A Survey on Diffusion Language Models
本文最后更新于 2025年10月22日 晚上
论文链接:https://arxiv.org/abs/2508.10875
机翻 + 笔记,作图书馆用。
0. Abstract
扩散语言模型 (Diffusion Language Models, DLMs) 正迅速崛起,成为当前主流 自回归 (autoregressive, AR) 范式极具实力且前景广阔的替代方案。通过迭代去噪过程并行生成令牌 (token),扩散语言模型在降低推理延迟和捕捉双向上下文方面具有内在优势,进而能够对生成过程实现细粒度控制。尽管已实现数倍的推理速度提升,近年来的技术进展仍使扩散语言模型展现出与自回归模型相当的性能,这使其成为各类自然语言处理任务中极具吸引力的选择。
尽管扩散语言模型的应用日益广泛,但该领域仍存在诸多值得进一步探索的挑战与机遇,这需要研究者对其原理、技术和局限性形成详尽且系统的认知。本综述对当前扩散语言模型的研究现状进行了全面概述:追溯了扩散语言模型的发展历程及其与自回归模型、掩码语言模型 (masked language models, MLMs) 等其他范式的关联,同时涵盖了该领域的基础原理与最先进模型。
本研究的贡献包括:
- 提出了一个最新的、全面的扩散语言模型分类体系,并对现有技术(从预训练 (pre-training) 策略到先进的 后训练 (post-training) 方法)进行了深入分析;
- 对扩散语言模型的 推理策略 (inference strategies) 与优化方法展开了详尽综述,包括 解码并行性 (decoding parallelism) 提升、缓存机制 (caching
mechanisms) 优化及 生成质量 (generation quality) 改进等方向; - 重点介绍了扩散语言模型向多模态领域扩展的最新方法,并阐述了其在各类实际场景 (pracial scenatios) 中的应用。
- 本综述还探讨了扩散语言模型面临的局限性与挑战(包括效率问题、长序列处理 (long-sequence handling) 能力及基础设施需求等),同时勾勒了未来的研究方向,以推动这一快速发展领域的持续进步。
本研究相关项目的 GitHub 仓库地址为:https://github.com/VILA-Lab/Awesome-DLMs.
1. Introduction
通用人工智能 (AGI) 的近期发展在很大程度上得益于 自回归大语言模型 (LLMs)[1]-[7] 以及用于图像和视频生成的 扩散模型[8]-[12] 的兴起。这些模型在多种模态的理解与生成任务中均展现出卓越能力,实现了以往难以想象的性能水平。这些模型的规模前所未有——体现在海量的参数数量、庞大的数据集、大量的训练投入以及推理过程中极高的计算需求——这将人工智能推向了新的高度,使这些模型具备了广博的通用知识,并能深刻理解语言与现实世界。
GPT 系列模型[1],[13],[14] 的崛起,尤其是 ChatGPT[2] 的公开发布,推动自回归 (AR) 语言模型在 NLP 领域占据了主导地位。通过 因果注意力 (causal attention) 和 教师强制机制 (teacher forcing) 训练模型预测下一个 token,AR 模型[4],[15],[16] 能够有效扩展至大规模数据集与模型规模。
AR 模型 以逐 token 的顺序方式生成文本,擅长支持各类任务,从简单的问答到复杂的推理及创意写作均有出色表现。然而,这种顺序生成的特性给推理速度带来了 重大瓶颈:自回归生成过程每次仅能生成一个 token,这一本质属性 限制了并行计算能力,严重制约了计算效率与吞吐量。
扩散模型 是另一种极具前景的生成范式。这类模型通过训练,能够从逐渐加入噪声的数据中,通过去噪过程恢复原始数据,并通过逐步逆转这种随机损坏过程来生成新样本。扩散模型 在建模复杂数据分布方面表现突出,已在图像和视频合成任务中取得了最先进 (state-of-the-art, sota) 的成果[17]。
扩散建模领域的学术突破[18]-[21] 为模型的训练与推理奠定了坚实的理论基础。与此同时,Stable Diffusion[8],[10],[11]、Imagen[9]、Sora[12] 等大规模实用模型,充分展现了扩散范式卓越的可扩展性与泛化能力——仅需简单的文本提示(往往只需几个词),就能生成高保真度、艺术级别的图像与视频。除了强大的复杂数据分布建模能力,扩散模型 在 并行计算 方面还具有内在优势:通过迭代去噪过程,它们能够同时生成多个 token 乃至完整序列,这有望实现更优的推理吞吐量,并能更好地利用现代并行计算硬件。尽管仍面临挑战(尤其是在离散数据建模与动态序列长度处理方面),但扩散语言模型 (DLMs) 已成为一种极具吸引力的替代方案,可有效平衡生成质量与速度之间的权衡关系。
为使 扩散模型 适配离散语言数据,研究者提出了多种关键方法。早期,扩散模型 在图像合成等 连续域 的成功,是推动 DLMs 发展的主要动力。
连续空间 DLMs 会将 token 映射为 嵌入向量 (embeddings),并在连续空间中执行去噪过程,这一思路在 Diffusion-LM[22]、SED[23] 等开创性研究中已有体现。另一方面,离散空间扩散语言模型 (Discrete DLMs) 直接在 token 空间中定义扩散过程。早期研究(如 D3PM [24])引入了 含吸收态 (absorbing states) 的结构化转移矩阵,支持 token 级别的加噪与去噪。后续研究(如 DiffusionBERT [25])则整合了 预训练掩码语言模型(如 BERT)以提升去噪质量,并提出了 定制化噪声调度(如 spindle schedule),使 token 污染过程 (token corruption) 与 token 出现频率 更好地对齐。这些早期模型证明了将迭代去噪应用于非自回归文本生成的可行性,同时具备可控性与并行性优势,但性能仍落后于性能强劲的自回归基准模型。
随着扩散语言模型的核心挑战逐步得到解决、该范式日趋成熟,更大规模的扩散语言模型已被开发。通过从自回归模型初始化参数,Dream [26]、DiffuLLaMA [27] 等 7B 参数级模型表明:扩散语言模型可基于现有模型高效适配,同时实现具有竞争力的性能。LLaDA-8B [28] 模型进一步证明了从零训练扩散语言模型的潜力,其性能可与同规模的 LLaMA3-8B 模型相媲美。
多模态扩散语言模型 (Multimodal DLMs, aka. diffusion multimodal large language models, dMLLMs) 在建模文本、图像等混合数据方面也展现出潜力。这类模型基于开源扩散语言模型构建,例如LLaDA-V [29]、Dimple [30]、MMaDA [31] 等,它们将跨模态推理与生成能力整合到扩散框架中。与此同时,工业界对扩散语言模型的关注度也在不断提升:Mercury系列 [32]、Gemini Diffusion [33] 等模型不仅表现出强劲性能,还实现了每秒数千 token 的推理速度。这些进展凸显了扩散语言模型日益增长的实用性与商业潜力。
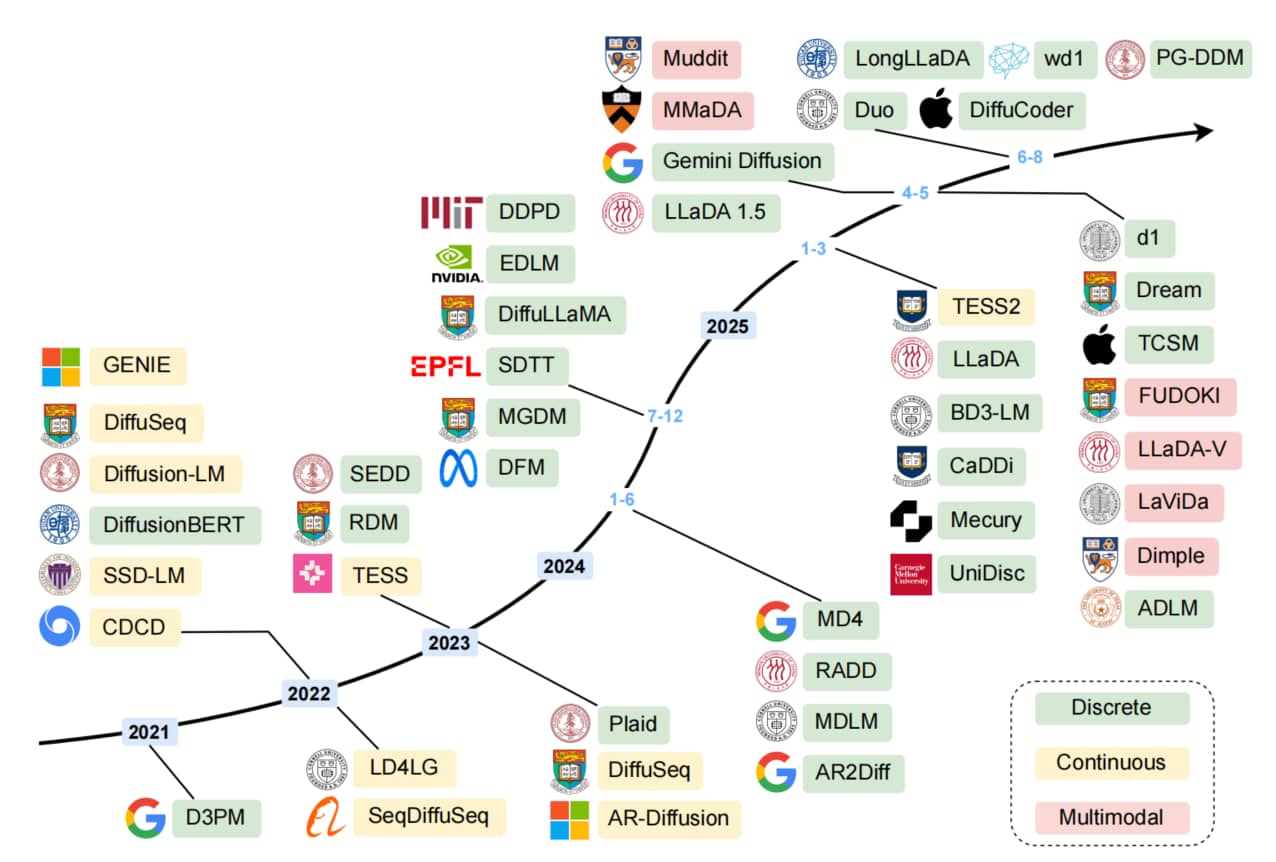
Fig.1: 扩散语言模型发展 timeline。该图展示了扩散语言模型发展历程中的关键里程碑事件,主要分为三大类别:连续型扩散语言模型、离散型扩散语言模型以及近期兴起的多模态扩散语言模型。值得注意的是,虽然早期研究主要集中在连续型扩散语言模型上,但近年来离散型扩散语言模型正获得越来越多的关注。
我们在 Fig.1 中提供了扩散语言模型的发展时间线(涵盖代表性模型及最新进展 [34]-[40]),随后在 Fig.2 中展示了扩散语言模型的发展趋势可视化结果。
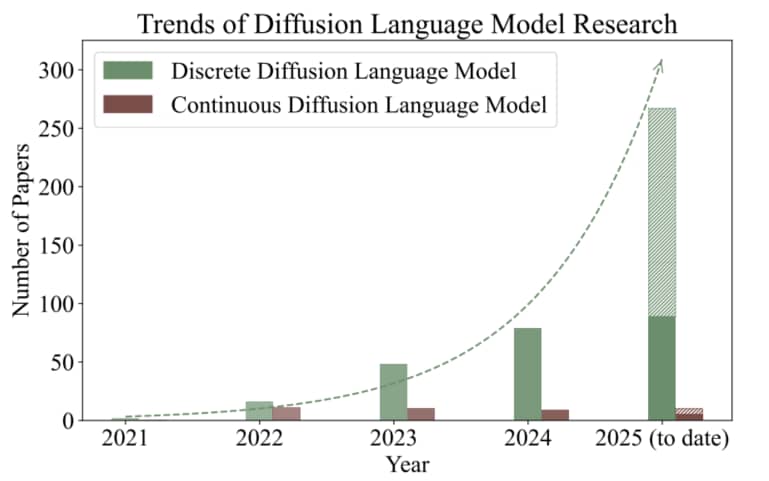
Fig.2: 扩散语言模型论文趋势图。关于离散型 DLM,统计数据源自引用 D3PM 的文献,并进一步筛选标题或摘要含"language"关键词的论文。连续型DLM的统计则基于本文关联知识库记载的相关研究数量。结果显示该领域研究热度持续攀升。注:本统计数据仅供参考。
扩散语言模型在训练与推理阶段还面临独特的挑战与机遇。在训练阶段:
- 预训练 (Pretraining):通常采用与自回归语言模型或图像扩散模型类似的策略 [26]、[30]、[31]。为加快训练速度并复用已有训练成果,许多扩散语言模型会从预训练自回归模型的权重初始化 [26]、[27]。
- 监督微调 (Supervised fine-tuning, SFT):扩散语言模型的监督微调流程也与自回归模型类似——向模型提供干净的提示词(prompt)数据,模型通过学习生成目标补全内容。
- 强化学习 (Reinforcement learning, RL):该技术也被应用于扩散语言模型的后训练阶段,以提升模型在复杂任务上的性能。研究者已提出 GRPO [41] 算法的多种变体(如 diffu-GRPO [42]、UniGRPO [31]),用于增强模型的推理能力,并在大规模场景下实现扩散语言模型 (DLMs) 的对齐。
在推理阶段,研究者已开发出多种策略与优化方法,以充分发挥 DLMs 的性能:
- 连续空间 DLMs 可利用 ODE/SDE 求解器或其他少步生成技术,加速迭代去噪过程 [43];
- 由于离散空间 DLMs 在并行生成方面面临更多挑战,研究者提出了专门的并行解码策略 [30]、[44]、[45],以实现单步接收多个 token 并克服“并行诅咒” (parallel curse);
- 解掩码与重掩码策略[28]、[46] 通过选择性暴露低置信度 token,进一步提升生成质量;
- 缓存技术[47]、[48] 则可显著减少两种范式(连续/离散 DLMs)的计算量,同时提升推理速度。
与自回归模型相比,扩散语言模型 被广泛认为具有以下几方面 显著优势:
- 并行生成能力 (Parallel Generation):通过迭代去噪过程,DLMs 可并行生成多个 token,推理速度与吞吐量较自回归模型有显著提升;
- 双向上下文建模 (Bidirectional Context):DLMs 天然具备双向上下文整合能力,能实现更细腻的语言理解与生成,同时生成更丰富的上下文嵌入向量——这不仅有利于跨模态生成任务,还能对生成过程实现细粒度控制;
- 迭代优化机制 (Iterative Refinement):迭代去噪过程允许 DLMs 在多步迭代中不断更新对序列的认知。对于掩码类 DLMs而言,它们可早期确定高置信度 token,并将低置信度区域保留为掩码状态,逐步优化不确定部分,最终生成更连贯、更高质量的文本;
- 生成可控性 (Controllability):DLMs 可基于特定 token 位置或结构进行条件生成,因此非常适合文本填充、结构化生成等任务;此外,引导技术(如无分类器引导,classifier-free guidance)还能更好地控制生成文本的风格与语义相关性;
- 跨模态统一建模 (Unified Modeling Across Modalities):借助共享的“基于去噪”建模框架,DLMs 天然支持文本与视觉的统一生成任务,这使其在“单模型需同时实现生成与理解”的多模态应用中极具潜力。
尽管 DLMs 近年来关注度快速上升,但目前仍缺乏一份能系统涵盖整个 DLM 生态的综合性综述。为此,本综述的结构安排如下:
- 第2章:全面概述现代语言建模范式,包括自回归、掩码及基于扩散的建模方法;
- 第3章:深入探讨 DLMs 的训练方法,涵盖 Pretraining、SFT、RL 对齐等后续微调技术;
- 第4章:详细阐述各类推理策略与优化方法,重点介绍针对连续空间与离散空间DLMs 的定制化技术;
- 第5章:探索扩散模型向多模态领域的扩展,综述 LLaDA-V[29]、MMaDA[31]、Dimple[30]等最先进模型与架构;
- 第6章:呈现并可视化 DLMs 的性能对比结果;
- 第7章:展示 DLMs 的多样化应用场景,涵盖文本生成、代码生成、计算生物学等任务;
- 第8章:重点分析 DLMs 面临的挑战与局限性(包括效率、推理能力、智能体能力、基础设施等问题),并勾勒未来研究的潜在方向。
为提供整体概览,Fig.3 展示了 DLMs 的分类体系。
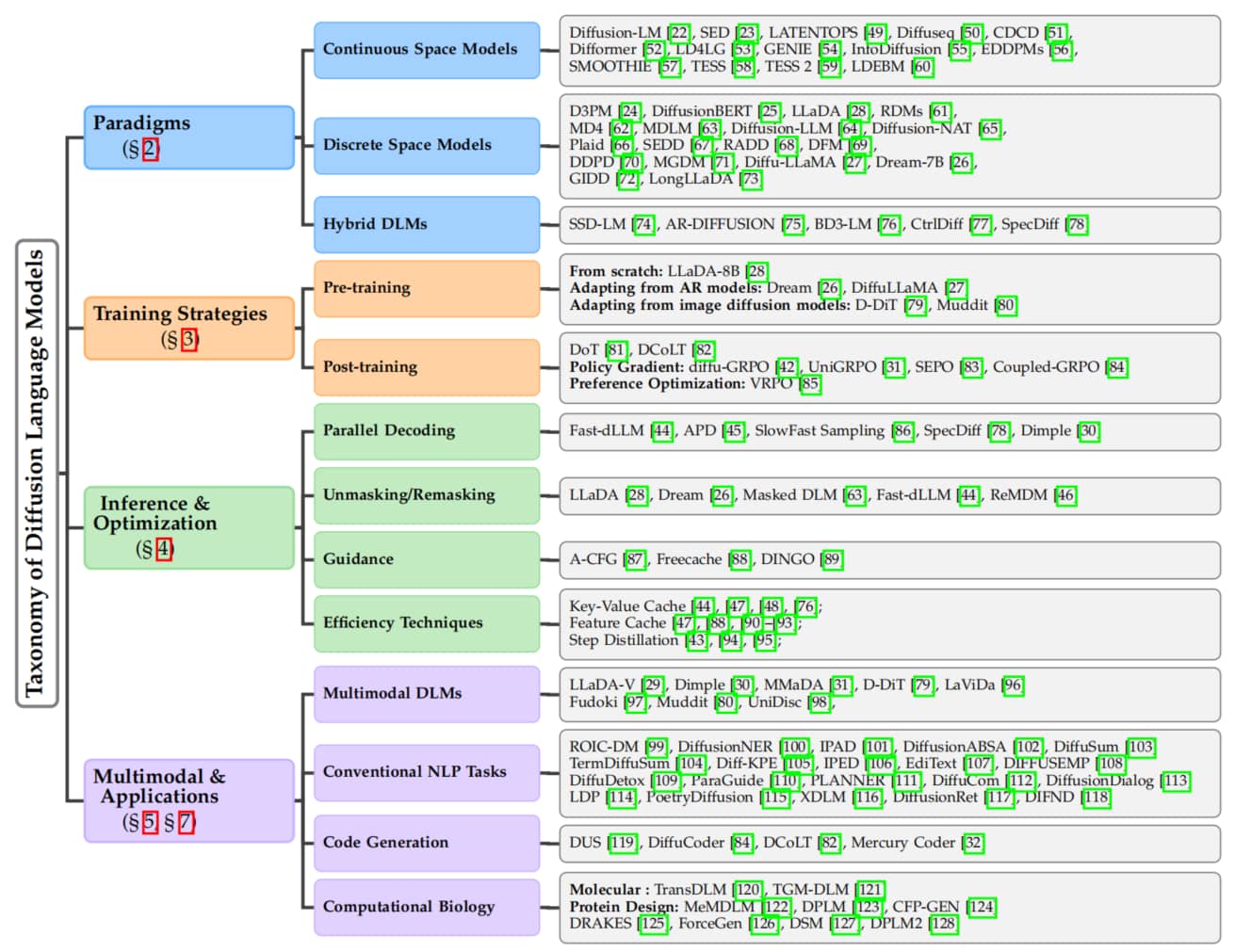
Fig.3: 扩散语言模型的分类体系,涵盖基础理论、训练与推理策略以及关键应用领域。章节编号(§)对应本综述中各章节位置。
2. Paradigms of Diffusion Language Models
扩散语言模型的范式
DLMs 已成为一种强大的 非自回归范式,能够平衡生成质量与推理并行性。受非平衡热力学原理[129]的启发,扩散语言模型通过学习逆转渐进式加噪过程实现生成。这种迭代优化方法支持对整个序列进行并行生成,为自回归 (AR) 模型的推理瓶颈提供了潜在解决方案。
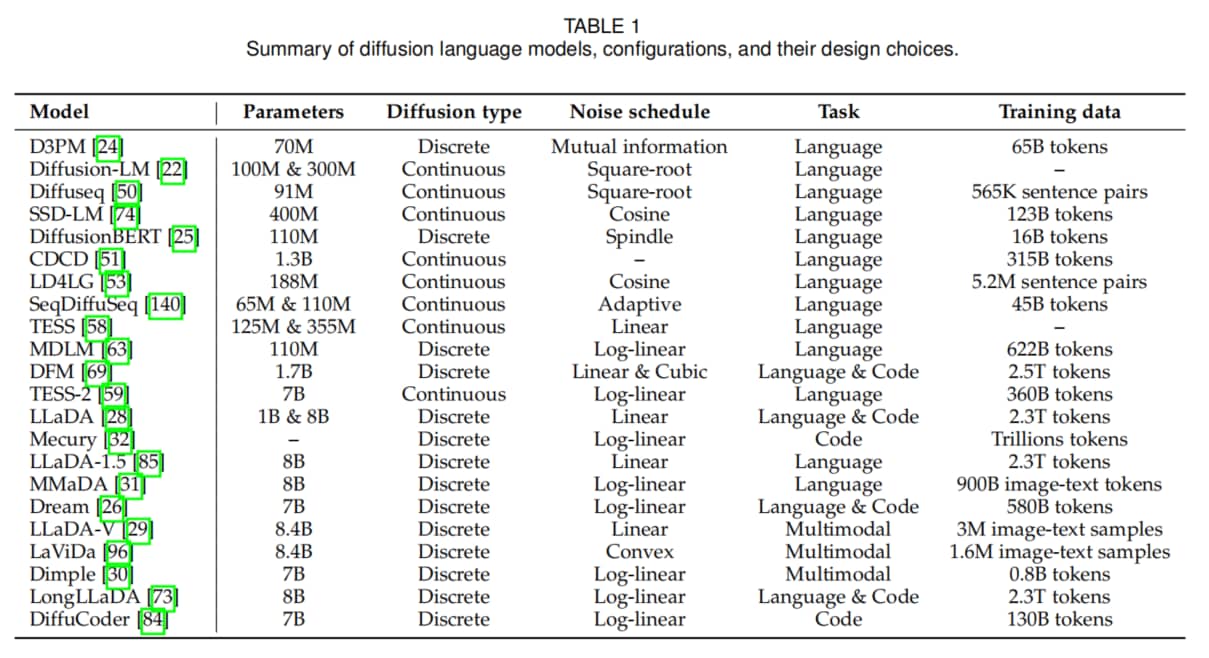
Table 1
根据扩散过程所作用的空间,扩散语言模型大致可分为两类:连续空间型 与 离散空间型。此外,还存在 混合自回归-扩散模型 (hybrid AR-Diffusion models),这类模型以多种形式融合自回归与扩散范式,旨在利用两种范式的互补优势。我们在 table 1 中呈现了多项研究中的模型信息,并在 Fig.4 中对不同范式进行了对比。
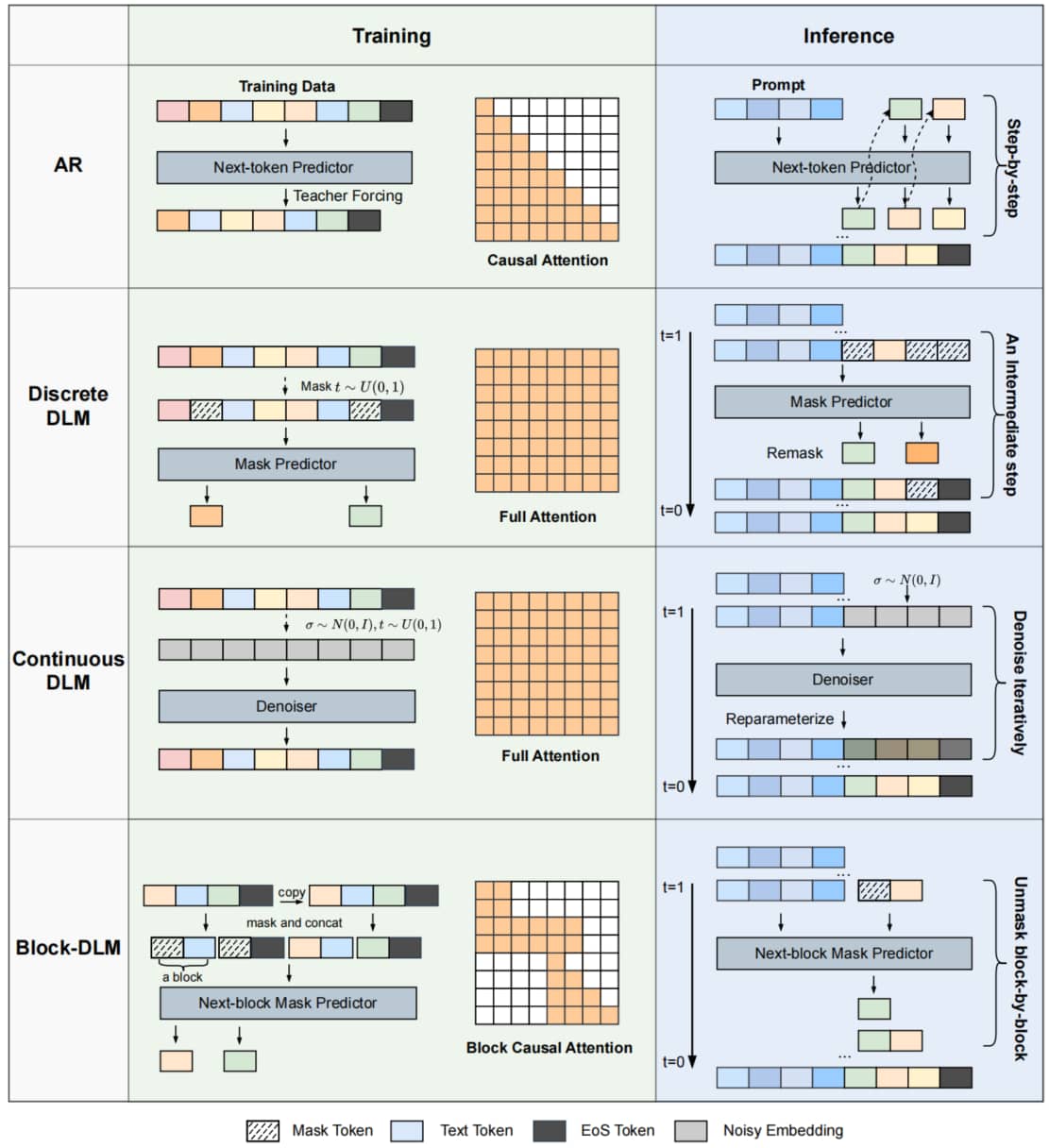
Fig.4: 跨范式扩散语言模型的训练与推理流程概览(含自回归模型作为对照)。自回归模型采用教师强制与因果注意力机制进行训练,而离散与连续两类扩散语言模型均使用完全双向注意力机制。以 BD3-LM[76] 为代表的块级扩散模型融合了自回归与扩散策略,其训练过程采用专门设计的块因果注意力掩码机制。
2.1 Preliminary of Modern Language Modeling
现代语言建模基础
语言建模领域经历了多个不同范式的演变,每种范式都具有独特的架构选择、训练目标及相关的权衡取舍。在本小节中,我们将简要概述近年来大规模基于 Transformer 的语言建模范式,重点阐述其核心原理、数学公式表述及代表性模型。本文不涵盖早期方法,因为此处我们聚焦于现代大规模设计。
为理解扩散语言模型(DLMs)作为一种新颖且极具前景的替代方案(其可解决先前方法的关键局限性)的兴起奠定概念基础。
2.1.1 Masked Language Models
掩码语言模型 MLMs
掩码语言模型 (MLMs) 因 BERT 模型[130] 而广泛普及,是一种基础语言建模范式——它采用基于 Transformer 的 encoder-only 架构,实现了预训练语言模型的规模扩展。这类模型概念上简洁但实证效果显著:通过预测输入序列中被随机掩码的 token,并同时利用该 token 的前文与后文语境,学习双向上下文表示。其核心思路遵循 denoising autoencoder (DAE) 框架:先对部分输入 token 进行掩码处理,再训练模型恢复这些被掩码的 token,数学表达式如下:
其中, 表示输入序列, 是被掩码位置的集合, 代表可见(未被掩码)的上下文。此外,BERT 还引入了 “下一句预测” (Next Sentence Prediction, NSP) 目标,用于建模句间关系,其数学表达式为:
式中, 是一对文本片段, 用于指示片段 在原始文本中是否紧跟在片段 之后( 表示是, 表示否)。
BERT 在语言理解任务(如情感分析、命名实体识别、问答系统等)中的出色表现,催生出众多改进变体:
- RoBERTa[131]:移除了 NSP 目标,并采用更激进的训练策略(如更长的训练时长、更大的批次大小);
- ALBERT[132]:通过参数共享(如不同 Transformer 层间共享参数)与矩阵分解技术,提升模型训练与推理效率;
- DeBERTa[133]:引入 “解耦注意力” (disentangled attention) 机制增强上下文编码能力,并优化了掩码 token 预测的解码流程。
尽管掩码语言模型在语言理解任务中优势显著,但其本质并非为生成任务设计:若要用于文本生成,需设计专门的微调策略或解码方案;若不进行大幅架构修改,这类模型无法适用于开放式文本生成任务。
2.1.2 Autoregressive Language Models
自回归语言模型
以 GPT 系列[1]、[2]、[13]、[14] 和 Transformer-XL[134] 为代表,后续大语言模型(LLMs)[3]-[5]、[135]进一步推动其发展,自回归语言模型 已成为现代生成式人工智能的核心支柱。其核心特征是 从左到右的单向 token 生成过程。与双向模型不同,自回归语言模型将文本序列的联合概率分解为条件概率的乘积:
给定 token 序列 ,模型的训练目标是在上述概率分解框架下,最大化序列的对数似然:
该目标通常通过 decoder-only Transformer 架构实现,训练过程中引入 因果注意力掩码(causal attention masking)和 教师强制(teacher forcing)机制:前者确保每个 token 的预测仅依赖于其前面的 token,后者则支持损失的并行计算。
自回归模型的“顺序生成”特性既是优势,也是局限:
- 优势:与文本生成任务的天然逻辑一致,采样过程直观,能自然适配问答、创作等各类应用场景;
- 局限:对推理速度构成根本性瓶颈——token 生成过程本质是顺序执行的,无法并行化。
这种生成质量与推理延迟的权衡,已成为自回归模型发展的核心挑战。除标准的 “下一个 token 预测” (next-token prediction, NTP) 外,近年研究开始探索 “多token预测” (multi-token prediction, MTP) [16]、[136]:通过每步生成多个 token 加速推理,其核心思路与扩散语言模型(DLMs)采用的并行解码策略存在概念上的相似性。
2.1.3 Other Paradigms
Sequence-to-Sequence Models
序列到序列模型
序列到序列模型 (Seq2Seq) [137]是一种早期但仍具强大能力的范式,基于 encoder-decoder 架构构建,是机器翻译、文本摘要等 条件文本生成任务 的通用框架。T5[138]、BART[139]等现代模型是该范式的典型代表。
在该架构中,编码器首先处理源序列并生成中间表示,解码器再基于此中间表示生成目标序列——通常采用自回归方式。尽管标准 Seq2Seq 模型的解码器为自回归设计,但该框架本身具备高度灵活性:许多扩散语言模型(如 DiffuSeq[50]、SeqDiffuSeq[140])对其进行适配,将自回归解码器替换为 非自回归扩散解码器,借助编码器强大的条件建模能力,引导生成过程中的去噪操作。
Permutation Language Models
排列语言模型
排列语言模型 (Permutation Language Models, PLMs) 以 XLNet[141] 为代表,为“在生成式框架中融入双向上下文”提供了另一种思路。这类模型的训练目标仍是预测序列中的 token,但并非采用固定的从左到右顺序,而是通过 随机排列的顺序 进行预测。其训练目标是在所有可能的概率分解顺序排列下,最大化期望对数似然:
其中, 表示长度为 的序列的所有可能排列的集合; 和 分别表示给定排列 中的第 个元素和前 个元素。这种设计使模型能为每个 token 捕捉双向上下文,既融合了 MLMs “双向上下文”的优势,又保留了自回归模型“连贯生成过程”的特点。这与 DLMs 形成鲜明对比——DLMs 通过“并行迭代优化过程”实现双向上下文建模。
2.2 Continuous Diffusion Language Models
连续空间扩散语言模型
连续空间扩散语言模型 (Continuous-space DLMs) 对语言建模的 核心思路 是:先将离散 token 映射到连续嵌入空间,再在该空间中通过扩散过程建模数据分布[22]、[23]。通常,扩散模型通过学习逆转预定义的加噪过程,来定义生成过程——该加噪过程会将数据逐步转化为噪声。整个过程包含 前向(加噪)过程 与 反向(去噪)过程 两部分:
2.2.1 Forward (noising) Process
前向过程通过固定的马尔可夫链,在 个时间步内将数据样本 逐步转化为噪声,其概率公式可表示为:
其中,每个时间步 的状态转移概率服从正态分布:
式中,(均值)和 (协方差矩阵)共同定义了 噪声调度(noise schedule)。在许多实际实现中(如DDPM[18]、Rectified Flow[21]),每个时间步的边缘分布可表示为闭式解:
这里, 和 是关于时间步 的确定性函数, 是服从标准正态分布(均值为0、协方差矩阵为单位矩阵 )的噪声。
2.2.2 Backward (denoising) Process & Objective
反向过程的核心是“逆转加噪过程”:从服从标准正态分布的噪声 出发,通过逐步去噪恢复出与原始样本 接近的结果。该过程由神经网络 参数化实现(通常采用 Transformer 架构),其核心任务是预测与前向过程相关的目标量 (如干净数据、噪声或速度)。
连续空间 DLMs 的常用训练目标函数形式如下:
其中, 是由原始样本 通过前向过程采样得到的带噪样本, 是由 和时间步 推导得到的对应回归目标。
2.2.3 Generation Process
模型训练完成后,生成过程通过“从学习到的反向过程中采样”实现,具体步骤如下:
- 初始化:从标准正态分布中采样初始噪声 ;
- 迭代去噪:在时间步 上,模型定义条件分布 ,用于近似真实的反向转移概率 ;通过从这些学习到的条件分布中迭代采样,latent 状态的噪声会逐步降低,直至恢复出原始数据 的估计值;
- 离散化映射:生成去噪后的嵌入 后,需通过 rounding step 将其映射回离散 token —— 通常通过 “嵌入空间中的最近邻搜索” 或 “解码器头” (decoder head) 实现。
2.2.4 代表性连续空间 DLM 模型
- Diffusion-LM[22]:首次在嵌入空间中引入扩散过程,构建了非自回归语言生成模型。通过借鉴图像扩散模型中的 分类器引导机制,实现了高度可控的文本生成与文本填充 (text infilling)。
- LDEBM[60]:在变分学习框架下,提出 latent 空间能量模型 (Energy-Based Models, EBMs) 与扩散模型的新型协同机制,解决了基于能量先验的学习难题,重点优化了文本建模的可解释性。
- LATENTOPS[49]:在紧凑 latent 空间中实现可组合文本操作的高效框架。引入基于 ODE 的高效采样器,在 即插即用控制算子 的引导下生成 latent 向量,再解码为目标文本。
- Diffuseq[50]:面向序列到序列(Seq2Seq)任务的无分类器引导扩散语言模型。前向过程中仅对目标序列嵌入进行加噪,实现了性能强劲且多样性丰富的条件文本生成。
- SED[23]:(Self-conditioned Embedding Diffusion) 直接在固定的连续 token 嵌入空间中进行扩散。通过引入 自条件机制,其条件与无条件文本生成性能均表现出色,可与标准自回归模型抗衡。
- CDCD[51]:通过将 token 嵌入到连续空间,实现对类别数据的连续扩散建模。提出“分数插值”技术(支持用交叉熵损失训练模型)与“时间扭曲”策略(训练中高效调度噪声强度的自适应方法)。
- Difformer[52]:针对嵌入空间的优化难题,引入 锚定损失 (anchor loss) 防止嵌入坍缩,并设计 噪声重缩放框架 (noise rescaling framework) 缓解模型退化,提升生成稳定性。
- LD4LG[53]:将预训练语言模型作为强大的自编码器,构建紧凑 latent 空间;在该空间中训练连续扩散模型,实现高质量文本生成。
- GENIE[54]:面向扩散语言模型的大规模预训练框架 (large-scale pre-training framework),提出 连续段落去噪目标 (continuous paragraph denoise objective),通过重构受损文本段落,实现从大规模语料中的高效学习。
- InfoDiffusion[55]:引入 信息熵感知噪声调度,引导模型遵循 核心信息优先 (KeyInfo-first) 的类人生成逻辑,优先生成文本的核心内容。
- EDDPMs[56]:通过参数化 encoder-decoder 泛化扩散过程,统一了生成 (generation)、重构 (reconstruction) 与表示 (representation) 三大任务,支持在单一框架内对所有组件进行稳定联合训练。
- SMOOTHIE[57]:提出 基于语义相似性逐步平滑 token 嵌入的新型扩散过程,融合了连续 latent 空间的灵活性与离散 token 处理的准确性。
基于 logit 空间的连续扩散扩展
连续扩散过程也可在 logit 空间(而非嵌入空间)中构建:
- TESS[58]:提出完全非自回归框架,在 token 的 k-logit 单纯形表示 (k-logit simplex representation) 上进行扩散,并设计适配该场景的新型自条件机制。
- TESS 2[59]:进一步扩展 TESS 的规模——通过扩散专用预训练流程与指令微调,将预训练大型自回归模型适配为通用扩散语言模型,赋予模型强大的指令跟随能力。
2.3 Discrete Diffusion Language Models
离散空间扩散语言模型
离散空间扩散语言模型 (Discrete-space DLMs) 直接在 token 词汇表上定义扩散过程,无需在扩散过程本身中使用连续嵌入空间。
D3PM[24] 首次通过在离散 token 上引入结构化扩散过程,验证了该思路的可行性。其前向过程通过在 每一步应用转移矩阵 对序列进行加噪,该矩阵定义了一个 token 转移到词汇表中任意其他 token 的概率。给定初始状态 时,状态 的概率服从类别分布 (Categorical Distribution):
其中, 的常见选择是 吸收态转移 (absorbing state transition):每个 token 要么以一定概率保持不变,要么转移到特殊的 “[MASK]” token。反向过程则学习逆转这些转移——基于受损序列预测原始 token 的概率分布。
随着研究发展,掩码类扩散语言模型 (masked DLMs) 已成为离散扩散语言模型的一种现代且高效的演进形式,为近年来多项大规模研究[27]、[28]奠定了基础。以该类模型中最具代表性的 LLaDA[28] 为例:受早期“重参数化与简化训练目标”相关研究[61]、[62]、[68]的启发,LLaDA 采用从零开始训练的方式,损失函数为仅对被掩码 token 计算的交叉熵损失,公式如下:
其中, 从训练语料中采样, 从 上均匀采样, 是 通过前向过程加噪后得到的序列;指示函数 确保损失仅作用于已被掩码的位置( 表示 的第 个位置为掩码符号 ,即“[MASK]”)。
在推理阶段,生成过程从 期望长度的全掩码序列 开始,具体步骤如下:
- 迭代去噪:每一步中,模型接收当前序列(包含已生成 token 与 “[MASK]”token 的混合),并预测完整的 token 序列;
- 动态掩码调整:根据模型的预测置信度与噪声调度,将一定数量置信度最高的预测结果解掩码并固定,剩余位置则重新掩码;
- 终止条件:该优化过程迭代进行,直至所有 “[MASK]”token 都被解析。
这种方法巧妙结合了 MLMs 的双向上下文建模能力与可控的并行生成过程。其中,LLaDA-8B 模型尤为突出——不仅展现出强大的可扩展性与指令跟随能力,性能还能与 LLaMA3-8B 等高性能自回归模型相当,对自回归模型在大规模语言生成领域的长期主导地位构成了挑战。
DiffusionBERT[25] 将预训练 BERT 与离散扩散过程相结合:借助 BERT 强大的去噪能力,从掩码状态中学习反向过程。此外,该模型还通过一种新颖的 纺锤噪声 (spindle noise) 调度策略进一步提升性能——该策略会考虑 token 的信息重要性,使生成质量较此前的扩散语言模型有显著提升。
另一种方法是 重参数化 离散扩散模型 (Reparameterized Discrete diffusion Models, RDM) [61],它为逆向过程建立了一种替代公式,将训练目标简化为加权交叉熵损失。这使得解码策略更具灵活性和适应性,相比以往的离散扩散模型,性能获得了显著提升。类似地,MD4[62]将交叉熵损失的加权积分作为掩码扩散模型的连续时间变分目标,为扩散语言模型的训练提供了一个简洁且通用的框架。
另一种类似的方法是 MDLM[63],它引入了一种简化的 Rao-Blackwell 化目标,该目标以掩码语言建模损失的加权平均值形式呈现。Diffusion-LLM[64] 通过将预训练掩码语言模型适配到扩散范式,并进一步进行任务特定微调与指令微调,展现了扩散语言模型的可扩展性,从而解锁了其在解决通用语言任务中的通用性。Diffusion-NAT[65]通过将去噪过程重构为非自回归掩码令牌恢复任务,将 Discrete DLMs 与 PLMs 相融合,使 BART 能够作为有效的去噪器发挥作用。
Plaid[66] 是首个以最大化数据似然为训练目标的扩散语言模型,其通过 scaling laws 证明,在标准基准测试中,该模型的性能可优于 GPT-2 等自回归模型。为改进训练目标,SEDD[67] 引入了 得分熵损失 (score entropy loss),用于直接学习数据分布的比率,这是得分匹配 (score matching) 的离散扩展。RADD[68] (Reparameterized Absorbing Discrete Diffusion, 重参数化吸收离散扩散) 发现,吸收扩散中的具体得分可表示为干净数据的与时间无关的条件概率,再乘以一个与时间相关的解析标量。此外,该方法还正式统一了吸收离散扩散与任意阶自回归模型的训练目标。
DFM[69] (Discrete Flow Matching, 离散流匹配) 为离散数据引入了一种新颖的生成范式,该范式与连续流匹配 (continuous Flow Matching) 类似。该方法通过学习生成概率速度,使样本能够沿着从源分布到目标分布的通用概率路径进行转换。通过缩放模型架构,DFM 在各类基准测试中显著缩小了与自回归模型的性能差距。DDPD[70] 提出了一个将生成过程解耦为两个专用模型的框架:规划器 (planner) 和 去噪器 (denoiser)。在每一步中,规划器识别出最需要优化的受损令牌位置,随后由去噪器预测这些位置的令牌值。
为提升模型在复杂推理任务中的性能,研究人员提出了 MGDM[71] 以解决子目标失衡问题。该方法通过令牌级重加权机制,在学习过程中优先处理更复杂的子目标,从而增强了离散扩散的效果。为应对模型缩放挑战,有研究[27]提出了一种持续预训练方法,将 LLaMA 等现有的自回归模型适配为扩散语言模型。由此得到的模型(命名为 DiffuGPT 和 DiffuLLaMA)不仅能与 AR 模型媲美,还具备了扩散模型特有的能力(如灵活填充)。
基于这一思路,Dream-7B[26] 以 Qwen2.5 7B[142] 为初始化模型,并用 580 B 个令牌进行进一步训练,其性能大幅优于现有扩散语言模型,且能比肩顶级自回归模型。GIDD[72] 的提出旨在克服掩码扩散模型无法修正已生成令牌的局限:该框架通过 将掩码与均匀噪声结合,对加噪过程进行泛化,从而使模型具备了自我修正错误的能力,并提升了样本质量。
近期,为提升模型的长上下文能力,LongLLaDA[73] 首次对扩散语言模型在该领域的表现进行了系统性分析。研究发现,扩散语言模型在直接上下文外推过程中能保持稳定的困惑度,且具有更优的检索能力。此外,LongLLaDA 还引入了一种基于 NTK 的无训练 RoPE 外推方法,该方法显著提升了外推性。
2.4 Hybrid AR-Diffusion Language Models
混合自回归-扩散语言模型
混合自回归-扩散模型 (Hybrid AR-Diffusion Models) 旨在在非自回归模型的全并行性与自回归模型强大的因果依赖建模能力之间取得平衡。混合自回归-扩散建模的核心策略之一是采用 块级半自回归生成过程:在该框架下,模型 以自回归方式生成令牌块 (blocks of tokens),而每个块内部的令牌则通过类扩散的迭代过程并行生成。
早期研究如 SSD-LM[74] 开创了混合方法的先河,其在单纯形表示 (simplex representations) 上通过块级连续扩散过程实现建模;AR-DIFFUSION[75] 则提出了多级扩散过程,并通过根据令牌位置调整时间步长 (timestep) 实现半自回归生成。近期的代表性模型 BD3-LM[76] 在离散模型上进一步推进了这一方向,其性能显著优于纯自回归模型和纯扩散模型。CtrlDiff[77] 则通过引入动态块预测技术改进了该范式,提升了块级生成的效率与可控性。
这类模型的生成过程通常包含两个嵌套循环:
- 外循环:以自回归方式生成令牌块,每个块的生成均以先前生成的块为条件;
- 内循环:在每个块内部,通过类扩散的迭代去噪过程实现令牌级并行生成。
在 BD3-LM 中,训练目标被形式化为:
该混合策略使模型能够通过自回归捕捉块间的长程依赖,同时通过并行扩散加速块内令牌的生成。此外,该设计还支持灵活的输出长度,并兼容自回归模型中广泛使用的 键值缓存 (KV-Cache) [76]。
值得注意的是,近期的掩码扩散语言模型[28]、[31]也采用了类似的半自回归块级解码策略,这类模型可被视为混合自回归-扩散建模的典型实例。
除了在序列层面结合自回归与扩散的块级方法外,混合还可发生在架构层面:神经网络的某一部分(通常是编码器)将整个序列扩散为中间表示,随后由自回归解码器生成最终序列[143]。LADIDA[144] 采用了略有不同的思路,其在文档层面进行扩散,但通过自回归解码器对句子进行解码;SpecDiff[78] 则提出了一种协同推测解码框架(collaborative speculative decoding framework):由轻量级扩散模型生成候选输出,再由大型自回归模型对候选输出进行验证与最终确定。
3 DLMs: Pre-training and Post-training
扩散语言模型:预训练与后训练
3.1 Pre-training and Supervised Fine-tuning
预训练与监督微调
扩散语言模型 (DLMs) 的预训练流程在很大程度上遵循与自回归语言模型(适用于离散扩散语言模型)或图像扩散模型(适用于连续扩散语言模型)相似的步骤,但其设计空间相对较少。本节简要总结现有扩散语言模型的预训练方法,旨在弥合 DLMs 与 ARMs 之间的方法学差距。
为加快训练速度(尤其是针对大规模模型),常见做法是 从预训练的自回归语言模型或图像扩散模型 中初始化 DLMs。DiffuGPT与DiffuLLaMA[27] 尝试使用参数规模从 127M ~ 7B 的开源 LLMs 初始化掩码扩散语言模型,结果表明: 扩散语言模型可从自回归模型中高效适配而来,在显著缩短训练时间、降低训练成本的同时,还能实现与自回归同类模型相当甚至更优的性能。 基于这一发现,Dream-7B 以 Qwen 2.5 7B[142] 为初始模型,据报道其在各类基准测试中的性能均优于 LLaDA-8B与LLaMA3-8B。
另一方面,部分多模态扩散语言模型(multimodal DLMs)从预训练的图像扩散模型中初始化。例如,D-DiT[79] 与 Muddit[80] 分别从 SD3[11] 和 Meissonic[145] 的预训练 MM-DiT 骨干网络中初始化。尽管这些模型最初并非为文本生成设计,但其 latent 表示中包含内在的与语言对齐的知识,这既能有效促进语言建模的训练,又能保留强大的视觉生成能力。
扩散语言模型的 监督微调 (SFT) 流程通常与自回归模型相似。对于 LLaDA[28]这类掩码扩散语言模型,提示令牌 (prompt tokens) 保持不掩码状态,而 响应令牌 (response tokens) 则被选择性掩码,这种方式能让模型以与预训练兼容的模式学习条件响应生成。在连续扩散语言模型中,监督微调还可通过仅对响应片段进行加噪实现,如 TESS2[59] 所示。
尽管扩散语言模型的训练流程与自回归模型整体相似,但由于其基于扩散的架构设计,仍面临一些独特挑战。其中一个 主要问题 是 掩码扩散语言模型的损失计算效率较低:在典型的掩码扩散语言模型训练中,若对时间步(timestep) 进行均匀采样,平均仅 50% 的令牌会参与损失计算。这会降低数据利用率,并可能导致模型获得非最优梯度——尤其是当关键答案令牌未参与损失计算时,该问题更为突出。
为解决这一问题,LaViDa[96]提出了一种互补掩码策略:将每个训练样本复制为两个带有 不重叠掩码模式 的样本,确保所有令牌至少参与一次损失计算。此外,如文献[146]所示,由于存在 训练-推理差异 (train-inference discrepancy),模型在训练阶段的性能显著优于推理阶段。对此,作者提出了一种两步扩散流程与改进的调度技术,以缓解这一问题。
3.2 Post-training for Reasoning Capabilities
面向推理能力的后训练
随着 DLMs 在语言任务上的性能不断提升,其推理能力的探索也日益受到关注。通常情况下,模型的推理能力需通过在推理数据集上进行微调来获得。但这一过程对扩散语言模型而言,面临着独特且艰巨的挑战:传统的思维链 (Chain-of-Thought, CoT) 方法依赖 AR 模型的 序列生成特性 实现逐步推理,而扩散语言模型采用并行方式生成令牌;在自回归模型领域中最成功的后训练技术(尤其是基于 RL 和策略梯度的方法),其核心是 能够高效计算生成序列的对数概率——得益于自回归模型的可分解性与序列特性,这一计算在自回归模型中十分直接。但扩散语言模型的生成过程是迭代式、非序列的,其对数似然难以求解,这为将成熟的自回归模型强化学习算法套件应用于扩散语言模型设置了重大技术障碍。
基于直观分类,我们将现有针对扩散语言模型推理能力的后训练工作划分为三大方向,构成本节的核心内容:
- 推理链并行化,即把自回归模型中的 CoT 适配到扩散语言模型的并行生成过程中;
- 策略梯度方法适配,即向扩散语言模型引入 GRPO 等主流算法的变体;
- 偏好优化方法适配,即向扩散语言模型引入 直接偏好优化 (DPO) 等方法。
3.2.1 DoT and DCoLT: Parallelizing the Reasoning Chain
DoT 与 DCoLT:推理链并行化
在扩散语言模型中实现复杂推理的开创性工作之一是 思维扩散 (Diffusion-of-Thought, DoT)[81],该方法将主流的思维链范式适配到扩散框架中。与自回归模型按序列生成推理步骤不同,DoT 将推理步骤构建为“中间思维”,并在整个扩散去噪过程中对这些中间思维进行并行优化。具体实现方式为:在包含问题及其对应逐步推理过程的数据集上,对 Plaid[66]、SEDD[67] 等预训练扩散语言模型进行微调。
为提升模型的自我纠错能力,DoT 引入了 调度采样 (scheduled sampling) 和 耦合采样 (coupled sampling) 等专用训练技术——在训练过程中让模型接触自身生成的错误,从而增强其自我修正能力。这种后训练方法使小型扩散语言模型能实现出色的推理性能,甚至在部分数学和逻辑推理基准测试中,表现优于规模大得多的自回归模型。
近期提出的 横向思维扩散链 (Diffusion Chain of Lateral Thought, DCoLT) [82] 则引入了一种独特的基于强化学习的推理框架,其灵感来源于“横向思维”这一认知概念,与传统思维链方法的“逐步纵向思维”形成鲜明对比。DCoLT 不对中间推理步骤进行监督,而是将逆向扩散过程的每一步视为“潜在思维动作”,并通过基于结果的强化学习优化整个多步去噪轨迹,以最大化最终答案的奖励值。
在将 DCoLT 应用于 LLaDA 等掩码扩散语言模型时,该方法创新性地引入了 解掩码策略模块 (Unmasking Policy Module, UPM)——该模块将学习令牌的最优揭示顺序作为强化学习动作空间的一部分。这种方法显著提升了扩散语言模型的推理能力:经 DCoLT 强化的 LLaDA 模型在 GSM8K 基准测试中性能提升 9.8%,在 HumanEval 基准测试中性能提升 19.5%。
3.2.2 Adapting Policy Gradient Methods to DLMs
策略梯度方法向扩散语言模型的适配
得分熵策略优化 (Score Entropy Policy Optimization, SEPO) [83] 首次将 基于人类反馈的强化学习 (RLHF) 引入离散扩散语言模型,提出了一个具有理论支撑的框架——利用策略梯度方法和非可微奖励对离散扩散模型进行微调。
SEPO 在得分熵框架下运行,通过重要性采样推导稳定且低方差的梯度估计,从而适配 PPO、GRPO 等现代策略梯度方法。这使得模型的策略可通过迭代更新最大化奖励函数,进而成为适用于条件生成与无条件生成的通用框架。SEPO 的目标函数定义如下:
其中,模型参数 的优化目标是最大化得分熵 的加权期望对数似然,权重 ;期望计算基于来自先前策略 的样本 。函数 的选择可对应不同的策略梯度变体:例如,选择截断函数可得到 PPO,选择组标准化奖励可得到 GRPO。该公式即使在存在非可微奖励的情况下,仍能实现稳定且低方差的梯度估计,同时为离散扩散模型的微调提供了灵活的目标函数。在多个离散生成任务上的数值实验表明,SEPO 具有良好的可扩展性和效率,验证了策略梯度强化学习能可靠地应用于离散扩散模型。
d1[42] 为掩码扩散语言模型提出了一个两阶段后训练框架,该框架 将监督微调 (SFT) 与一种新型策略梯度算法 diffu-GRPO 相结合。 由于扩散语言模型缺乏可分解的似然函数,为将 GRPO 适配到扩散语言模型中,d1 提出了 序列对数概率和令牌级对数概率的新型估计方法 :通过简单的平均场分解,将序列对数概率近似为独立令牌级概率的乘积;而令牌级对数概率的计算方式为:在每次策略梯度更新时,以随机掩码的提示 (prompt) 为条件,对完全掩码的补全内容 (completion) 执行单次前向传播。在每次内部梯度更新步骤中,为提示采用不同的随机掩码,这一操作可作为一种正则化手段,提升训练效率与稳定性。d1 的完整流程(先执行SFT,再执行diffu-GRPO)表明,LLaDA 模型在数学推理和规划推理任务上的性能得到了显著提升。
“多模态大扩散语言模型”(MMaDA)[31]是一种统一的多模态扩散模型,其提出了一个三阶段训练流程。在第一阶段预训练完成后,MMaDA 采用 混合长思维链微调 策略:将不同任务的推理轨迹整理为统一格式,以对齐跨模态的推理过程。这一操作为第三阶段的训练奠定了基础——该阶段引入了 UniGRPO,这是一种专为扩散语言模型设计的策略梯度强化学习算法。
UniGRPO 通过一种结构化加噪策略克服了 d1 等基准方法的局限性:该策略对掩码率 进行均匀采样,而非对所有响应令牌进行掩码。这确保模型能接触到多步扩散去噪过程的各个阶段(从几乎完全掩码到几乎无掩码),与传统扩散训练保持一致,同时提升了模型多步去噪能力的利用率。此外,UniGRPO 通过对掩码令牌取平均,近似计算序列级对数似然。
DiffuCoder[84] 是一款专为代码生成设计并分析的 7B 参数扩散语言模型。该研究提出了一种名为coupled-GRPO 的强化学习算法,该算法通过利用 DLMs 生成过程的独特属性,实现了“扩散原生”设计。coupled-GRPO 的核心创新在于其用于对数似然估计的耦合采样方案。为获得更稳健、更低方差的估计结果,该算法会为训练批次中的每个补全序列构建成对的互补掩码。对于给定序列,生成的两个掩码需满足:每个令牌位置恰好仅在其中一个掩码中被掩盖。随后,通过对这两次互补前向传播的损失取平均,得到对数概率估计值。这一设计确保训练过程中每个令牌都能在部分掩码场景下被评估,与采用单一随机掩码或全掩码的方法相比,既实现了令牌的全面覆盖,又能获得更稳定的梯度信号。实验表明,coupled-GRPO 显著提升了 DiffuCoder 在代码生成任务上的性能,同时还促使模型形成更偏向并行、更少依赖自回归的生成模式。
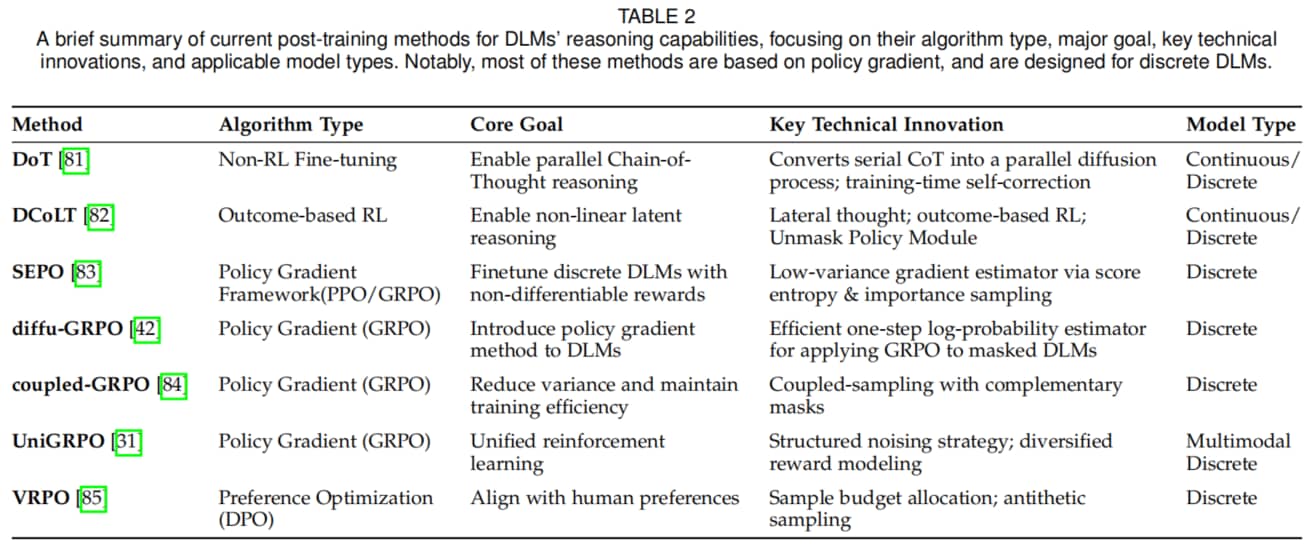
Table 2
3.2.3 Adapting Preference Optimization to DLMs
偏好优化方法向扩散语言模型的适配
LLaDA 1.5[85]提出了一种名为 方差缩减偏好优化 (Variance Reduced Preference Optimization, VRPO) 的新型框架,旨在将偏好优化方法适配到离散扩散语言模型中。该研究指出,由于用于近似对数似然的证据下界 (Evidence Lower Bound, ELBO) 存在高方差问题,将直接偏好优化 (Direct Preference Optimization, DPO) 应用于离散扩散语言模型面临挑战。
为解决这一问题,VRPO 引入了两种关键的 无偏方差缩减技术:
- 蒙特卡洛采样预算的最优分配:通过采样更多扩散时间步(而非为每个时间步采样多个掩码版本)实现,即 且 ;
- 对偶采样(Antithetic Sampling):对于相同输入 或 ,当前策略 与参考策略 的ELBO估计共享相同的时间步和掩码数据。
将 VRPO 应用于 LLaDA 后,得到的 LLaDA 1.5 模型在数学推理、代码生成及对齐基准测试中均展现出显著且稳定的性能提升。
4 Inference Strategies
推理策略
DLMs 的推理策略旨在实现三大核心目标:
- 通过 解掩码 (unmasking) 与 重掩码 (remasking) 调度等方式提升生成质量;
- 实现更精细的内容控制;
- 通过键值 (KV) / 特征缓存、步骤蒸馏等技术提升效率。
相关方法的简要概述如图 5 所示。
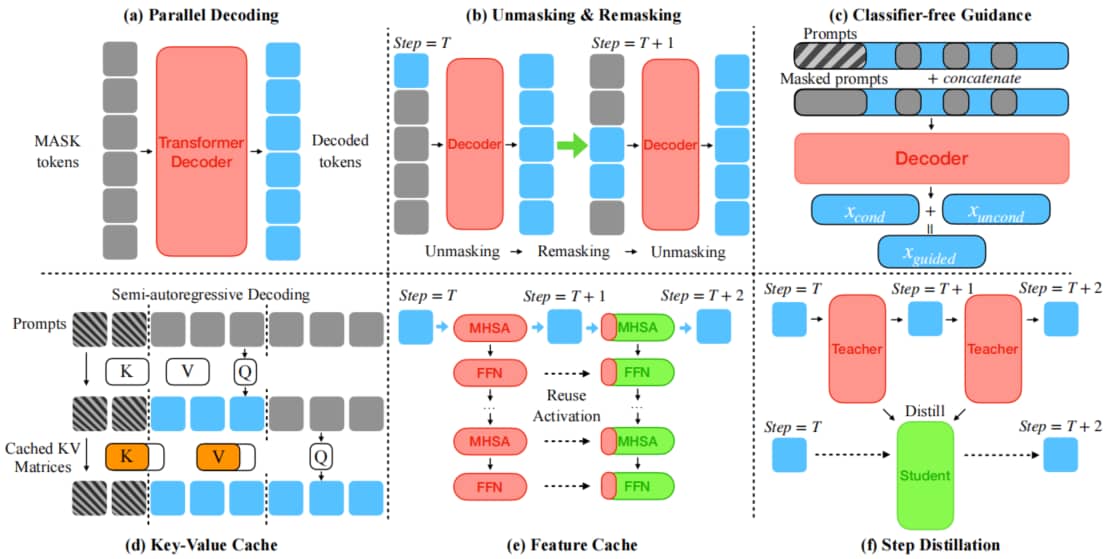
Fig.5: 扩散语言模型的推理技术。此处我们展示了六种不同策略,包括:(a) 并行解码;(b) 去掩码&重掩码;(c) 无分类器引导;(d) 键值缓存;(e) 特征缓存;以及(f) 步数蒸馏。
4.1 Parallel Decoding
并行解码
并行解码与扩散语言模型的特性天然契合——利用模型固有的掩码预测能力,可同时生成多个令牌(而非按序列生成)。然而,简单粗暴的并行化可能会降低文本连贯性,因此研究人员提出了一系列自适应策略,以平衡效率与生成质量。
- Fast-dLLM[44] 采用 置信感知解码(confidence-aware decoding) :仅对预测概率超过阈值的令牌进行解掩码,在不损失生成质量的前提下,实现了最高 27.6 倍的速度提升;
- 自适应并行解码 (Adaptive Parallel Decoding, APD) [45]:通过咨询轻量级自回归辅助模型,动态调整并行化程度,从而在必要时以吞吐量换取生成保真度;
- 快慢采样 (Slow-Fast Sampling) [86]:引入两阶段调度——首先通过 “慢阶段” 谨慎定位稳定令牌,再通过 “快阶段” 批量确定令牌,结合缓存技术时可实现最高 34 倍的加速;
- SpecDiff[78] 进一步提升吞吐量:将离散扩散模型作为全并行 “草稿生成器”,其输出由大型自回归模型快速验证(必要时进行修正),相比基础自回归生成,速度提升最高达 7.2 倍;
- 视觉-语言模型 Dimple[30] 采用 置信并行解码 (confident parallel decoding) :动态调整每一步揭示的令牌数量,将生成迭代次数减少 1.5 至 7 倍。
总体而言,这些并行解码方法在保留(部分场景下甚至提升)生成质量的同时,大幅缩小了扩散模型与自回归模型之间的推理延迟差距。
4.2 Unmasking / Remasking
解掩码/重掩码
当前主流的开源离散扩散语言模型(如LLaDA[28]、Dream[26])均采用“掩码预测范式”:在每个扩散步骤中,模型会对高置信度令牌进行解掩码,并对不确定位置重新掩码,通过迭代优化序列。因此,解掩码/重掩码策略的选择(即低置信度采样、随机选择或自适应温度)对生成质量和收敛速度均起决定性作用,使其成为最重要的推理调控手段之一。
早期研究 Masked DLM [63] 确立了两种基础策略:随机重掩码与按置信度排序的重掩码。 研究表明,优先处理低置信度位置无需额外成本即可提升生成质量。基于这一发现,Fast-dLLM[44] 提出 置信感知并行解码 :每一步仅对预测概率超过全局阈值的所有位置进行解掩码,在保持准确率的同时实现了最高 13 倍的速度提升。
近期提出的 ReMDM[46] 则设计了一种原理性的推理时重掩码采样器,该采样器可对已解码的令牌重新掩码以进一步优化;通过调整重掩码预算,ReMDM 实现了计算量与质量之间的平滑权衡,并在固定计算量下缩小了与自回归模型的质量差距。
总体而言,这些自适应解掩码/重掩码策略显著提升了扩散语言模型的效率与生成质量,且能与后文将讨论的缓存、步骤蒸馏等独立加速技术无缝集成。
4.3 Guidance
引导技术
引导技术 (Guidance) 是扩散模型中关键的推理手段,其通过将生成轨迹导向期望属性来提升输出质量。在扩散模型中,引导技术泛指所有能修改模型去噪轨迹、使样本满足特定条件(如文本提示、类别标签或风格属性)的方法。
这一理念因 分类器引导”[17] 得以普及:该方法将外部分类器的梯度添加到得分估计中,推动样本向目标类别靠拢。此后不久,“无分类器引导”(classifier-free guidance, CFG)[87] 摒弃了对额外分类器的依赖——模型仅需一次性完成“带条件”与“无条件”两种模式的训练,推理时将两种得分估计结合即可:
其中, 为引导系数,用于平衡对条件的保真度与样本多样性。这一简洁公式现已成为多数文本到图像系统(如Stable Diffusion[8])的核心,并被扩散语言模型采纳以实现“提示控制生成”。
后续研究从多个维度对无分类器引导进行了优化:
- dropout 增强型无分类器引导 (dropout-augmented CFG):平滑质量-多样性曲线;
- 基于粒子的引导 (particle-based guidance):融合多种条件;
- 加权法 (-weighting):重新缩放噪声项以稳定高 值下的采样过程。
在文本领域,新型引导方案进一步将控制范围扩展到结构与语义约束:
- FreeCache[88]:将轻量级自回归验证器与离散扩散语言模型结合,验证器在令牌最终确定前对草稿令牌进行批准(或否决),既保证了文本连贯性,又支持激进的特征缓存;
- DINGO[89]:将正则表达式控制构建为基于确定有限自动机(DFA)的动态规划搜索,在不改变模型分布的前提下确保约束满足。
在其他离散扩散语言模型中,引导技术还可应用于每个扩散步骤,并可选择性地与掩码/重掩码或缓存结合,在保持效率的同时实现对内容(如主题、情感)的调控。总体而言,引导技术已成为扩散模型推理的核心支柱,为使模型输出与用户意图对齐提供了轻量、可调节的手段。
4.4 Efficient Inference
高效推理
近期的主流扩散语言模型[26]、[32]、[85]将标准 Transformer 架构[147] 与扩散过程的逐步随机推理流程相结合。因此,提升扩散语言模型推理速度的研究主要集中于两种互补策略:
- 通过键值 (KV) 缓存、特征缓存等技术降低 Transformer 骨干网络的单步计算开销;
- 通过 步骤蒸馏 等技术减少扩散采样的总步数。
4.4.1 Key–Value Cache
键值缓存
传统键值缓存依赖大型语言模型(LLMs)严格的自回归解码模式,因此不适合扩散语言模型的双向、多步生成范式[48]。但近期研究表明,通过精心设计解码调度,可在扩散模型中充分发挥键值缓存的优势:
- 块级扩散 (Block Diffusion) [76]:提出 块级离散去噪扩散语言模型 (BD3-LMs),该模型以自回归方式对粗粒度块进行文本解码,同时在每个块内部执行扩散过程;块生成完成后,其键值对将被冻结并复用,支持变长生成且实现了可量化的速度提升;
- Fast-dLLM[44]:保留块级视角并新增 无训练近似双缓存 (DualCache),该缓存利用前缀与后缀令牌在连续扩散步骤中键值激活值的近似一致性,在 LLaDA 与 Dream 模型上实现了最高 27 倍的端到端吞吐量提升,且准确率损失低于 1%;
- 延迟键值缓存 (dKV-Cache)[48]:发现令牌表示仅在位置解码后才会稳定,因此设计了“延迟条件缓存”——将键值对延迟一步存储;该设计在上述模型上实现了 2-10 倍的速度提升,且质量损失可忽略不计。
这些结果表明,半自回归调度与延迟缓存技术为扩散模型的双向条件建模与原本为自回归设计的 Transformer 优化手段之间搭建了实用桥梁。
4.4.2 Feature Cache
特征缓存
特征缓存 由 DeepCache[90]首次提出,其利用连续扩散步骤中 U-Net 中间层激活值的高度相似性避免冗余计算。后续研究(-DiT[91]、学习式缓存 (Learning-to-Cache) [92]、FasterCache[93])表明,该原理可无缝迁移到基于 Transformer 的扩散模型中,无需重新训练即可实现相当的速度提升。
随着扩散语言模型的兴起,扩散语言模型缓存 (dLLM-Cache)[47] 将特征缓存扩展到文本领域,其核心是区分两种冗余性:
- 提示令牌(prompt tokens):在整个去噪过程中几乎保持不变;
- 响应令牌(response tokens):仅发生稀疏变化。
基于此,dLLM-Cache 将“长间隔提示缓存”与“自适应短间隔响应缓存”结合——仅当轻量级值验证(V-verify)检测到显著变化时,才刷新响应缓存。该方法在 LLaDA-8B 与 Dream-7B 模型上实现了最高 9 倍的端到端速度提升。
近期提出的 FreeCache[88]进一步优化:缓存已“纯净”令牌的键值/特征投影,仅刷新动态位置,在保持生成保真度的同时将加速比提升至 34 倍。这些进展表明,特征缓存可使扩散语言模型的推理延迟逼近自回归大型语言模型,且无需牺牲输出质量。
4.4.3 Step Distillation
步骤蒸馏
步骤蒸馏 是扩散模型中广泛采用的加速技术,其将典型的千步去噪过程压缩到仅几步(甚至单步),从而大幅缩短推理时间。与前文讨论的无训练方法不同,步骤蒸馏存在离线成本:需先训练一个紧凑的学生网络来模仿教师网络。
早期研究(如渐进式蒸馏 (Progressive Distillation)[95])及后续的 ADD[148]、LADD[149] 通过逐步减半步数或对齐中间分布来保留生成保真度。Di4C[94] 将该框架扩展到离散扩散领域,通过显式蒸馏令牌间相关性,训练出步数为 4-10 步、质量与教师网络相当的学生网络,同时实现约 2 倍的速度提升。
近期的 DLM-One[43] 采用 带对抗正则化的基于得分的蒸馏,训练出可通过单次前向传播生成完整序列的连续扩散语言模型,实现了最高 500倍的加速,且质量接近教师网络。这些研究共同确立了步骤蒸馏在缩小扩散模型与自回归模型推理延迟差距中的核心地位。
5 Multimodel and Unified Approaches
多模态与统一方法
本节探讨将 DLMs 扩展至多模态与统一架构的最新进展。与自回归大型语言模型 (AR LLMs) 类似,扩散语言模型可自然适配多模态输入与输出任务。一种直接的方法是通过预训练视觉编码器接收视觉输入:借鉴自回归领域中 LLaVA[150] 的成功经验,LLaDA-V[29]、LaViDa[96]、Dimple[30] 等模型均采用 视觉编码器提取图像特征,并将其投影到与文本令牌相同的嵌入空间中。
除简单的视觉理解外,扩散语言模型还为统一多模态生成与理解提供了极具潜力的路径。得益于其共享的去噪扩散框架,扩散语言模型天然支持对不同模态的联合建模:通过向量量化变分自编码器 (VQ-VAE) 对视觉输入进行离散化处理,可在统一的令牌空间中完成对多模态输入输出的训练。MMaDA[31]、Fudoki[97]、Muddit[80]等代表性模型均是这一方向的典型案例。
5.1 LLaDA and LLaDA’s Derivatives
LLaDA 及其衍生模型
首先介绍 LLaDA[28] 系列及其衍生模型,这类模型均基于基础 LLaDA 模型的架构与预训练权重构建。其中,LLaDA-V[29] 将视觉编码器与基于多层感知机 (MLP) 的投影器相结合,该投影器可将视觉特征映射到文本令牌的嵌入空间,从而实现有效的视觉指令微调。
借鉴 LLaVA-NeXT[151] 的思路,LLaDA-V 采用三阶段微调策略:
- 第一阶段:仅训练 MLP 投影器,利用 LLaVA 的训练数据将视觉表征与文本嵌入对齐;
- 第二阶段:基于扩散语言模型的目标函数,使用大规模视觉指令数据[152]对模型进行进一步微调;
- 第三阶段:通过对含推理链的问答 (QA) 样本进行训练,提升模型的多模态推理能力。
尽管在纯文本任务上,LLaDA 的骨干网络性能略逊于 LLaMA3-8B[153],但在相同训练数据下,LLaDA-V 在各类基准测试中均展现出更优的性能与可扩展性:不仅缩小了与 Qwen2-VL[154] 的性能差距,还优于混合模态与纯扩散语言模型(如[79]、[155]、[156]),充分证明了扩散架构在多模态理解任务中的有效性。
5.2 LaViDa
LaViDa[96] 提出了一系列基于 LLaDA 与 Dream-7B[26] 的视觉语言模型 (VLM)。该模型同样采用预训练视觉编码器,并通过两阶段训练策略分别训练投影器与微调模型,在解决多模态扩散语言模型的训练与推理挑战方面做出了显著贡献。
在典型的掩码扩散语言模型中,平均仅约 50% 的令牌会参与损失计算,这不仅降低了训练效率,还可能在 VLM 训练中遗漏关键答案令牌,进而导致梯度失配。为此,LaViDa 提出了 互补掩码策略 以实现高效训练:对每个样本生成两个含“不重叠受损片段”的掩码版本,确保所有令牌最终均能参与训练,从而提升样本利用率与梯度流动效率。
在推理阶段,LaViDa 采用 前缀键值缓存 (Prefix KV-Cache) 对视觉令牌与提示令牌的键值对进行缓存,在仅造成微小性能损失的前提下,显著降低了推理延迟,最高加速比达 3.9 倍。此外,该模型还通过 时间步偏移 (timestep shifting) 提前对令牌进行解掩码,进一步提升了生成质量。实验结果表明,LaViDa 的性能可与基于自回归 (AR)的视觉语言模型媲美甚至更优,同时还具备显著的推理加速优势。
5.3 MMaDA
基于 LLaDA,MMaDA[31] 进一步将架构泛化,以同时支持多模态理解与生成任务。与此前模型不同,MMaDA 无需显式视觉编码器:通过向量量化变分自编码器 (VQ-VAE) 将图像 token 化为离散编码,并利用 模态无关的扩散Transformer 对所有模态进行联合建模。这种设计无需模态专用组件,即可实现文本与图像模态的无缝融合。
此外,MMaDA 还采用了 混合长思维链微调策略,使跨模态的思维链推理格式保持对齐;同时,针对扩散语言模型定制了基于统一策略梯度的强化学习算法 UniGRPO,从而实现跨模态推理。在性能上,MMaDA 不仅在文本推理任务中超越了 LLaMA3 等同等规模模型,在多模态理解任务中超越了 Show-o[155],甚至在图像生成任务中优于 SDXL[10] 等专业图像生成模型。
5.4 Dimple
Dimple[30]提出了一种大型多模态扩散语言模型,将视觉编码器与离散扩散语言模型骨干网络相结合。研究人员发现,纯离散扩散训练方法存在显著的不稳定性、性能不佳与严重的长度偏差问题。为克服这些挑战,Dimple提出了一种名为 先自回归后扩散 (Autoregressive-then-Diffusion) 的新型两阶段训练范式:
- 第一阶段:对模型进行标准自回归训练,以实现视觉与语言模态的有效对齐;
- 第二阶段:切换至基于扩散的训练,以恢复模型的并行解码能力。
这种混合策略在确保训练稳定高效的同时,使模型性能达到甚至超越了 LLaVA-NEXT 等当代自回归模型。
在推理阶段,Dimple引入了多种技术以提升效率与可控性:
- 置信解码 (Confident Decoding):基于置信度阈值动态调整每一步生成的令牌数量,减少总生成迭代次数;
- 预填充技术 (Prefilling):成功复现了自回归模型中常用的预填充技术,通过缓存提示令牌实现最高 7 倍的加速,且性能损失极小;
- 结构先验 (Structure Priors):可对响应格式与长度进行精确、细粒度的控制,而这一特性在自回归模型中难以实现。
5.5 D-DiT
双扩散 Transformer (Dual Diffusion Transformer, D-DiT)[79] 是一种大规模全端到端统一多模态扩散模型,支持文本到图像 (T2I) 与图像到文本 (I2T) 双向任务。该模型直接解决了此前扩散模型在视觉理解任务中面临的挑战——这类任务此前主要由自回归模型主导。
D-DiT 的架构灵感来源于多模态扩散 Transformer (MM-DiT),采用双分支 Transformer 分别处理图像与文本令牌,且每一层均通过注意力机制实现模态间的交互。该模型使用冻结的 VAE 处理图像,使用冻结的 T5 编码器处理文本,其核心骨干网络 MM-DiT 则基于预训练 SD3[11] 的权重初始化。
D-DiT 的核心创新在于其 联合训练目标:通过联合优化图像与文本两种模态的损失之和,将图像的连续 latent 空间扩散与文本的离散掩码令牌扩散相结合。与此前需通过自回归组件解码文本 latent 的多模态扩散模型不同,D-DiT 是完全基于扩散的模型,且与其他统一模型相比展现出了极具竞争力的性能。
5.6 UniDisc
统一多模态离散扩散模型 (Unified Multimodal Discrete Diffusion, UniDisc)[98] 是一种面向文本与图像联合建模的统一生成模型,其以离散扩散为基础,作为 AR 方法的替代方案。与前文讨论的 D-DiT 不同,UniDisc 对文本和图像令牌联合执行完整的掩码扩散过程,并采用全注意力机制,旨在学习将掩码令牌序列从共享词汇表映射回清洁令牌序列。
UniDisc 的训练从零开始,采用统一的离散扩散目标函数:对两种模态的令牌进行随机掩码,并通过重加权交叉熵损失对模型进行监督。 该模型的核心优势在于其在条件生成任务中的卓越性能,这在很大程度上归功于对无分类器引导 (classifier-free guidance) 的有效运用。
UniDisc 最显著的能力之一是支持 零样本方式的图像与文本联合补全——这一特性是此前自回归模型或其他统一生成模型无法实现的。研究人员通过将模型参数规模扩展至 1.4B 进行缩放分析,结果表明:UniDisc 在性能与推理时计算效率两方面均优于自回归模型,同时还具备更强的可控性与可编辑性。不过,在达到相同验证损失的前提下,UniDisc 的训练效率低于性能相当的自回归模型。
5.7 Fudoki
Fudoki[97] 是首个完全基于离散流匹配框架构建的通用统一多模态模型,其问世对 AR 模型与 Masked DLMs 的主导地位构成了挑战。与依赖简单掩码加噪过程的模型不同,Fudoki采用了更通用的 度量诱导概率路径 与 动态最优速度,这不仅使加噪过程在语义层面更具意义,还能让模型在迭代优化过程中持续自我修正预测结果。
这种自我修正能力是 Fudoki 与 masked DLMs 的核心区别——在掩码扩散语言模型中,已解掩码的令牌通常是固定的,无法修改。为降低从零训练的高昂成本,Fudoki 从基于自回归的预训练多模态大型语言模型 (MLLM) Janus-1.5B[157] 初始化,随后通过两阶段过程适配到离散流匹配范式。
其架构以 Janus-1.5B 为基础,但采用全注意力掩码以更好地捕捉全局上下文,并移除了时间嵌入层(因模型可从受损输入中隐式推断时间步)。在视觉理解与图像生成任务中,Fudoki 的性能均可与最先进的 AR 模型媲美,同时在推理速度与生成质量之间实现了灵活权衡。此外,当应用测试时推理缩放技术时,该模型性能显著提升,这表明该架构在下一代统一模型研发中具有进一步探索的潜力。
5.8 Muddit模型
Muddit[80]是一种纯统一离散扩散 Transformer,其将强大的文本到图像骨干网络与轻量级文本解码器相结合,在真正统一的架构下实现了灵活且高质量的多模态生成。该模型从Meissonic[145] 的预训练多模态扩散 Transformer (MM-DiT) 初始化,训练过程采用统一的离散扩散目标函数:根据余弦调度对文本和图像令牌进行随机掩码,模型通过重加权交叉熵损失学习预测原始令牌。
借助语义丰富的视觉先验与并行离散扩散的双重优势,Muddit 在生成与理解类基准测试中,性能达到甚至超越了规模显著更大的自回归模型;同时,其相比自回归基准模型实现了数倍加速——这一结果凸显了在初始化得当的情况下,离散扩散方法具备高效性与可扩展性。
6 Performance Study
性能研究
在本节中,我们简要对比了各类 DLMs 与 ARMs 的性能。我们基于多个广泛用于评估扩散语言模型的基准测试展开可视化分析,具体包括:用于通用语言理解的 PIQA(物理常识推理基准)[158] 和 HellaSwag(常识推理基准)[159]、用于代码生成的 HumanEval(代码生成评估基准)[160],以及用于多模态生成与理解的 GenEval(生成质量评估基准)[161]、MME(多模态理解评估基准)[162]、MMMU(多学科多模态理解推理基准)[163] 和 GQA(视觉问答基准)[164]。此外,我们还纳入了 GSM8K[165]——这是扩散语言模型相关文献中用于评估数学推理能力的常用基准测试。相应的性能可视化结果如图 6 所示。
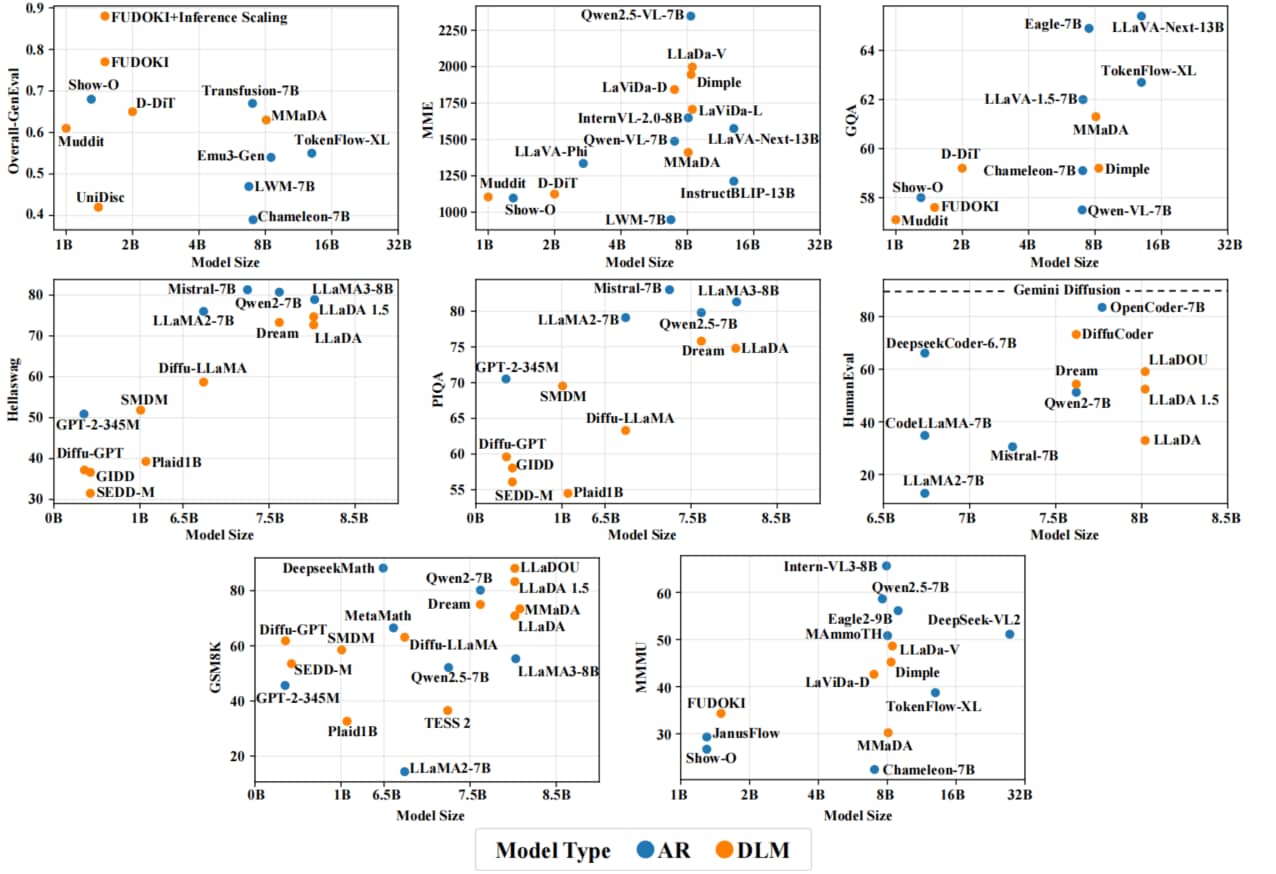
Fig.6: 八个基准测试的性能对比:总体生成评估(Overall-GenEval)、多模态评估(MME)、常识问答(CQA)、Hellaswag、物理推理问答(PIQA)、人类评估(HumanEval)、GSM8K数学题以及多学科多模态理解(MMMU)。每个子图中的横轴代表模型参数量级,纵轴表示对应基准测试下的得分,分数越高反映性能越优。模型类型通过颜色区分:蓝色代表自回归语言模型(AR),橙色代表扩散语言模型(DLM)。
本次研究涉及的扩散语言模型,其参数规模涵盖不足 1B 到 8B。为便于对比,我们还报告了相同参数规模下代表性自回归模型的性能。性能数据主要来源于原始文献;若原始文献中未提供相关结果,则参考后续发表的、包含可比评估结果的研究。
研究结果表明,DLMs 的性能总体上可与相同参数规模的 ARMs 媲美:
- 在 PIQA、HellaSwag 等通用语言理解基准测试中,LLaDA 等扩散语言模型的性能略低于或持平于 LLaMA2[4]、Qwen2.5[166] 等自回归模型;
- 但在 GSM8K、GPQA[167]、MATH[168] 等数学与科学相关基准测试中,扩散语言模型表现更优,其中 LLaDA、Dream 等模型持续优于相同规模的自回归模型;
- 在多模态任务中,MMaDA[31]、LLaDA-V[29] 等扩散语言模型往往超越基于自回归架构的多模态模型,凸显了扩散语言模型在统一多模态推理与跨模态推理中的潜力;
- 在代码生成任务中,扩散语言模型也展现出极具竞争力的能力。值得注意的是,在开源模型中,DiffuCoder[84] 在 HumanEval 基准测试中取得了极具竞争力的性能,这体现了扩散语言模型在结构化、高逻辑性领域的应用潜力;
- 此外,Gemini Diffusion[33]、Mercury[32] 等闭源扩散语言模型在所有扩散语言模型中取得了最先进的结果,可与 GPT-4o 等顶级自回归模型相媲美。
考虑到当前大多数扩散语言模型的训练所使用的训练数据和计算资源相对有限,上述结果表明,在众多实际应用场景中,扩散语言模型具有成为自回归模型可行替代方案的巨大潜力。
7 Application on Downstream Tasks
下游任务应用
7.1 Conventional NLP Tasks
传统自然语言处理任务
在用于通用语言生成的大规模扩散语言模型(DLMs)出现之前,扩散语言模型已被应用于各类传统自然语言处理(NLP)任务,例如文本分类[99]、命名实体/场景识别[100]、[101]、情感分析[102]、文档摘要[103]、[104]、风格迁移[110]、[169]、约束生成[111]–[115]以及机器翻译[116]、[170]等。
ROIC-DM[99] 是首个将扩散模型适配于稳健文本分类与推理任务的研究。该模型将扩散过程直接应用于类别标签,并以输入文本为条件约束去噪过程;此外,还可通过将传统语言模型作为“顾问”融入其中,进一步提升模型性能。DiffusionNER[100] 将命名实体识别 (Named Entity Recognition) 构建为边界去噪任务:对实体的起始和终止边界应用扩散过程,通过迭代优化从随机噪声中生成实体跨度。
在场景文本识别任务中,IPAD[101] 提出了一种并行迭代网络,将该任务构建为条件文本生成问题;该网络采用离散扩散与“先易后难”解码方法,有效平衡了识别准确率与推理速度。在基于方面的情感分析 (aspect-based sentiment analysis) 任务中,DiffusionABSA[102]采用扩散模型逐步渐进地提取情感方面。
DiffuSum[103] 为抽取式摘要任务提出了一种新范式:利用扩散模型直接生成目标摘要句的表示,随后通过抽取与这些生成表示最匹配的文档句子,形成最终摘要。针对法律文档摘要任务,TermDiffuSum[104] 提出了一种术语引导的扩散模型——通过多因素融合噪声加权调度,优先处理包含法律术语的句子。
在关键词提取任务中,Diff-KPE[105] 借助变分信息瓶颈 (Variational Information Bottleneck,VIB) 引导文本扩散过程,生成并注入关键词信息,从而增强短语表示。IPED[106] 将关系三元组提取视为一项隐式块扩散任务。EdiText[107] 则提出了一种可控的粗到精文本编辑框架,通过整合基于 SDEdit 的技术与新型自条件机制,实现对文本编辑的精确控制。为生成更具针对性的共情回复,DIFFUSEMP[108] 采用条件扩散模型,该模型由多粒度控制信号(如意图和语义框架)引导,这些信号通过特殊的掩码策略进行整合。DiffuDetox[109] 采用混合扩散方法实现文本净化:将用于降低毒性的条件模型与用于确保输出文本流畅性的无条件模型相结合。
研究表明,经过微调的 DiffuSeq 模型在细粒度文本风格迁移任务上实现了最先进的性能[169];而 ParaGuide[110] 则提出了一种更灵活的即插即用框架——在推理阶段,通过现成的分类器和风格嵌入器,对“以释义为条件”的扩散模型进行引导。为生成流畅多样且无重复的段落,PLANNER[111] 将“潜在扩散规划模块”与“自回归解码模块”相结合:前者用于生成段落语义嵌入,后者用于生成最终文本。
针对约束极强的诗歌生成任务,PoetryDiffusion[115] 采用独特的任务拆分方式:由扩散模型负责生成语义内容,同时由一个独立训练的新型韵律控制器 (metrical controller) 来强制执行格式、押韵等结构规则。在机器翻译领域,XDLM[116] 开创性地为扩散模型设计了跨语言预训练目标,使模型能在预训练阶段有效学习语言间的映射关系。
DiffusionRet[117] 提出了一种两阶段生成式检索方法:首先利用扩散模型从查询语句生成伪文档,随后将该伪文档作为输入,通过基于 n 元语法 (n-gram) 的模型检索最终文档。DIFND[118] 采用扩散模型生成辟谣证据,并结合多智能体多模态大型语言模型 (MLLM) 系统执行“链式辟谣推理”,以提升多模态假新闻检测的准确率与可解释性。
7.2 Code Generation
代码生成
尽管 DLMs 很少被明确设计用于代码生成,但其具备的全局规划与迭代优化能力,却特别适合代码生成的“非序列性”特点。目前已出现专为该领域设计的基础模型,例如 7B 参数的开源模型 DiffuCoder[84]。
对 DiffuCoder 的分析揭示了其独特的解码行为,例如在较高温度 (temperature) 设置下,生成顺序会变得更灵活。该模型还提出了一种名为 coupled-GRPO 的新型采样方案:为训练中使用的补全序列构建互补掩码噪声,这一设计显著提升了模型在代码生成任务上的性能。
在推理能力层面,DCoLT[82] 将整个逆向扩散过程视为一种非线性“横向”思维:通过基于结果的 RL 与解掩码策略模块,该模型在复杂代码生成任务上取得了优异成绩。扩张解掩码调度器(Dilated Unmasking Scheduler, DUS)[119]则提出了一种 仅推理、无规划器 的方法:通过非相邻模式对令牌进行解掩码,以最小化每个去噪步骤中联合熵增益的上界,在改善速度-质量权衡关系的同时,在代码生成任务上取得了良好效果。
为体现扩散语言模型在速度上的实际应用潜力,Mercury Coder[32]作为一款商用级扩散模型,实现了最先进的吞吐量——在主流代码基准测试中,其性能与速度优化后的 ARMs 相当,但速度却比后者快至多 10 倍。
7.3 Biological and Scientific Applications
生物与科学应用
TransDLM[120] 以目标属性的文本描述为引导进行分子优化,从而避免误差传播。另一类以文本为引导的方法 TGM-DLM[121] 则聚焦于分子生成:通过对 SMILES 字符串(简化分子输入线输入系统,用于表示分子结构的文本格式)的令牌嵌入进行集体迭代更新来生成分子。在不依赖额外数据资源的情况下,TGM-DLM 的生成性能超过了 MolT5-Base模型。
DRAKES[125] 为离散扩散模型提出了一种基于 RL 的微调方法:利用 Gumbel-Softmax 技巧实现奖励反向传播,适用于 DNA 与蛋白质设计任务。在蛋白质建模领域,ForceGen[126] 借助蛋白质语言扩散模型生成符合复杂非线性力学属性设计目标的序列,从而实现从头蛋白质设计。
MeMDLM[122] 通过微调 ESM-2 蛋白质语言模型,提出了一种用于从头膜蛋白设计的掩码扩散语言模型,可生成新颖且真实的跨膜序列。受 LLaDA 启发,DSM[127] 提出了一种兼具高质量表征学习与高效蛋白质生成设计能力的模型。
DPLM[123] 是一款多功能蛋白质语言模型,对蛋白质序列具有强大的生成与预测能力,且在表征学习方面表现优异。DPLM2[128] 进一步将该模型扩展为多模态蛋白质基础模型,可同时处理蛋白质序列与结构:通过将 3D 结构坐标转换为离散令牌,DPLM2 学习这两种模态的联合分布,不仅能同时协同生成匹配的蛋白质序列及其 3D 结构,还支持蛋白质折叠、逆折叠等条件任务。
CFP-GEN[124]是一款专为 组合功能蛋白质生成 设计的新型扩散语言模型。该模型通过整合功能、序列、结构等多模态约束,助力从头蛋白质设计;不仅支持高通量生成功能与天然蛋白质相当的新型蛋白质,还在多功能蛋白质设计中实现了较高的成功率。
8 Challenges and Future Directions
尽管 DLMs 已在各类任务中展现出巨大潜力,但仍存在若干关键挑战,限制了其实际部署与更广泛应用。本节将概述并探讨需进一步研究与创新的关键领域。
8.1 Major Challenges
8.1.1 Parallelism–Performance Trade-off
并行性-性能权衡
扩散语言模型的设计目标是并行生成多个 tokens。然而,这种并行性往往需要以生成质量和连贯性为代价。在离散扩散语言模型中,单一步骤同时对多个令牌进行解掩码会增加去噪负担,可能导致误差累积。核心问题 在于 tokens 间的相互依赖关系,这一问题被称为 Parallel Decoding Curse [44]。当模型同时预测多个令牌时,会为每个位置生成概率分布并独立采样,无法考虑位置间的依赖关系。
举一个简单例子:若训练数据仅包含两个序列(“ABABAB” 和 “BABABA”),从统计上看,“A” 和 “B” 在训练数据的每个位置出现频率相同,这会导致扩散语言模型在预测时为两者分配相近的概率。而在 ARMs 中,一旦生成第一个 “A”,模型接下来大概率会预测 “B”,从而保持序列连贯性;相比之下,并行生成 tokens 的 DLMs 可能会为第一个和第二个位置独立采样 “A”,生成 “AAABBA” 这类偏离有效训练模式的序列。实证研究表明,该问题对扩散语言模型的性能影响显著,尤其是在减少去噪步数时[27]。图 7 对这一现象进行了可视化展示。未来研究可聚焦于缓解这一权衡关系,潜在方向包括引入结构化约束、更明确地建模令牌间依赖关系,或优化采样策略以提升并行生成时的序列连贯性。
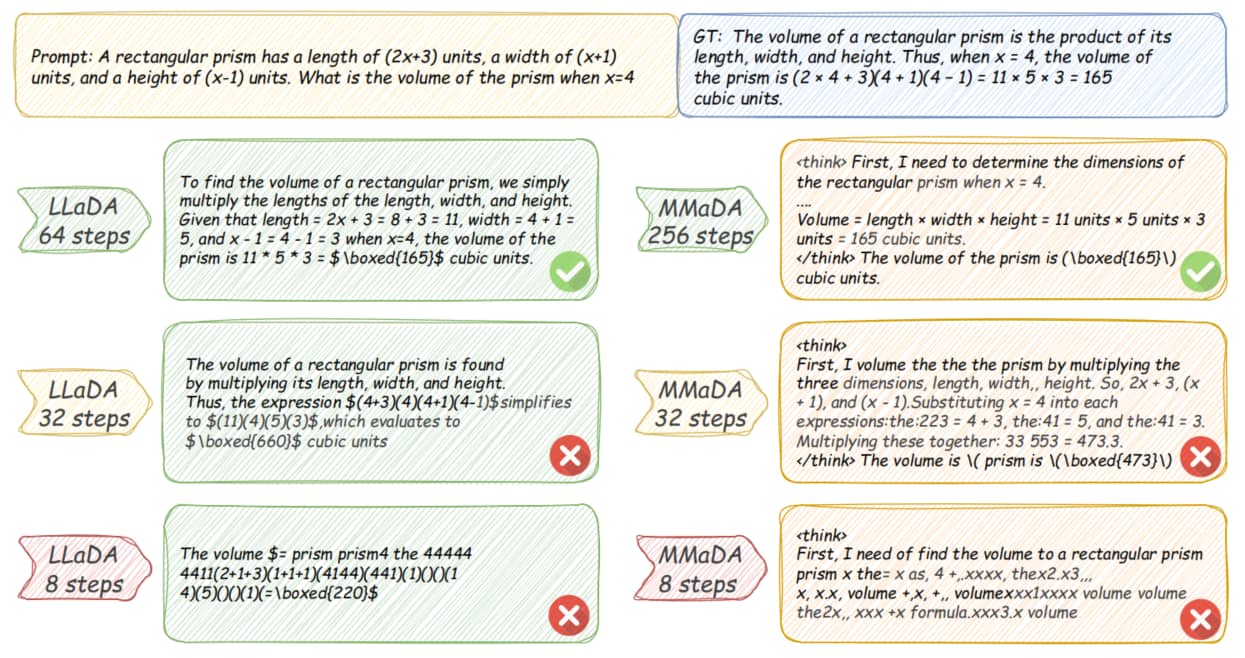
Fig.7: LLaDA[28] 与 MMaDA[31] 在不同去噪步数设置下的生成结果。需注意 LLaDA 和 MMaDA 的生成长度分别设置为 128 tokens 和 256 tokens。两种模型仅当每步解掩1 or 2 tokens 时才能生成正确连贯的响应。随着步数减少和并行度增加,生成的响应要么错误,要么缺乏流畅性与一致性。这揭示了深度学习模型在并行度与输出质量之间存在的权衡关系。为简化展示,我们省略了 MMaDA 在 256 steps 时的部分思维过程。
8.1.2 Infrastructure
基础设施
ARMs 的训练、微调和推理已通过开源、高度优化的库与框架(如 Hugging Face Transformers[171])得到显著简化与加速,但 DLMs 在这方面仍相对滞后。目前,主流机器学习生态系统对 DLMs 的原生支持极少甚至完全没有,给研究人员与开发者带来了实际挑战。此外,在推理阶段,DLMs 缺乏类似 vLLM[172] 的成熟开源部署基础设施,难以实现高效服务。
8.1.3 Long Sequence and Dynamic-Length Generation
长序列与动态长度生成
DLMs 通常在基于扩散的目标函数下,针对固定长度序列进行去噪训练,这使其在推理阶段难以泛化到更长或动态长度的序列。目前大多数 DLMs 的最大上下文长度限制在 4096 tokens,且 ARMs 中广泛用于长序列的外推技术,在 DLMs 领域仍未得到充分探索。这一限制阻碍了 DLMs 在需要长上下文理解或复杂推理的任务中的应用。此外,DLMs 通常需要在推理阶段预先确定生成长度,使其难以适配动态长度生成场景。尽管 DLMs 可预测 [EOS] token(句末令牌)并省略后续生成的 tokens,但无论生成在逻辑上是否已结束,整个序列仍会在整个去噪过程中被完整更新,这导致了不必要的计算开销。
与此同时,Masked DLMs 在每个去噪步骤中均采用 全双向注意力机制,每一步的计算复杂度为 (其中 为序列长度)。假设每一步解掩码的 token 数量固定,去噪步骤的总次数会随 线性增长,最终导致整体推理复杂度达到 。若缺乏键值缓存 (KV-Cache) 等架构层面的优化,这种三次方时间复杂度会严重限制 DLMs 在实际应用中处理长序列生成任务的可扩展性。
8.1.4 Scalability
可扩展性
对于 DLMs 而言,可扩展性仍是一个未被充分探索的挑战,尤其与 ARMs 相比差距明显。尽管 DLMs 在部分指标与基准测试中展现出良好潜力,但其规模尚未达到 ARMs 的水平:目前公开可用的最大 DLMs 仅含约 8B 参数,远小于已突破千亿甚至万亿参数规模的主流自回归模型(如Llama-3.1-405B[153]、DeepSeek-V3-671B-A37B MoE[16]、Qwen3-235B-A22B MoE[173]、Kimi K2-1T-A32B MoE[174]等)。即便在闭源领域,Mercury、Gemini Diffusion等 DLMs 在各类基准测试中,性能也仍落后于最先进的自回归模型。
此外,现有许多 DLMs 要么基于预训练自回归模型初始化,要么以基础 DLMs (如LLaDA)为基础、使用有限数据集训练,这进一步限制了其可扩展性与性能上限。因此, DLMs 的进一步规模化能力仍需验证与探索。
8.2 未来方向
尽管面临上述挑战,DLMs 仍为未来研究提供了诸多极具潜力的方向。下文将简要概述几个尚未充分探索、且可能显著推动该领域发展的方向与机遇:
- 训练效率 (Training Efficiency):当前 DLMs 的训练效率普遍低于自回归模型,原因包括损失计算过程中令牌利用率有限等。未来研究可探索混合 DLMs 架构或改进训练方案,以实现与自回归模型相当甚至更优的训练效率。
- 量化与二值化 (Quantization and Binaryization)(Low-bit DLMs ):低比特量化与二值化技术在自回归模型中已得到广泛研究,但在 DLMs 中仍未充分探索。将这些技术适配到扩散范式中,有望提升推理速度并降低内存消耗,为 DLMs 在实际系统中的部署提供便利。
- 剪枝与蒸馏 (Pruning and Distillation):剪枝、知识蒸馏等模型压缩技术已成功应用于自回归模型,有效减小了模型规模并降低了推理成本。将这些技术应用于 DLMs ,可提升其部署能力,尤其适用于资源受限或延迟敏感的场景。
- 多模态统一推理 (Multimodal Unified Reasoning):尽管近期多模态 DLMs 在跨模态理解与生成任务中展现出令人印象深刻的能力,但多数模型仍局限于单次单模态推理。未来可聚焦于构建“真正一体化”的统一 DLMs ,使其能够跨多个模态执行复杂推理。
- 基于 DLMs 的智能体 (DLM-based Agents):DLMs 在驱动智能体方面的潜力仍未被充分挖掘。借助其双向上下文建模、并行解码与迭代优化能力,基于 DLMs 的智能体有望在动态环境中具备更高的灵活性与适应性,成为传统基于自回归模型的智能体方案的有力替代选择。
9 Conclusion
本综述对 DLMs 的整体领域进行了深入概述。我们阐述了 DLMs 的基本原理、分类体系与建模范式,并将其与主流自回归模型进行对比,突出了 DLMs 的独特特征与优势。我们进一步探索了训练与推理的设计空间,涵盖了旨在提升生成质量与效率的各类训练策略及推理技术。此外,我们还重点介绍了多模态 DLMs 的最新进展,展示了其处理多样化数据模态的能力。最后,我们讨论了该领域存在的局限性与挑战,并概述了具有前景的未来研究方向。
我们希望本综述能为对基于扩散的语言建模感兴趣的研究人员提供全面参考,为其了解该领域的当前状况与未来前景提供有价值的见解。我们也鼓励研究人员在这一充满活力的研究领域中进一步探索与创新,推动 DLMs 不断发展,突破语言理解与生成的边界。
参考文献
-
[1] Language models are few-shot learners
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al. Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020. -
[2] Gpt-4 technical report
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al. arXiv preprint, arXiv:2303.08774, 2023. -
[3] Palm: Scaling language modeling with pathways
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann et al. Journal of Machine Learning Research, vol. 24, no. 240, pp. 1–113, 2023. -
[4] Llama: Open and efficient foundation language models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar et al. arXiv preprint, arXiv:2302.13971, 2023. -
[5] Qwen technical report
J. Bai, S. Bai, Y. Chu, Z. Cui, K. Dang, X. Deng, Y. Fan, W. Ge, Y. Han, F. Huang et al. arXiv preprint, arXiv:2309.16609, 2023. -
[6] A survey of large language models
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong et al. arXiv preprint, arXiv:2303.18223, vol. 1, no. 2, 2023. -
[7] Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi et al. arXiv preprint, arXiv:2501.12948, 2025. -
[8] High-resolution image synthesis with latent diffusion models
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10684–10695. -
[9] Photorealistic text-to-image diffusion models with deep language understanding
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al. Advances in neural information processing systems, vol. 35, pp. 36479–36494, 2022. -
[10] Sdxl: Improving latent diffusion models for high-resolution image synthesis
D. Podell, J. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, Z. Penna, and R. Rombach. in The Twelfth International Conference on Learning Representations. -
[11] Scaling rectified flow transformers for high-resolution image synthesis
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y. Levi, D. Lorenz, A. Sauer, F. Boesel et al. in Forty-first international conference on machine learning, 2024. -
[12] Video generation models as world simulators
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y. Guo, L. Jing, D. Schnurr, J. Taylor, T. Luhman, E. Luhman et al. OpenAI Blog, vol. 1, p. 8, 2024. -
[13] Improving language understanding by generative pre-training
A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al. 2018. -
[14] Language models are unsupervised multitask learners
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al. OpenAI blog, vol. 1, no. 8, p. 9, 2019. -
[15] Gemini: a family of highly capable multimodal models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican et al. arXiv preprint, arXiv:2312.11805, 2023. -
[16] Deepseek-v3 technical report
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan et al. arXiv preprint, arXiv:2412.19437, 2024. -
[17] Diffusion models beat gans on image synthesis
P. Dhariwal and A. Nichol. Advances in neural information processing systems, vol. 34, pp. 8780–8794, 2021. -
[18] Denoising diffusion probabilistic models
J. Ho, A. Jain, and P. Abbeel. Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020. -
[19] Denoising diffusion implicit models
J. Song, C. Meng, and S. Ermon. arXiv preprint, arXiv:2010.02502, 2020. -
[20] Score-based generative modeling through stochastic differential equations
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. in International Conference on Learning Representations. -
[21] Flow straight and fast: Learning to generate and transfer data with rectified flow
X. Liu, C. Gong et al. in The Eleventh International Conference on Learning Representations. -
[22] Diffusion-lm improves controllable text generation
X. Li, J. Thickstun, I. Gulrajani, P. S. Liang, and T. B. Hashimoto. Advances in neural information processing systems, vol. 35, pp. 4328–4343, 2022. -
[23] Self-conditioned embedding diffusion for text generation
R. Strudel, C. Tallec, F. Altché, Y. Du, Y. Ganin, A. Mensch, W. Grathwohl, N. Savinov, S. Dieleman, L. Sifre et al. arXiv preprint, arXiv:2211.04236, 2022. -
[24] Structured denoising diffusion models in discrete state-spaces
J. Austin, D. D. Johnson, J. Ho, D. Tarlow, and R. Van Den Berg. Advances in neural information processing systems, vol. 34, pp. 17981–17993, 2021. -
[25] Diffusionbert: Improving generative masked language models with diffusion models
Z. He, T. Sun, Q. Tang, K. Wang, X. Huang, and X. Qiu. in The 61st Annual Meeting Of The Association For Computational Linguistics, 2023. -
[26] Dream 7b
J. Ye, L. Xie, L. Zheng, J. Gao, Z. Wu, X. Jiang, Z. Li, and Z. Kong. 2025. [Online]. Available: https://hkunlp.github.io/blog/2025/dream -
[27] Scaling diffusion language models via adaptation from autoregressive models
S. Gong, S. Agarwal, Y. Zhang, J. Ye, L. Zheng, M. Li, C. An, P. Zhao, W. Bi, J. Han et al. in The Thirteenth International Conference on Learning Representations. -
[28] Large language diffusion models
S. Nie, F. Zhu, C. Li, X. Zhang, J. Ou, J. Hu, J. Zhou, Y. Lin, J.-R. Wen, and Z. You. arXiv preprint, arXiv:2502.09992, 2025. -
[29] Llada-v: Large language diffusion models with visual instruction tuning
Z. You, S. Nie, X. Zhang, J. Hu, J. Zhou, Z. Lu, J.-R. Wen, and C. Li. arXiv preprint, arXiv:2505.16933, 2025. -
[30] Dimple: Discrete diffusion multimodal large language model with parallel decoding
R. Yu, X. Ma, and X. Wang. arXiv preprint, arXiv:2505.16990, 2025. -
[31] Mmada: Multimodal large diffusion language models
L. Yang, Y. Tian, B. Li, X. Zhang, K. Shen, Y. Tong, and M. Wang. arXiv preprint, arXiv:2505.15809, 2025. -
[32] Mercury: Ultra-fast language models based on diffusion
I. Labs, S. Khanna, S. Kharbanda, S. Li, H. Varma, E. Wang, S. Birnbaum, Z. Luo, Y. Miraoui, A. Palrecha et al. arXiv preprint, arXiv:2506.17298, 2025. -
[33] Gemini diffusion
DeepMind. 2024, accessed: 2025-07-09. https://deepmind.google.com/technologies/gemini -
[34] Energy-based diffusion language models for text generation
M. Xu, T. Gehner, K. Kreis, W. Nie, Y. Xu, J. Leskovec, S. Ermon, and A. Vahdat. arXiv preprint, arXiv:2410.21357, 2024. -
[35] Beyond autoregression: Fast llms via self-distillation through time
J. Deschenaux and C. Gulcehre. in The Thirteenth International Conference on Learning Representations. -
[36] Transfer learning for text diffusion models
K. Han, K. Kenealy, A. Barua, N. Fiedel, and N. Constant. arXiv preprint, arXiv:2401.17181, 2024. -
[37] The diffusion duality
S. S. Sahoo, J. Deschenaux, A. Gokaslan, G. Wang, J. Chiu, and V. Kuleshov. arXiv preprint, arXiv:2506.10892, 2025. -
[38] Non-markovian discrete diffusion with causal language models
Y. Zhang, S. He, D. Levine, L. Zhao, D. Zhang, S. A. Rizvi, E. Zappala, R. Ying, and D. van Dijk. arXiv preprint, arXiv:2502.09767, 2025. -
[39] Inference-time scaling of diffusion language models with particle gibbs sampling
M. Dang, J. Han, M. Xu, K. Xu, A. Srivastava, and S. Ermon. arXiv preprint, arXiv:2507.08390, 2025. -
[40] Anchored diffusion language model
L. Rout, C. Caramanis, and S. Shakkottai. arXiv preprint, arXiv:2505.18456, 2025. -
[41] Deepseekmath: Pushing the limits of mathematical reasoning in open language models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu et al. arXiv preprint, arXiv:2402.03300, 2024. -
[42] dl: Scaling reasoning in diffusion large language models via reinforcement learning
S. Zhao, D. Gupta, Q. Zheng, and A. Grover. arXiv preprint, arXiv:2504.12216, 2025. -
[43] Dlm-one: Diffusion language models for zero-step sequence generation
T. Chen, S. Zhang, and M. Zhou. arXiv e-prints, pp. arXiv-2506, 2025. -
[44] Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding
C. Wu, H. Zhang, S. Xue, Z. Liu, S. Diao, L. Zhu, P. Luo, S. Han, and E. Xie. arXiv preprint, arXiv:2505.22618, 2025. -
[45] Accelerating diffusion llms via adaptive parallel decoding
D. Israel, G. V. d. Broeck, and A. Grover. arXiv preprint, arXiv:2506.00413, 2025. -
[46] Remasking discrete diffusion models with inference-time scaling
G. Wang, Y. Schiff, S. S. Sahoo, and V. Kuleshov. ICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy. -
[47] dllm-cache: Accelerating diffusion large language models with adaptive caching
Z. Liu, Y. Yang, Y. Zhang, J. Chen, C. Zou, Q. Wei, S. Wang, and L. Zhang. arXiv preprint, arXiv:2506.06295, 2025. -
[48] dkv-cache: The cache for diffusion language models
X. Ma, R. Yu, G. Fang, and X. Wang. arXiv preprint, arXiv:2505.15781, 2025. -
[49] Composable text controls in latent space with odes
G. Liu, Z. Feng, Y. Gao, Z. Yang, X. Liang, J. Bao, X. He, S. Cui, Z. Li, and Z. Hu. arXiv preprint, arXiv:2208.00638, 2022. -
[50] Diffuseq: Sequence to sequence text generation with diffusion models
S. Gong, M. Li, J. Feng, Z. Wu, and L. Kong. The Eleventh International Conference on Learning Representations. -
[51] Continuous diffusion for categorical data
S. Dieleman, L. Sartran, A. Roshannai, N. Savinov, Y. Ganin, P. H. Richemond, A. Doucet, R. Strudel, C. Dyer, C. Durkan et al. arXiv preprint, arXiv:2211.15089, 2022. -
[52] Empowering diffusion models on the embedding space for text generation
Z. Gao, J. Guo, X. Tan, Y. Zhu, F. Zhang, J. Bian, and L. Xu. arXiv preprint, arXiv:2212.09412, 2022. -
[53] Latent diffusion for language generation
J. Lovelace, V. Kishore, C. Wan, E. Shekhtman, and K. Q. Weinberger. Advances in Neural Information Processing Systems, vol. 36, pp. 56998–57025, 2023. -
[54] Text generation with diffusion language models: A pre-training approach with continuous paragraph denoise
Z. Lin, Y. Gong, Y. Shen, T. Wu, Z. Fan, C. Lin, N. Duan, and W. Chen. International Conference on Machine Learning. PMLR, 2023, pp. 21051–21064. -
[55] Infodiffusion: Information entropy aware diffusion process for non-autoregressive text generation
R. Wang, W. Li, and P. Li. Findings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 13757–13770. -
[56] Unified generation, reconstruction, and representation: Generalized diffusion with adaptive latent encoding-decoding
G. Liu, Y. Wang, Z. Feng, Q. Wu, L. Tang, Y. Gao, Z. Li, S. Cui, J. Mcauley, Z. Yang et al. International Conference on Machine Learning. PMLR, 2024, pp. 31964–31993. -
[57] Smoothie: Smoothing diffusion on token embeddings for text generation
A. Shabalin, V. Meshchaninov, and D. Vetrov. arXiv preprint, arXiv:2505.18853, 2025. -
[58] Tess: Text-to-text self-conditioned simplex diffusion
R. K. Mahabadi, H. Ivison, J. Tae, J. Henderson, I. Beltagy, M. E. Peters, and A. Cohan. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 2347–2361. -
[59] Tess 2: A large-scale generalist diffusion language model
J. Tae, H. Ivison, S. Kumar, and A. Cohan. arXiv preprint, arXiv:2502.13917, 2025. -
[60] Latent diffusion energy-based model for interpretable text modelling
P. Yu, S. Xie, X. Ma, B. Jia, B. Pang, R. Gao, Y. Zhu, S.-C. Zhu, and Y. N. Wu. International Conference on Machine Learning. PMLR, 2022, pp. 25702–25720. -
[61] A reparameterized discrete diffusion model for text generation
L. Zheng, J. Yuan, L. Yu, and L. Kong. First Conference on Language Modeling. -
[62] Simplified and generalized masked diffusion for discrete data
J. Shi, K. Han, Z. Wang, A. Doucet, and M. Titsias. Advances in neural information processing systems, vol. 37, pp. 103131–103167, 2024. -
[63] Simple and effective masked diffusion language models
S. Sahoo, M. Arriola, Y. Schiff, A. Gokaslan, E. Marroquin, J. Chiu, A. Rush, and V. Kuleshov. Advances in Neural Information Processing Systems, vol. 37, pp. 130136–130184, 2024. -
[64] Diffusion language models can perform many tasks with scaling and instruction-finetuning
J. Ye, Z. Zheng, Y. Bao, L. Qian, and Q. Gu. arXiv preprint, arXiv:2308.12219, 2023. -
[65] Diffusion-nat: Self-prompting discrete diffusion for non-autoregressive text generation
K. Zhou, Y. Li, W. X. Zhao, and J.-R. Wen. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 1438–1451. -
[66] Likelihood-based diffusion language models
I. Gulrajani and T. B. Hashimoto. Advances in Neural Information Processing Systems, vol. 36, pp. 16693–16715, 2023. -
[67] Discrete diffusion modeling by estimating the ratios of the data distribution
A. Lou, C. Meng, and S. Ermon. International Conference on Machine Learning. PMLR, 2024, pp. 32819–32848. -
[68] Your absorbing discrete diffusion secretly models the conditional distributions of clean data
J. Ou, S. Nie, K. Xue, F. Zhu, J. Sun, Z. Li, and C. Li. The Thirteenth International Conference on Learning Representations, 2024. -
[69] Discrete flow matching
I. Gat, T. Remez, N. Shaul, F. Kreuk, R. T. Chen, G. Synnaeve, Y. Adi, and Y. Lipman. Advances in Neural Information Processing Systems, vol. 37, pp. 133345–133385, 2024. -
[70] Think while you generate: Discrete diffusion with planned denoising
S. Liu, J. Nam, A. Campbell, H. Stark, Y. Xu, T. Jaakkola, and R. Gomez-Bombarelli. The Thirteenth International Conference on Learning Representations, 2024. -
[71] Beyond autoregression: Discrete diffusion for complex reasoning and planning
J. Ye, J. Gao, S. Gong, L. Zheng, X. Jiang, Z. Li, and L. Kong. arXiv preprint, arXiv:2410.14157, 2024. -
[72] Generalized interpolating discrete diffusion
D. von Rütte, J. Fluri, Y. Ding, A. Orvieto, B. Schölkopf, and T. Hofmann. Forty-second International Conference on Machine Learning, 2025. -
[73] Longllada: Unlocking long context capabilities in diffusion llms
X. Liu, Z. Liu, Z. Huang, Q. Guo, Z. He, and X. Qiu. arXiv preprint, arXiv:2506.14429, 2025. -
[74] Ssd-lm: Semi-autoregressive simplex-based diffusion language model for text generation and modular control
X. Han, S. Kumar, and Y. Tsvetkov. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 11575–11596. -
[75] Ar-diffusion: Auto-regressive diffusion model for text generation
T. Wu, Z. Fan, X. Liu, H.-T. Zheng, Y. Gong, J. Jiao, J. Li, J. Guo, N. Duan, W. Chen et al. Advances in Neural Information Processing Systems, vol. 36, pp. 39957–39974, 2023. -
[76] Block diffusion: Interpolating between autoregressive and diffusion language models
M. Arriola, A. Gokaslan, J. T. Chiu, Z. Yang, Z. Qi, J. Han, S. S. Sahoo, and V. Kuleshov. The Thirteenth International Conference on Learning Representations. -
[77] Ctrldiff: Boosting large diffusion language models with dynamic block prediction and controllable generation
C. Huang and H. Tang. arXiv preprint, arXiv:2505.14455, 2025. -
[78] Speculative diffusion decoding: Accelerating language generation through diffusion
J. K. Christopher, B. R. Bartoldson, T. Ben-Nun, M. Cardei, B. Kailkhura, and F. Fioretto. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 12042–12059. -
[79] Dual diffusion for unified image generation and understanding
Z. Li, H. Li, Y. Shi, A. B. Farimani, Y. Kluger, L. Yang, and P. Wang. Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 2779–2790. -
[80] Muddit: Liberating generation beyond text-to-image with a unified discrete diffusion model
Q. Shi, J. Bai, Z. Zhao, W. Chai, K. Yu, J. Wu, S. Song, Y. Tong, X. Li, X. Li et al. arXiv preprint, arXiv:2505.23606, 2025. -
[81] Diffusion of thought: Chain-of-thought reasoning in diffusion language models
J. Ye, S. Gong, L. Chen, L. Zheng, J. Gao, H. Shi, C. Wu, X. Jiang, Z. Li, W. Bi et al. Advances in Neural Information Processing Systems, vol. 37, pp. 105345–105374, 2024. -
[82] Reinforcing the diffusion chain of lateral thought with diffusion language models
Z. Huang, Z. Chen, Z. Wang, T. Li, and G.-J. Qi. arXiv preprint, arXiv:2505.10446, 2025. -
[83] Fine-tuning discrete diffusion models with policy gradient methods
O. Zekri and N. Boullé. arXiv preprint, arXiv:2502.01384, 2025. -
[84] Diffucoder: Understanding and improving masked diffusion models for code generation
S. Gong, R. Zhang, H. Zheng, J. Gu, N. Jaitly, L. Kong, and Y. Zhang. arXiv preprint, arXiv:2506.20639, 2025. -
[85] Llada 1.5: Variance-reduced preference optimization for large language diffusion models
F. Zhu, R. Wang, S. Nie, X. Zhang, C. Wu, J. Hu, J. Zhou, J. Chen, Y. Lin, J.-R. Wen et al. arXiv preprint, arXiv:2505.19223, 2025. -
[86] Accelerating diffusion large language models with slowfast: The three golden principles
Q. Wei, Y. Zhang, Z. Liu, D. Liu, and L. Zhang. arXiv preprint, arXiv:2506.10848, 2025. -
[87] Adaptive classifier-free guidance via dynamic low-confidence masking
P. Li, S. Yan, J. Tsai, R. Zhang, R. An, Z. Guo, and X. Gao. arXiv preprint, arXiv:2505.20199, 2025. -
[88] Accelerating diffusion language model inference via efficient kv caching and guided diffusion
Z. Hu, J. Meng, Y. Akhauri, M. S. Abdelfattah, J.-s. Seo, Z. Zhang, and U. Gupta. arXiv preprint, arXiv:2505.21467, 2025. -
[89] Dingo: Constrained inference for diffusion llms
T. Suresh, D. Banerjee, S. Ugare, S. Misailovic, and G. Singh. ICML 2025 Workshop on Reliable and Responsible Foundation Models. -
[90] Deepcache: Accelerating diffusion models for free
X. Ma, G. Fang, and X. Wang. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 15762–15772. -
[91] Δ-dit: A training-free acceleration method tailored for diffusion transformers
P. Chen, M. Shen, P. Ye, J. Cao, C. Tu, C.-S. Bouganis, Y. Zhao, and T. Chen. arXiv preprint, arXiv:2406.01125, 2024. -
[92] Learning-to-cache: Accelerating diffusion transformer via layer caching
X. Ma, G. Fang, M. Bi Mi, and X. Wang. Advances in Neural Information Processing Systems, vol. 37, pp. 133282–133304, 2024. -
[93] Fastercache: Training-free video diffusion model acceleration with high quality
Z. Lv, C. Si, J. Song, Z. Yang, Y. Qiao, Z. Liu, and K.-Y. K. Wong. The Thirteenth International Conference on Learning Representations. -
[94] Distillation of discrete diffusion through dimensional correlations
S. Hayakawa, Y. Takida, M. Imaizumi, H. Wakaki, and Y. Mitsufuji. Forty-second International Conference on Machine Learning, 2025. -
[95] Progressive distillation for fast sampling of diffusion models
T. Salimans and J. Ho. International Conference on Learning Representations. -
[96] Lavida: A large diffusion language model for multimodal understanding
S. Li, K. Kallidromitis, H. Bansal, A. Gokul, Y. Kato, K. Kozuka, J. Kuen, Z. Lin, K.-W. Chang, and A. Grover. arXiv preprint, arXiv:2505.16839, 2025. -
[97] Fudoki: Discrete flow-based unified understanding and generation via kinetic-optimal velocities
J. Wang, Y. Lai, A. Li, S. Zhang, J. Sun, N. Kang, C. Wu, Z. Li, and P. Luo. arXiv preprint, arXiv:2505.20147, 2025. -
[98] Unified multimodal discrete diffusion
A. Swerdlow, M. Prabhudesai, S. Gandhi, D. Pathak, and K. Fragkiadaki. arXiv preprint, arXiv:2503.20853, 2025. -
[99] Roic-dm: Robust text inference and classification via diffusion model
S. Yuan, W. Yuan, H. Yin, and T. He. arXiv preprint, arXiv:2401.03514, 2024. -
[100] Diffusionner: Boundary diffusion for named entity recognition
Y. Shen, K. Song, X. Tan, D. Li, W. Lu, and Y. Zhuang. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 3875–3890. -
[101] Ipad: Iterative, parallel, and diffusion-based network for scene text recognition
X. Yang, Z. Qiao, and Y. Zhou. International Journal of Computer Vision, pp. 1–21, 2025. -
[102] Let’s rectify step by step: Improving aspect-based sentiment analysis with diffusion models
S. Liu, J. Zhou, Q. Zhu, Q. Chen, Q. Bai, J. Xiao, and L. He. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024, pp. 10324–10335. -
[103] Diffusum: Generation enhanced extractive summarization with diffusion
H. Zhang, X. Liu, and J. Zhang. Findings of the Association for Computational Linguistics: ACL 2023, 2023, pp. 13089–13100. -
[104] Termdiffusum: a term-guided diffusion model for extractive summarization of legal documents
X. Dong, W. Li, Y. Le, Z. Jiang, J. Zhong, and Z. Wang. Proceedings of the 31st international conference on computational linguistics, 2025, pp. 3222–3235. -
[105] Enhancing phrase representation by information bottleneck guided text diffusion process for keyphrase extraction
Y. Luo, Q. Zhou, and F. Zhou. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024, pp. 6036–6047. -
[106] Ibed: An implicit perspective for relational triple extraction based on diffusion model
J. Zhao, C. Xu, and B. Jiang. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 2080–2092. -
[107] Editext: Controllable coarse-to-fine text editing with diffusion language models
C. H. Lee, H. Kim, J. Yeom, and S. Yoon. arXiv preprint, arXiv:2502.19765, 2025. -
[108] Difusemp: A diffusion model-based framework with multi-grained control for empathetic response generation
G. Bi, L. Shen, Y. Cao, M. Chen, Y. Xie, Z. Lin, and X. He. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 2812–2831. -
[109] Diffudetox: A mixed diffusion model for text detoxification
G. Floto, M. M. A. Pour, P. Farinneya, Z. Tang, A. Pesaranghader, M. Bharadwaj, and S. Sanner. Findings of the Association for Computational Linguistics: ACL 2023, 2023, pp. 7566–7574. -
[110] Paraguide: Guided diffusion paraphrasers for plug-and-play textual style transfer
Z. Horvitz, A. Patel, C. Callison-Burch, Z. Yu, and K. McKeown. Proceedings of the AAAI conference on artificial intelligence, vol. 38, no. 16, 2024, pp. 18216–18224. -
[111] Planner: Generating diversified paragraph via latent language diffusion model
Y. Zhang, J. Gu, Z. Wu, S. Zhai, J. Susskind, and N. Jaitly. Advances in Neural Information Processing Systems, vol. 36, pp. 80178–80190, 2023. -
[112] Diffucom: A novel diffusion model for comment generation
J. Liu, P. Cheng, J. Dai, and J. Liu. Knowledge-Based Systems, vol. 281, p. 111069, 2023. -
[113] Diffusiondialog: A diffusion model for diverse dialog generation with latent space
J. Xiang, Z. Liu, H. Liu, Y. Bai, J. Cheng, and W. Chen. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024, pp. 4912–4921. -
[114] Improved paraphrase generation via controllable latent diffusion
W. Zou, Z. Zhuang, X. Geng, S. Huang, J. Liu, and J. Chen. arXiv preprint, arXiv:2404.08938, 2024. -
[115] Poetrydiffusion: Towards joint semantic and metrical manipulation in poetry generation
Z. Hu, C. Liu, Y. Feng, A. T. Luu, and B. Hooi. Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 18279–18288. -
[116] Xdlm: Cross-lingual diffusion language model for machine translation
L. Chen, A. Feng, B. Yang, and Z. Li. arXiv preprint, arXiv:2307.13560, 2023. -
[117] Diffusionret: Diffusion-enhanced generative retriever using constrained decoding
S. Qiao, X. Liu, and S.-H. Na. Findings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 9515–9529. -
[118] Debunk and infer: Multimodal fake news detection via diffusion-generated evidence and llm reasoning
K. Yan, M. Liu, Y. Liu, R. Fu, Z. Wen, J. Tao, and X. Liu. arXiv preprint, arXiv:2506.21557, 2025. -
[119] Plan for speed–dilated scheduling for masked diffusion language models
O. Luxembourg, H. Permuter, and E. Nachmani. arXiv preprint, arXiv:2506.19037, 2025. -
[120] Text-guided multi-property molecular optimization with a diffusion language model
Y. Xiong, K. Li, J. Chen, H. Zhang, D. Lin, Y. Che, and W. Hu. arXiv preprint, arXiv:2410.13597, 2024. -
[121] Text-guided molecule generation with diffusion language model
H. Gong, Q. Liu, S. Wu, and L. Wang. Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 1, 2024, pp. 109–117. -
[122] Memdlm: De novo membrane protein design with masked discrete diffusion protein language models
S. Goel, V. Thoutam, E. M. Marroquin, A. Gokaslan, A. Firouzbakht, S. Vincoff, V. Kuleshov, H. T. Kratochvil, and P. Chatterjee. NeurIPS 2024 Workshop on AI for New Drug Modalities. -
[123] Diffusion language models are versatile protein learners
X. Wang, Z. Zheng, D. Xue, S. Huang, Q. Gu et al. Forty-first International Conference on Machine Learning. -
[124] Cfp-gen: Combinatorial functional protein generation via diffusion language models
J. Yin, C. Zha, W. He, C. Xu, and X. Gao. Forty-second International Conference on Machine Learning. -
[125] Fine-tuning discrete diffusion models via reward optimization with applications to dna and protein design
C. Wang, M. Uehara, Y. He, A. Wang, A. Lal, T. Jaakkola, S. Levine, A. Regev, T. Biancalani et al. The Thirteenth International Conference on Learning Representations. -
[126] Forcegen: End-to-end de novo protein generation based on nonlinear mechanical unfolding responses using a language diffusion model
B. Ni, D. L. Kaplan, and M. J. Buehler. Science Advances, vol. 10, no. 6, p. eadl4000, 2024. -
[127] Diffusion sequence models for enhanced protein representation and generation
L. Hallee, N. Rafailidis, D. B. Bichara, and J. P. Gleghorn. arXiv preprint, arXiv:2506.08293, 2025. -
[128] Dplm-2: A multimodal diffusion protein language model
X. Wang, Z. Zheng, F. Ye, D. Xue, S. Huang, and Q. Gu. arXiv preprint, arXiv:2410.13782, 2024. -
[129] Deep unsupervised learning using nonequilibrium thermodynamics
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli. International conference on machine learning. pmlr, 2015, pp. 2256–2265. -
[130] Bert: Pre-training of deep bidirectional transformers for language understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186. -
[131] Roberta: A robustly optimized bert pretraining approach
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov. arXiv preprint, arXiv:1907.11692, 2019. -
[132] Albert: A lite bert for self-supervised learning of language representations
Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut. International Conference on Learning Representations. -
[133] Deberta: Decoding-enhanced bert with disentangled attention
P. He, X. Liu, J. Gao, and W. Chen. International Conference on Learning Representations. -
[134] Transformer-xl: Attentive language models beyond a fixed-length context
Z. Dai, Z. Yang, Y. Yang, J. Carbonell, Q. V. Le, and R. Salakhutdinov. arXiv preprint, arXiv:1901.02860, 2019. -
[135] Opt: Open pre-trained transformer language models
S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin et al. arXiv preprint, arXiv:2205.01068, 2022. -
[136] Better & faster large language models via multi-token prediction
F. Gloeckle, B. Y. Idrissi, B. Rozière, D. Lopez-Paz, and G. Synnaeve. Forty-first International Conference on Machine Learning. -
[137] Sequence to sequence learning with neural networks
I. Sutskever, O. Vinyals, and Q. V. Le. Advances in neural information processing systems, vol. 27, 2014. -
[138] Exploring the limits of transfer learning with a unified text-to-text transformer
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020. -
[139] Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension
M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020, pp. 7871–7880. -
[140] Seqdiffuseq: Text diffusion with encoder-decoder transformers
H. Yuan, Z. Yuan, C. Tan, F. Huang, and S. Huang. arXiv preprint, arXiv:2212.10325, 2022. -
[141] Xlnet: Generalized autoregressive pretraining for language understanding
Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. R. Salakhutdinov, and Q. V. Le. Advances in neural information processing systems, vol. 32, 2019. -
[142] Qwen2.5: A party of foundation models
Q. Team. September 2024. [Online]. Available: https://qwenlm.github.io/blog/qwen2.5/ -
[143] Segment-level diffusion: A framework for controllable long-form generation with diffusion language models
X. Zhu, G. Karadzhov, C. Whitehouse, and A. Vlachos. arXiv preprint, arXiv:2412.11333, 2024. -
[144] Latent diffusion for document generation with sequential decoding
Y. Zihuiwen, Y. Elle Michelle, and B. Phil. NeurIPS 2023 Workshop on Diffusion Models, 2023. [Online]. Available: https://neurips.cc/virtual/2023/74876 -
[145] Meissonic: Revitalizing masked generative transformers for efficient high-resolution text-to-image synthesis
J. Bai, T. Ye, W. Chow, E. Song, Q.-G. Chen, X. Li, Z. Dong, L. Zhu, and S. Yan. The Thirteenth International Conference on Learning Representations, 2024. -
[146] Addressing the training-inference discrepancy in discrete diffusion for text generation
M. Asada and M. Miwa. Proceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 7156–7164. -
[147] Attention is all you need
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Advances in neural information processing systems, vol. 30, 2017. -
[148] Adversarial diffusion distillation
A. Sauer, D. Lorenz, A. Blattmann, and R. Rombach. European Conference on Computer Vision. Springer, 2024, pp. 87–103. -
[149] Fast high-resolution image synthesis with latent adversarial diffusion distillation
A. Sauer, F. Boesel, T. Dockhorn, A. Blattmann, P. Esser, and R. Rombach. SIGGRAPH Asia 2024 Conference Papers, 2024, pp. 1–11. -
[150] Visual instruction tuning
H. Liu, C. Li, Q. Wu, and Y. J. Lee. Advances in neural information processing systems, vol. 36, pp. 34892–34916, 2023. -
[151] Llava-interleave: Tackling multi-image, video, and 3d in large multimodal models
F. Li, R. Zhang, H. Zhang, Y. Zhang, B. Li, W. Li, Z. Ma, and C. Li. The Thirteenth International Conference on Learning Representations. -
[152] Mammoth-vl: Eliciting multimodal reasoning with instruction tuning at scale
J. Guo, T. Zheng, Y. Bai, B. Li, Y. Wang, K. Zhu, Y. Li, G. Neubig, W. Chen, and X. Yue. arXiv preprint, arXiv:2410.05237, 2024. -
[153] The llama 3 herd of models
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan et al. arXiv preprint, arXiv:2407.21783, 2024. -
[154] Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge et al. arXiv preprint, arXiv:2409.12191, 2024. -
[155] Show-o: One single transformer to unify multimodal understanding and generation
J. Xie, W. Mao, Z. Bai, D. J. Zhang, W. Wang, K. Q. Lin, Y. Gu, Z. Chen, Z. Yang, and M. Z. Shou. The Thirteenth International Conference on Learning Representations. -
[156] Orthus: Autoregressive interleaved image-text generation with modality-specific heads
S. Kou, J. Jin, Z. Liu, C. Liu, Y. Ma, J. Jia, Q. Chen, P. Jiang, and Z. Deng. arXiv preprint, arXiv:2412.00127, 2024. -
[157] Janus: Decoupling visual encoding for unified multimodal understanding and generation
C. Wu, X. Chen, Z. Wu, Y. Ma, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, C. Ruan et al. Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12966–12977. -
[158] Piqua: Reasoning about physical commonsense in natural language
Y. Bisk, R. Zellers, J. Gao, Y. Choi et al. Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 05, 2020, pp. 7432–7439. -
[159] Hel-laswag: Can a machine really finish your sentence?
R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 4791–4800. -
[160] Evaluating large language models trained on code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman et al. arXiv preprint, arXiv:2107.03374, 2021. -
[161] Geneval: An object-focused framework for evaluating text-to-image alignment
D. Ghosh, H. Hajishirzi, and L. Schmidt. Advances in Neural Information Processing Systems, vol. 36, pp. 52132–52152, 2023. -
[162] Mme: A comprehensive evaluation benchmark for multimodal large language models
C. Fu, P. Chen, Y. Shen, Y. Qin, M. Zhang, X. Lin, J. Yang, X. Zheng, K. Li, X. Sun et al. arXiv preprint, arXiv:2306.13394, 2023. -
[163] Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
X. Yue, Y. Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y. Sun et al. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9556–9567. -
[164] Gqa: A new dataset for real-world visual reasoning and compositional question answering
D. A. Hudson and C. D. Manning. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6700–6709. -
[165] Training verifiers to solve math word problems
K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano et al. arXiv preprint, arXiv:2110.14168, 2021. -
[166] Qwen2 technical report
Q. Team. arXiv preprint, arXiv:2407.10671, 2024. -
[167] Gpqa: A graduate-level google-proof q&a benchmark
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R. Bowman. First Conference on Language Modeling, 2024. -
[168] Measuring mathematical problem solving with the math dataset
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). -
[169] Fine-grained text style transfer with diffusion-based language models
Y. Lyu, T. Luo, J. Shi, T. C. Hollon, and H. Lee. arXiv preprint, arXiv:2305.19512, 2023. -
[170] Benchmarking diffusion models for machine translation
Y. Demirag, D. Liu, and J. Niehues. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop, 2024, pp. 313–324. -
[171] Transformers: State-of-the-art natural language processing
T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz et al. Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, 2020, pp. 38–45. -
[172] Efficient memory management for large language model serving with pagedattention
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. -
[173] Qwen3 technical report
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv et al. arXiv preprint, arXiv:2505.09388, 2025. -
[174] Kimi K2: Open agentic intelligence
K. Team, Y. Bai, Y. Bao, G. Chen, J. Chen, N. Chen, R. Chen, Y. Chen, Y. Chen, Y. Chen et al. arXiv preprint, arXiv:2507.20534, 2025.