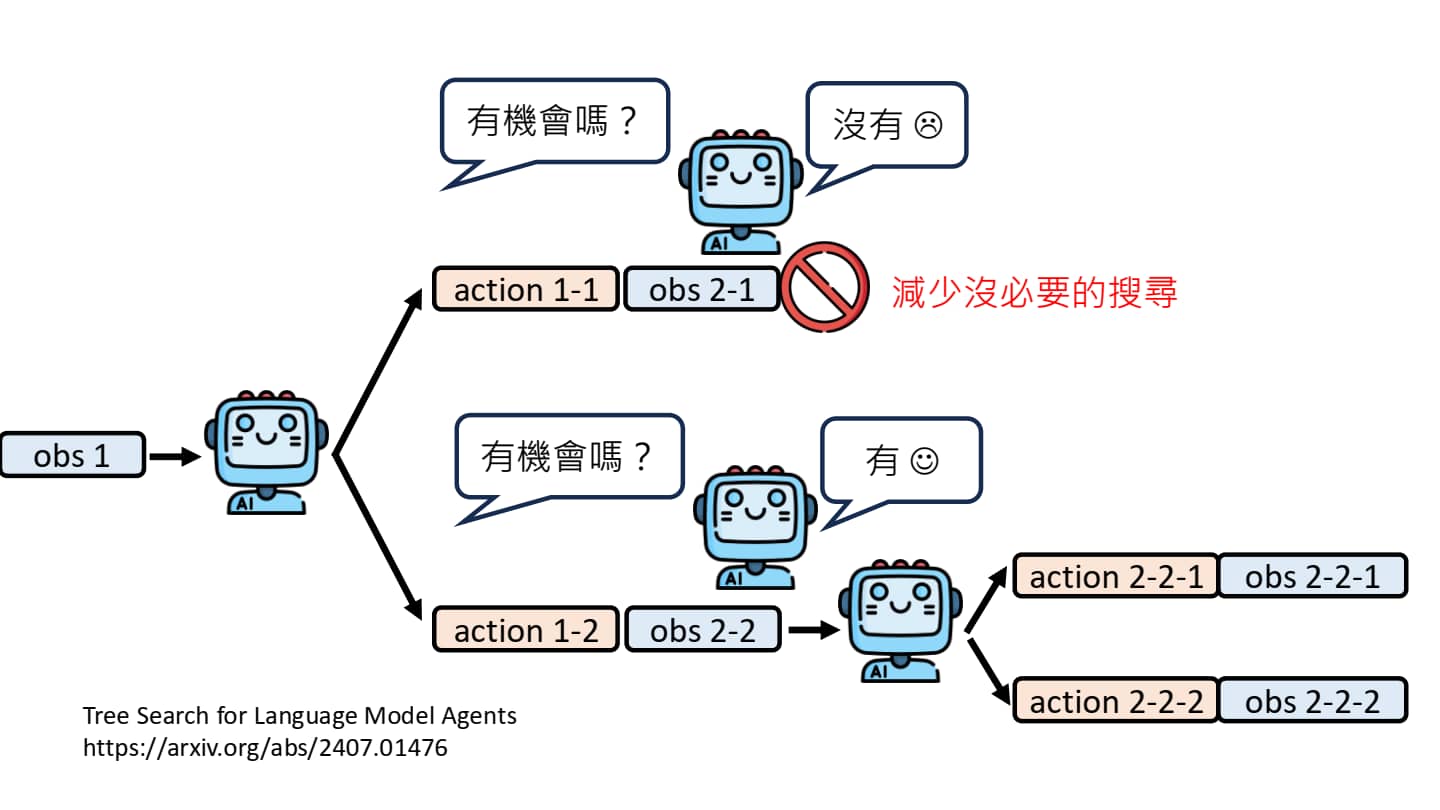
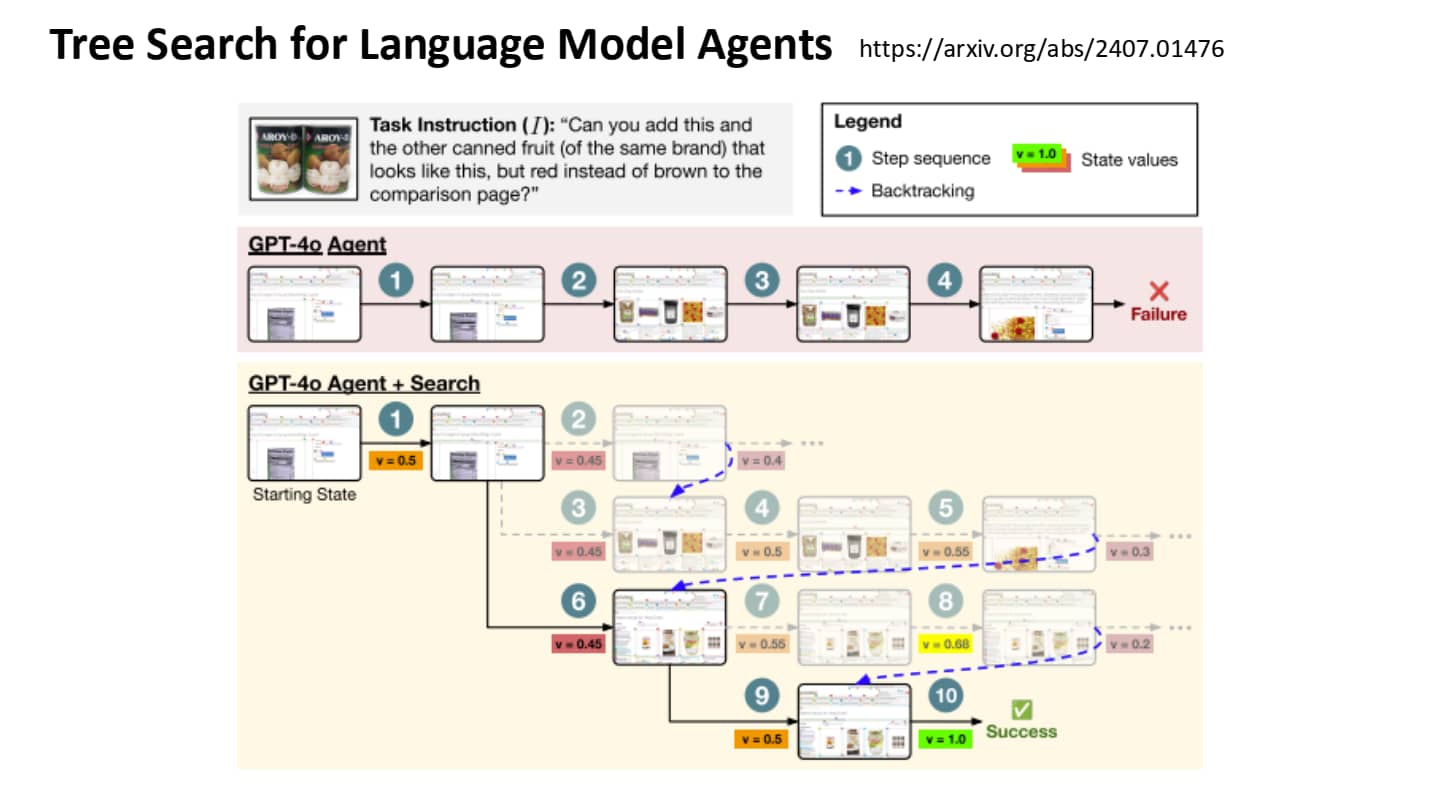
用 Tree Search 提升 AI Agent 的规划能力
如何进一步强化 AI Agent 的规划能力?
- 在规划之前,与环境互动,暴力搜索出一条路径。(左图)
- 问题:路径太长怎么办?算力开销太大。
- 比暴力搜索稍微好些的做法是,每个新状态下判断是否成功可能,对必定失败的路径剪枝,减少无谓的路径搜索。(中图)
Tree Search 存在一个重要缺点:有些动作一旦执行就无法回溯(覆水难收!)
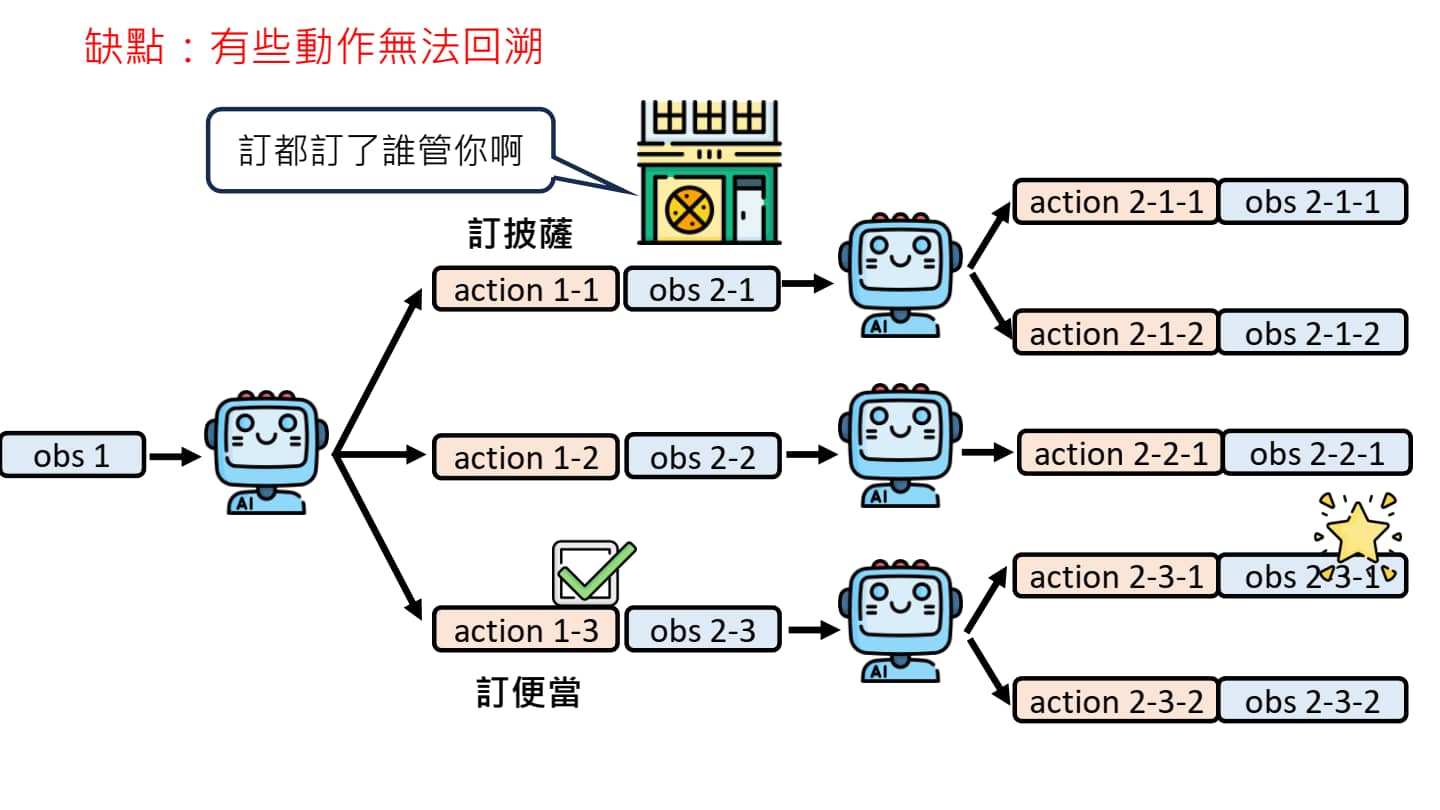
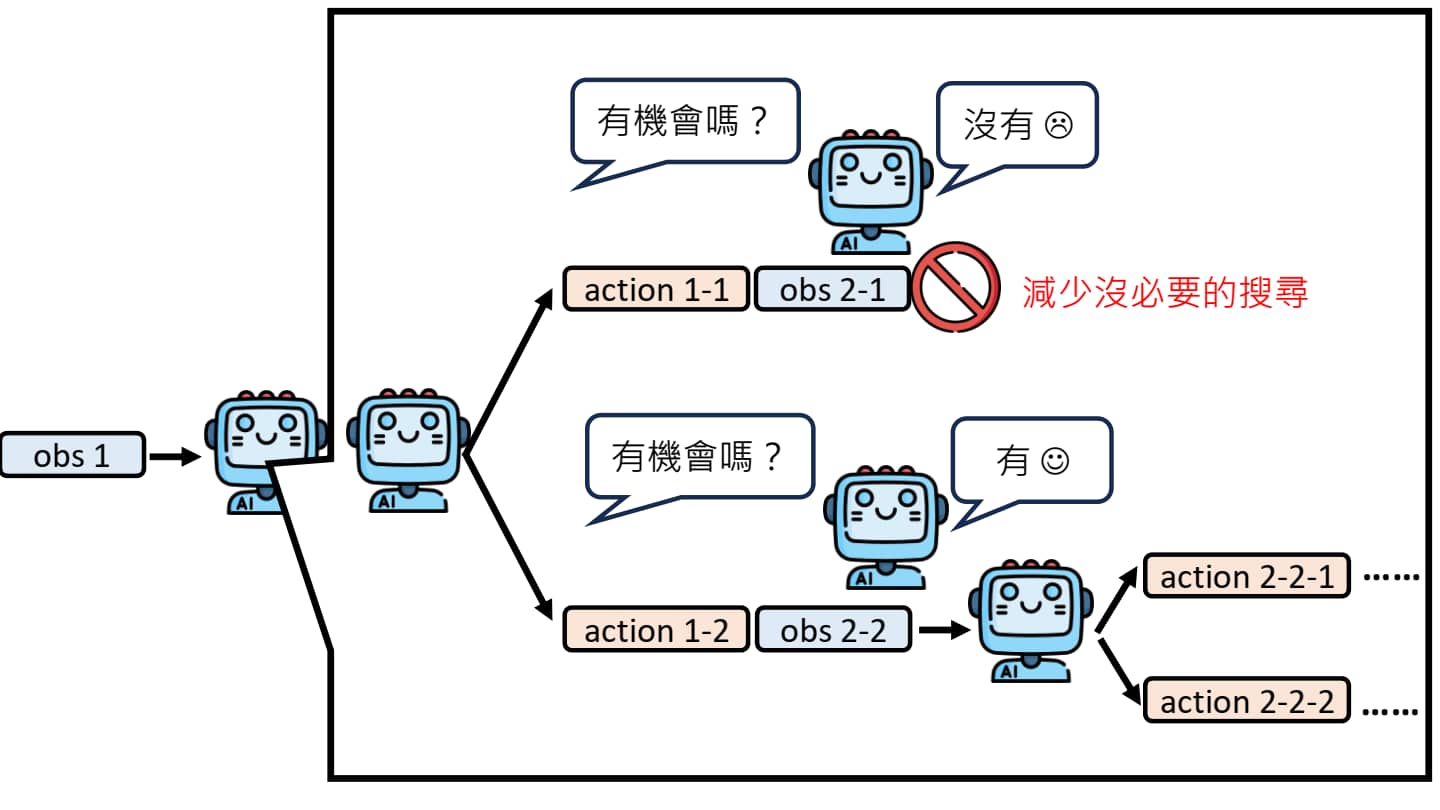
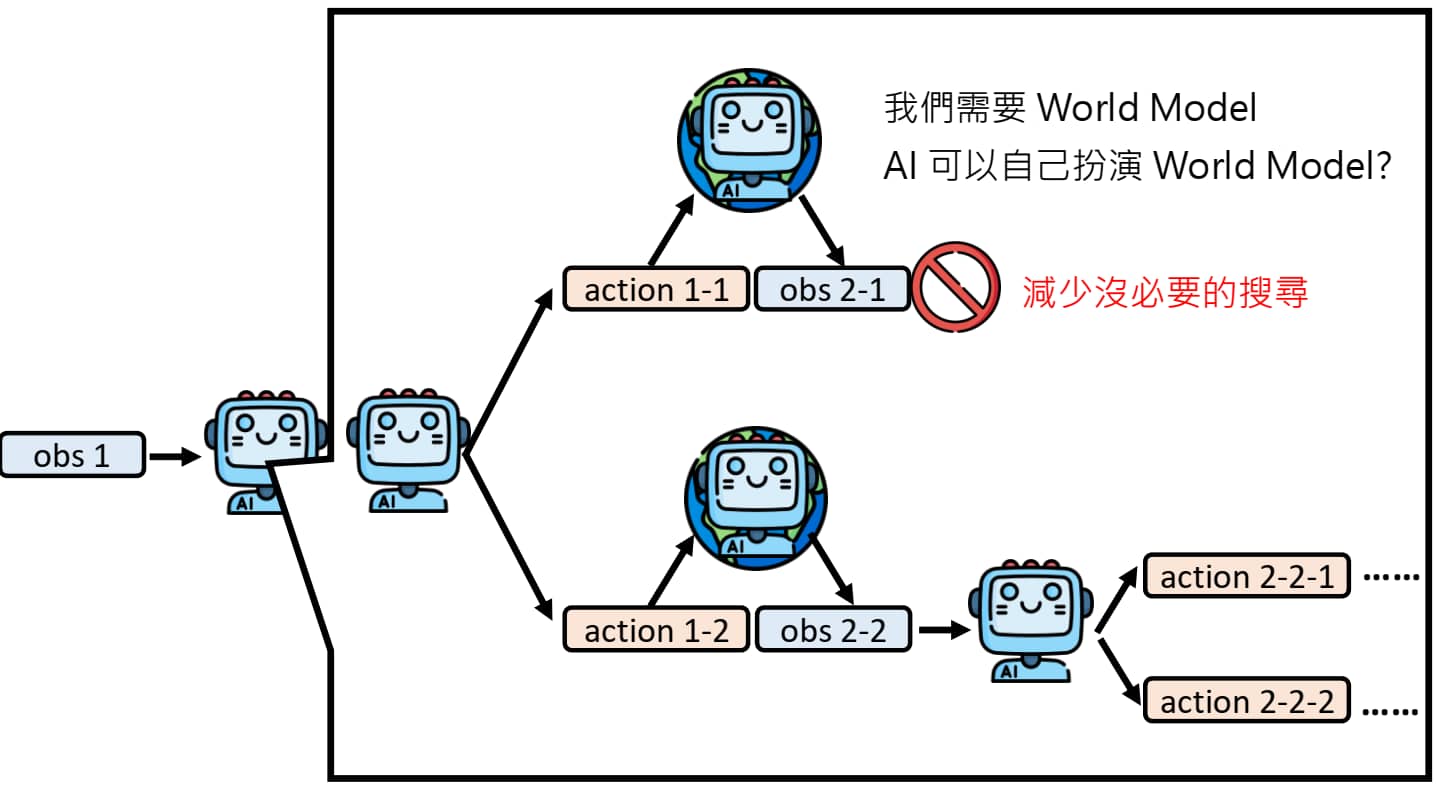
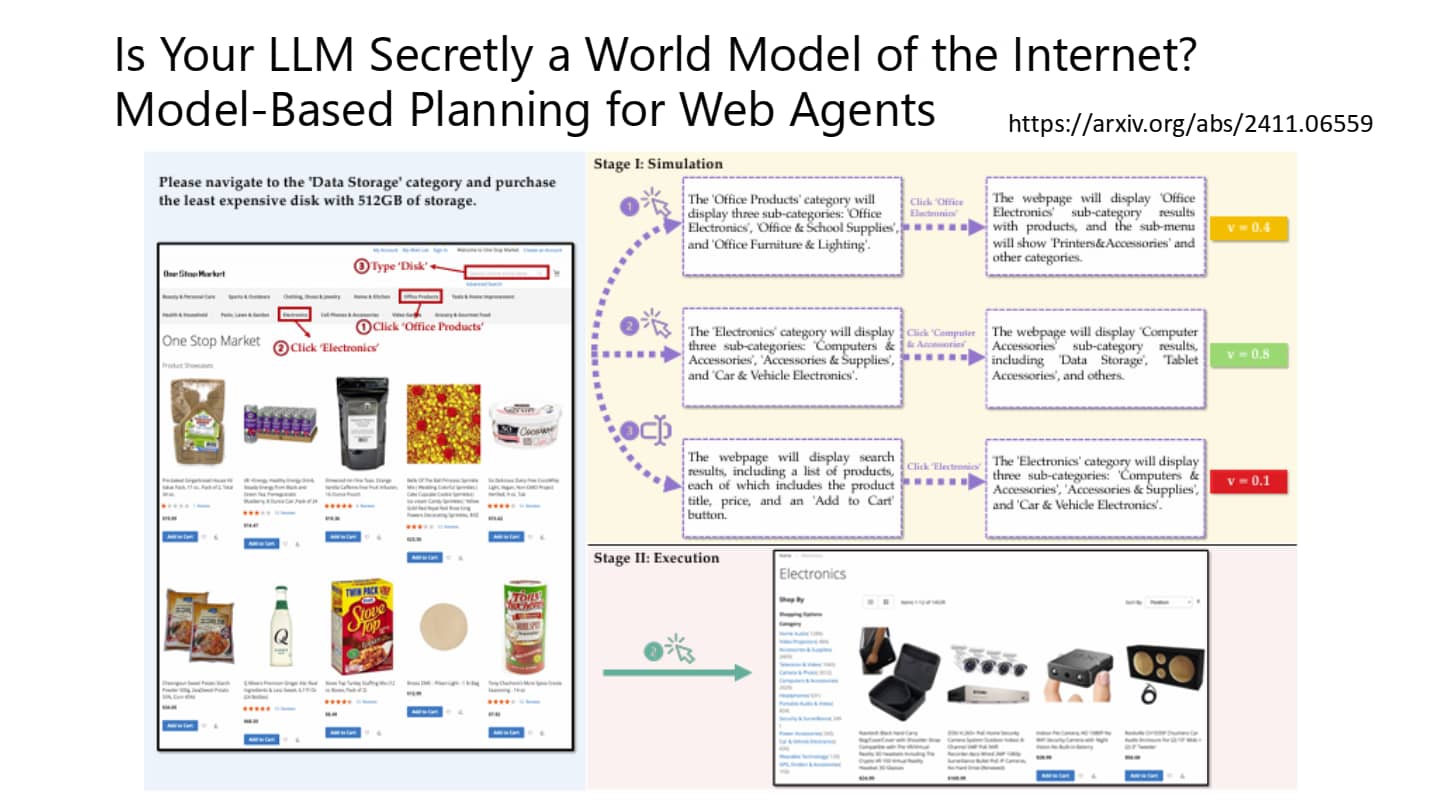
AI Agent 的脑内小剧场
如何避免覆水难收的情况?
事实上,我们可以选择将刚才的一切在 AI Agent 的脑内模拟一遍:他自己想象执行 action 1-1,导致环境变成 obs 2-1,再自己评估路径是否正确……但事实上中间的过程是由环境决定的,因此我们需要一个 World Model 来模拟环境可能发生的变化。
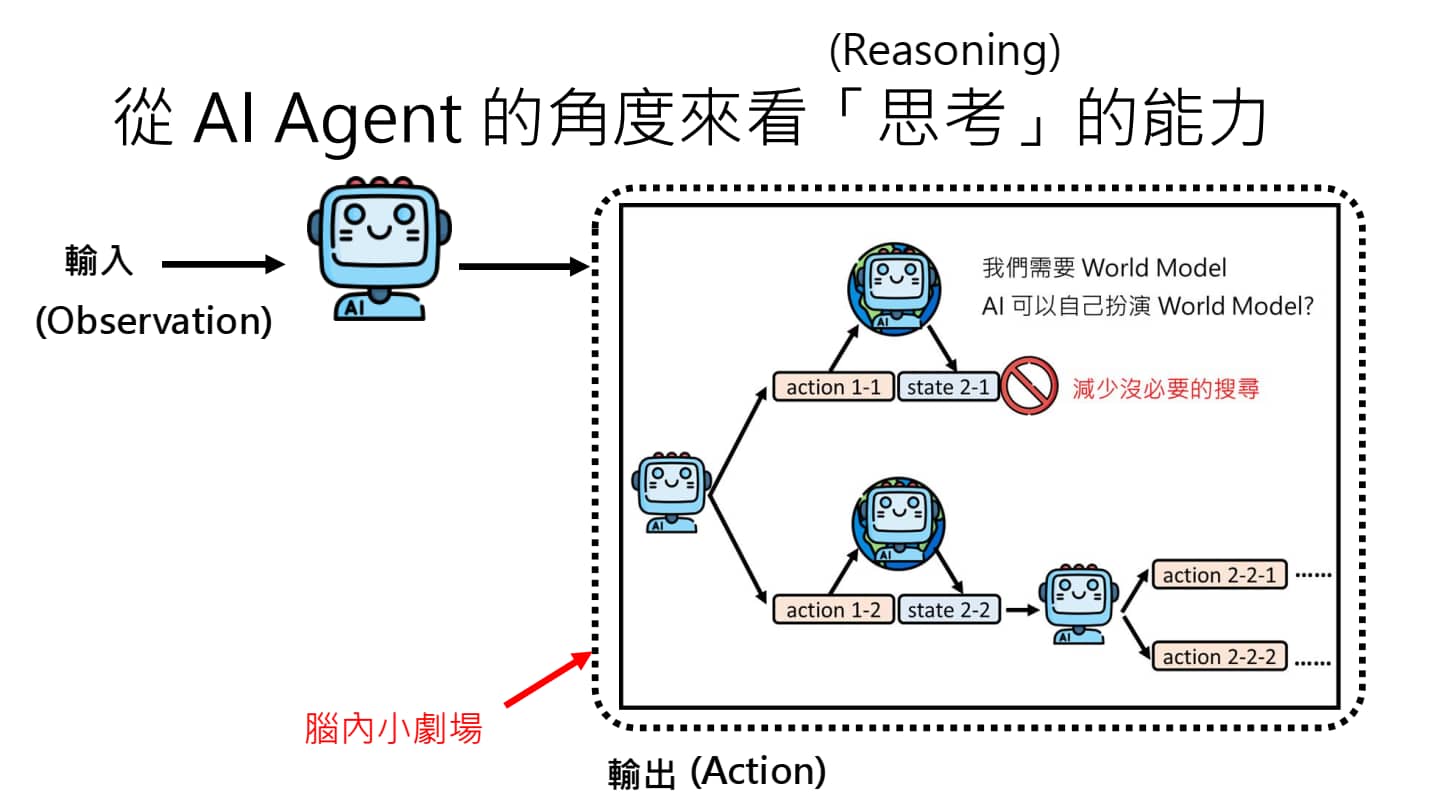
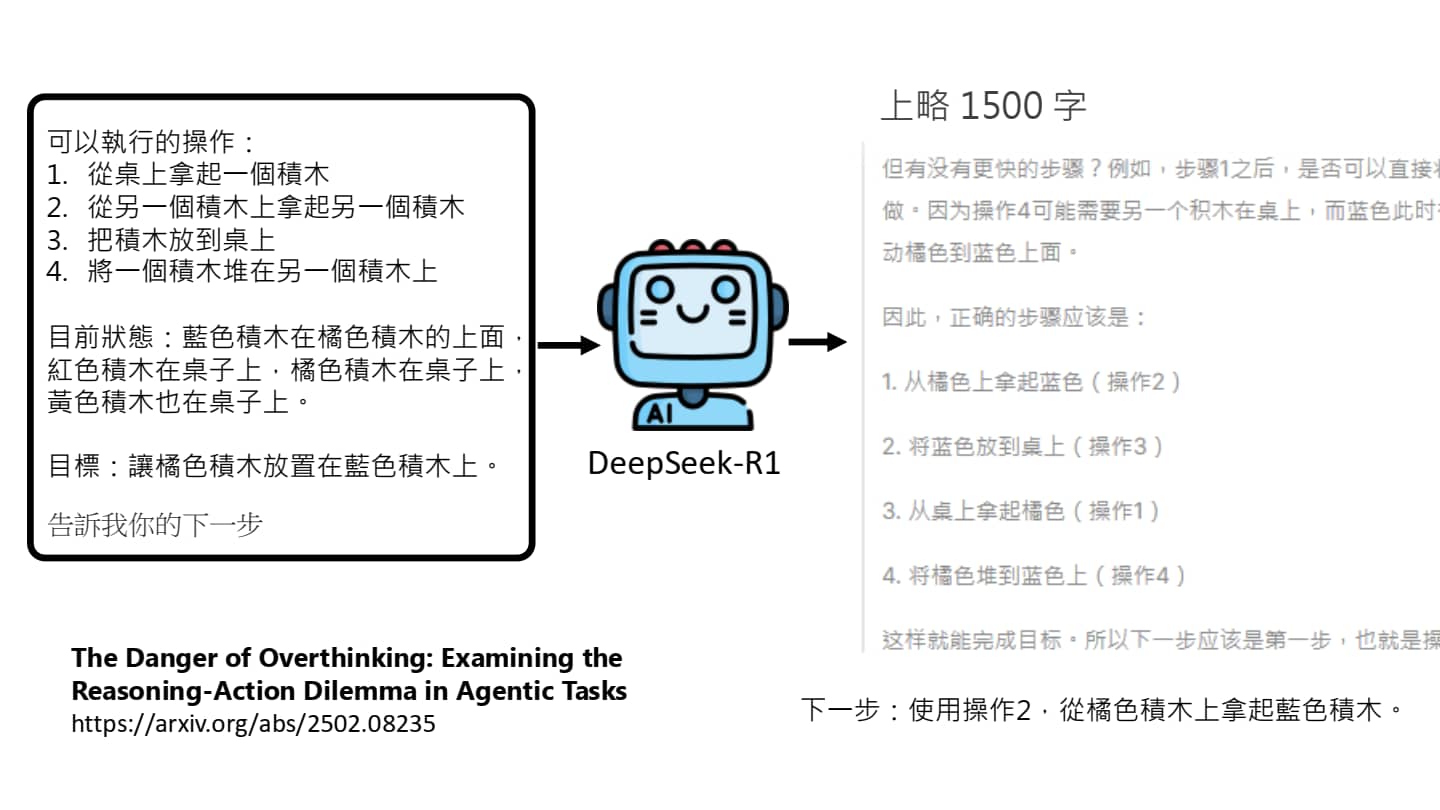
从 AI Agent 的视角来看大模型的 Reasoning 能力
许多模型都号称自己具有 Reasoning 能力,实际上也是一种脑内小剧场。