🥰 Thank you, Stanford! 🥰
本文最后更新于 2026年1月16日 上午
9.24 - 9.26 凌晨1点
以下内容均来自于 CS336 课堂教学与课后讲稿,仅供学习参考。如有错误,请在下方评论区指出,谢谢!
引子
Algorithms 的效率很重要!
回顾 Language Models 的发展历程
-
Pre-neural(Before 2010s)
- 基于熵的语言模型 [Shannon 1950]
- n-gram language models(用于机器翻译、语音识别)的大量研究 [Brants+ 2007]
-
Neural ingredients(2010s)
- 首个神经语言模型 [Bengio+ 2003]
- Seq2Seq 建模(用于机器翻译) [Sutskever+ 2014]
- Adam 优化器 [Kingma+ 2014]
- Attention mechanism 注意力机制(用于机器翻译) [Bahdanau+ 2014]
- Transformer 架构(用于机器翻译) [Vaswani+ 2017]
- 混合专家模型(Mixture of experts, MoE) [Shazeer+ 2017]
- 模型并行(parallelism) [Huang+ 2018] [Rajbhandari+ 2019] [Shoeybi+ 2019]
-
Early foundation models(late 2010s)
- ELMo:使用长短期记忆网络(LSTMs)进行预训练,微调对任务有帮助 [Peters+ 2018]
- BERT:使用 Transformer 进行预训练,微调对任务有帮助 [Devlin+ 2018]
- Google’s T5(11B):将所有任务转化为 text-to-text 的形式 [Raffel+ 2019]
-
Embracing scaling, more closed
- OpenAI’s GPT-2(1.5B):文本流畅,出现零样本能力的初步迹象,分阶段发布 [Radford+ 2019]
- Scaling laws:为规模扩张提供希望与可预测性 [Kaplan+ 2020]
- OpenAI’s GPT-3(175B):上下文学习,闭源 [Brown+ 2020]
- Google’s PaLM(540B):规模庞大,训练不充分 [Chowdhery+ 2022]
- DeepMind’s Chinchilla(70B):计算最优的缩放定律 [Hoffmann+ 2022]
-
Open models
- EleutherAI’s 开源数据集(The Pile)与模型(GPT-J) [Gao+ 2020] [Wang+ 2021]
- Meta’s OPT(175B):复刻 GPT-3,存在大量硬件问题 [Zhang+ 2022]
- Hugging Face / BigScience’s BLOOM:聚焦数据来源 [Workshop+ 2022]
- Meta’s Llama [Touvron+ 2023] [Touvron+ 2023] [Grattafiori+ 2024]
- Alibaba’s Qwen models [Qwen+ 2024]
- DeepSeek’s models [DeepSeek-AI+ 2024] [DeepSeek-AI+ 2024] [DeepSeek-AI+ 2024]
- AI2’s OLMo 2 [Groeneveld+ 2024] [OLMo+ 2024]
-
Levels of openness
- Closed models (e.g. GPT-4o): 仅支持 API 访问 [OpenAI+ 2023]
- 开放权重模型(e.g. DeepSeek):权重可获取,论文包含架构细节、部分细节,但无数据细节 [DeepSeek-AI+ 2024]
- 开源模型(e.g. OLMo):权重和数据均可获取,论文包含大部分细节(但不包含原理阐释、失败的实验) [Groeneveld+ 2024]
-
Today’s frontier models
- OpenAI’s o3 https://openai.com/index/openai-o3-mini/
- Anthropic’s Claude Sonnet 3.7 https://www.anthropic.com/news/claude-3-7-sonnet
- xAI’s Grok 3 https://x.ai/news/grok-3
- Google’s Gemini 2.5 https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025/
- Meta’s Llama 3.3 https://ai.meta.com/blog/meta-llama-3/
- DeepSeek’s r1 [DeepSeek-AI+ 2025]
- Alibaba’s Qwen 2.5 Max https://qwenlm.github.io/blog/qwen2.5-max/
- Tencent’s Hunyuan-T1 https://tencent.github.io/llm.hunyuan.T1/README_EN.html
课程设计

课程设计
-
Basics 涉及大模型训练的基础要素:
- Tokenization(分词,将文本切分为模型可处理的单元)
- Architecture(模型架构,如Transformer等结构)
- Loss function(损失函数,衡量模型预测与真实值的差距)
- Optimizer(优化器,用于更新模型参数以降低损失)
- Learning rate(学习率,控制参数更新的步长)
-
Systems 聚焦大模型的系统工程与效率优化:
- Kernels(内核,底层计算核心)
- Parallelism(并行计算,加速训练/推理的手段)
- Quantization(量化,压缩模型以提升效率)
- Activation checkpointing(激活检查点,节省内存的技术)
- CPU offloading(CPU卸载,将部分计算转移到CPU以优化资源)
- Inference(推理,模型完成训练后做预测的过程)
-
Scaling laws 研究“模型规模/数据量与性能关系”的规律:
- Scaling sequence(缩放序列,模型/数据缩放的顺序逻辑)
- Model complexity(模型复杂度,模型的表达能力)
- Loss metric(损失度量,衡量性能的损失指标)
- Parametric form(参数形式,缩放规律的数学表达形式)
-
Data 围绕训练数据的处理与优化:
- Evaluation(评估,数据质量等的评估)
- Curation(整理,数据的筛选与组织)
- Transformation(转换,数据格式/分布的转换)
- Filtering(过滤,去除低质量数据)
- Deduplication(去重,消除重复数据)
- Mixing(混合,多来源数据的融合)
-
Alignment 让模型行为符合人类预期的技术:
- Supervised fine-tuning(有监督微调,用标注数据优化模型)
- Reinforcement learning(强化学习,通过“奖励/惩罚”引导模型)
- Preference data(偏好数据,反映人类偏好的数据集)
- Synthetic data(合成数据,人工生成的训练数据)
- Verifiers(验证器,检验模型对齐效果的模块)
Basics
Goal:跑通 pipeline。
Components: tokenization, model architecture, training
Tokenization
分词器 (Tokenizers) 的作用:在字符串和整数序列 (tokens) 之间进行转换。
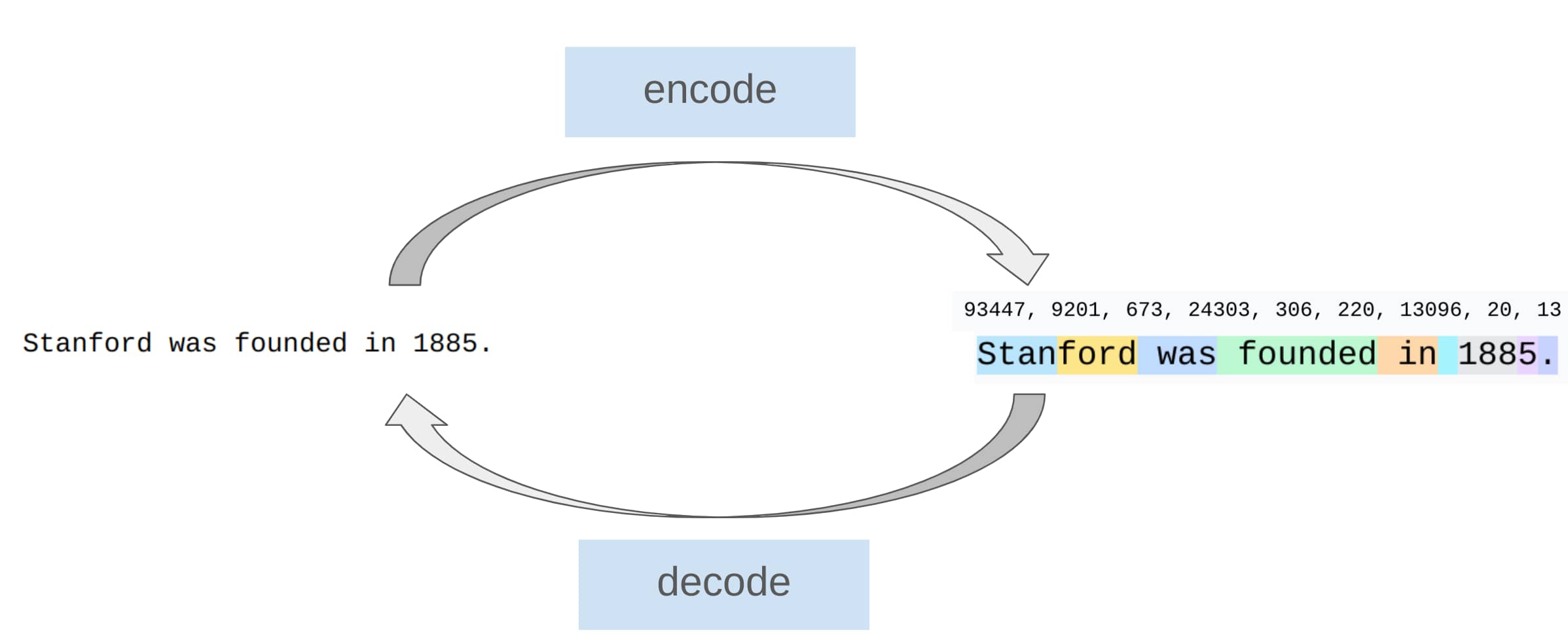
Tokenizer 示意图
直观上,就是将长字符串拆分成常用词片段(segments)。这样做的想法就是,将整数序列对应于输入到实际模型中的内容,而这个模型必须是固定维度的。
CS336 使用的是 Byte-Pair Encoding (BPE) tokenizer [Sennrich+ 2015],它是一种基于统计的分词方法。
Tokenizer-free approaches:[Xue+ 2021] [Yu+ 2023] [Pagnoni+ 2024] [Deiseroth+ 2024]
这些方法会直接处理原始字节,而不进行分词来处理数据,并开发一种特定架构,直接接受原始字节。这种方式很有前景,但尚未扩展应用到前沿领域。
Architecture
Starting point: original Transformer [Vaswani+ 2017]
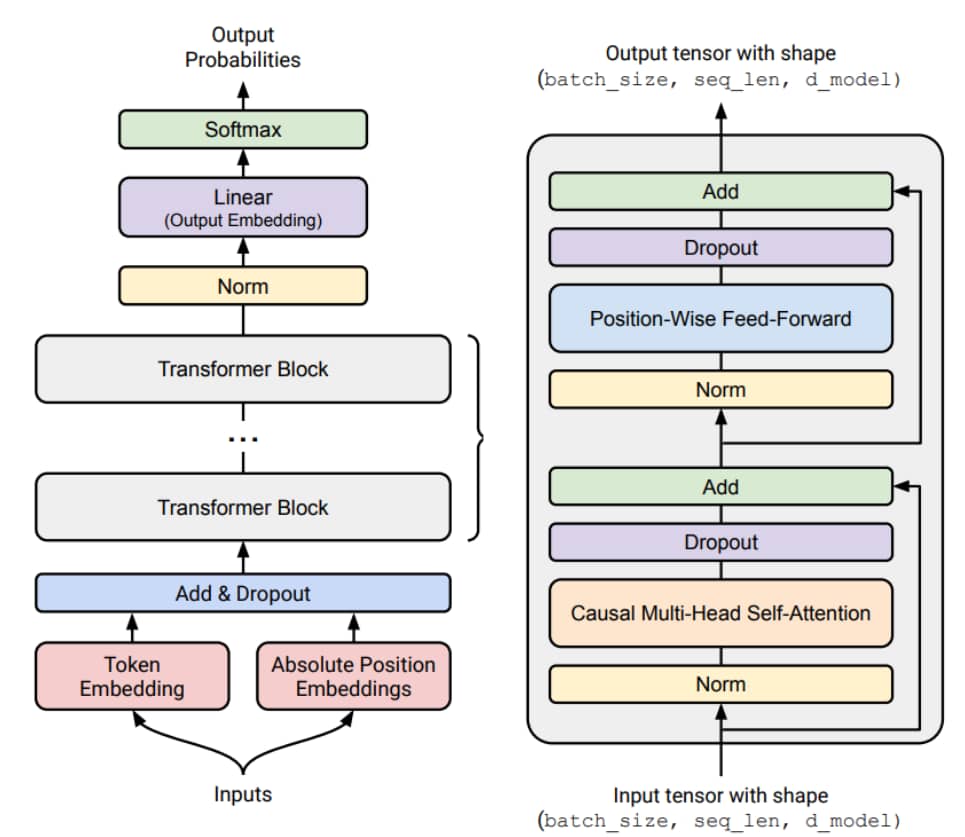
Transformer 架构示意图
Variants:
- 激活函数(Activation functions): ReLU, SwiGLU [Shazeer 2020]
- 选取 ReLU、SwiGLU 这类非线性激活函数。
- 位置编码(Positional encodings): sinusoidal, RoPE [Su+ 2021]
- 一些新的位置编码,旋转位置编码(Rotary Positional Embeddings, RoPE)等。
- 归一化(Normalization): LayerNorm, RMSNorm [Ba+ 2016][Zhang+ 2019]
- 使用 RMS 归一化等。
- 归一化的位置(Placement of normalization): pre-norm versus post-norm [Xiong+ 2020]
- 规划放在哪里?
- MLP: dense, mixture of experts [Shazeer+ 2017]
- 使用混合专家模型(Mixture of experts, MoE)来替换MLP
- 注意力机制(Attention): full, sliding window, linear [Jiang+ 2023][Katharopoulos+ 2020]
- 全注意力(full)、滑动窗口注意力(sliding window)、线性注意力(linear)等来防止二次增长(quadratic blow-up)
- 低维注意力(Lower-dimensional attention): group-query attention (GQA), multi-head latent attention (MLA) [Ainslie+ 2023][DeepSeek-AI+ 2024]
- 低维版本的注意力机制,如分组查询注意力(group-query attention, GQA)、多头潜在注意力(multi-head latent attention, MLA),更高效
- 状态空间模型(State-space models): Hyena [Poli+ 2023]
- 不使用注意力机制。
Training
- Optimizer (e.g., AdamW, Muon, SOAP) [Kingma+ 2014][Loshchilov+ 2017][Keller 2024][Vyas+ 2024]
- Learning rate schedule (e.g., cosine, WSD) [Loshchilov+ 2016][Hu+ 2024]
- Batch size (e…g, critical batch size) [McCandlish+ 2018]
- Regularization (e.g., dropout, weight decay)
- Hyperparameters (number of heads, hidden dimension): grid search
Assignment 1
- 实现 BPE 分词器
- 实现 Transformer模型,交叉熵损失函数、AdamW优化器,以及训练循环;
- 在 TinyStories 和 OpenWebText 这两个文本数据集上训练模型;
- Leaderboard:用H100显卡训练90分钟,尽可能降低模型在OpenWebText数据集上的“困惑度”(perplexity)。[往年榜单]
Systems
Goal:最大限度地利用硬件。
Components:kernels, parallelism, inference.
Kernels
GPU长什么样?

GPU 结构示意图
内存在芯片外面,芯片中有 L1 cache 和 L2 cache。计算是在芯片中执行的,而数据可能在别的地方。如何才能有效组织计算,以实现更高的效率?
下图就是一个简单的类比:
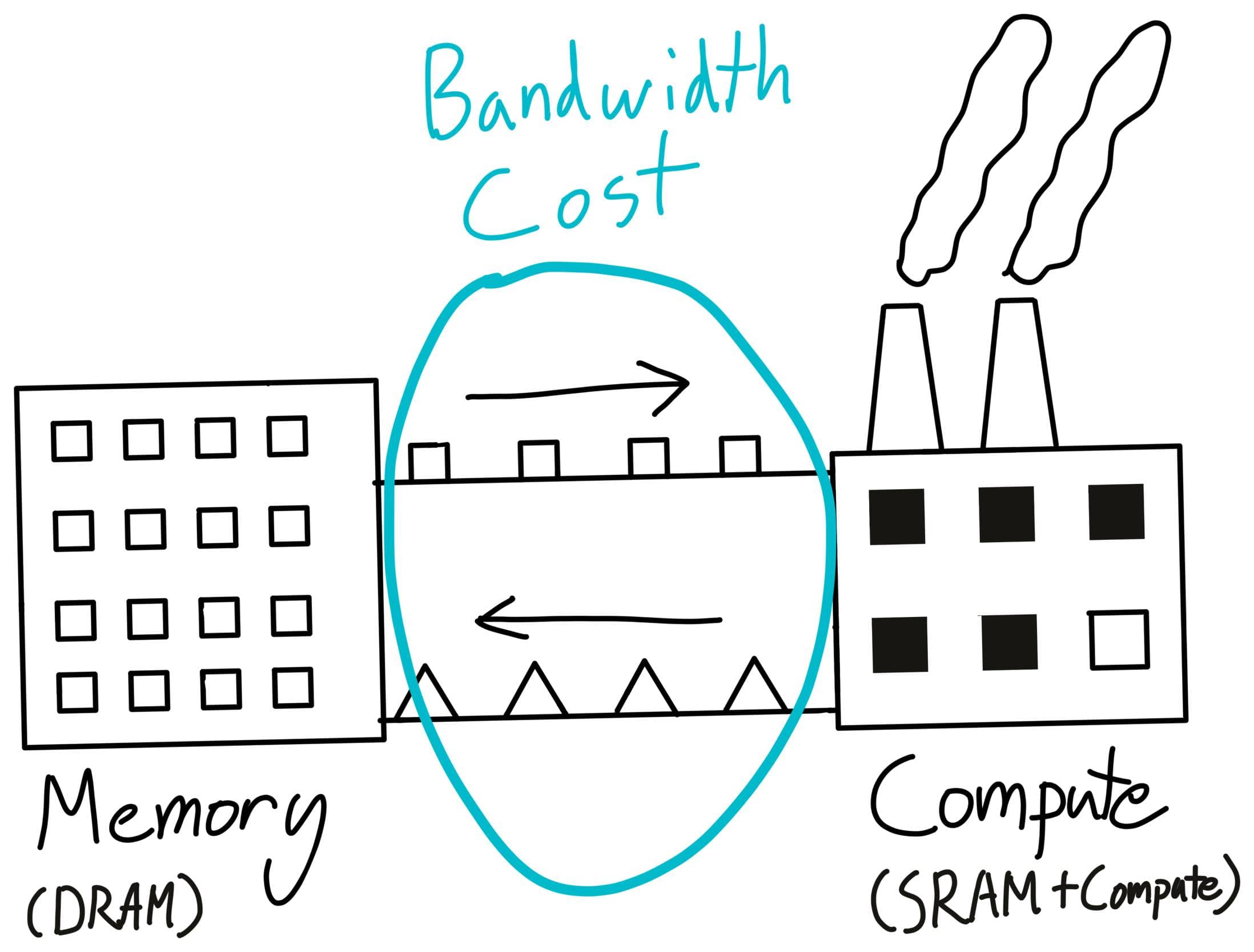
老师的手绘示意图
内存就如同仓库一样,可以存储数据模型的参数;而计算单元就如同工厂,可以执行计算任务。在此过程中,主要的瓶颈就是数据移动的成本。
Trick:合理安排计算,最小化数据移动成本,最大化GPUs的利用率。
通过 CUDA/Triton/CUTLASS/ThunderKittens 等工具,编写更高效的 kernels。
Parallelism
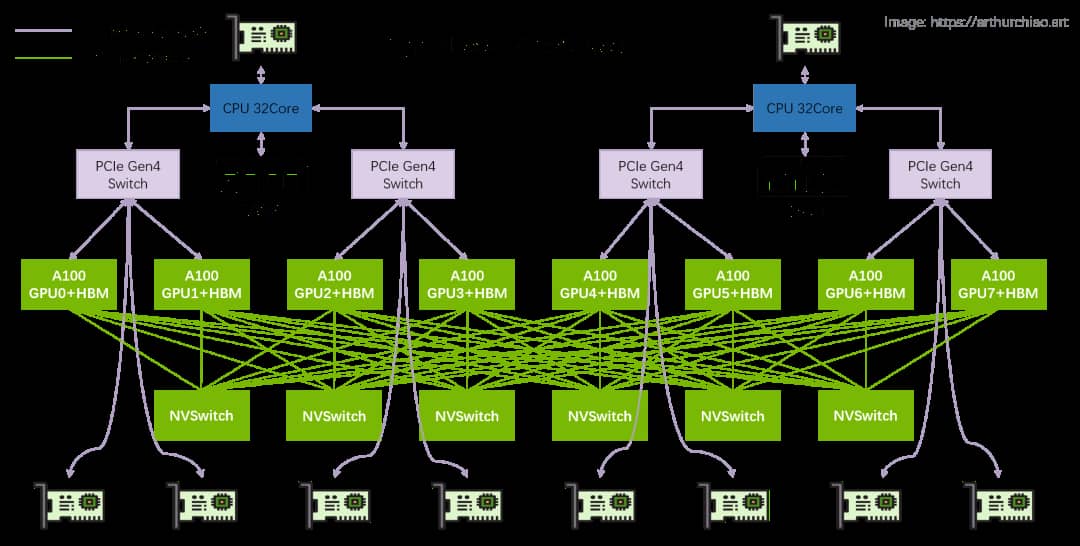
并行计算示意图
GPU之间传输数据的速度更慢,但“尽量减少数据移动”的原则仍然适用。
- 采用集合操作 (collection operations)(e.g., gather, reduce, all-reduce);
- 把参数 (parameters)、激活值 (activations)、梯度 (gradients)、优化器状态 (optimizer states) 等在多个GPU之间进行分片处理;
- 拆分 (split) 作并行计算:data, tensor, pipeline, sequence
Inference
Goal:给定 prompt,生成 tokens。
推理在强化学习 (reinforcement learning)、测试时 (test-time) 的计算以及评估 (evaluation) 中都很重要。
推理分为两个阶段:预填充阶段 (prefill) 和解码阶段 (decode)
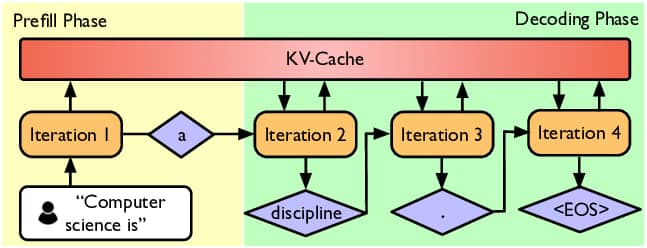
推理过程示意图
预填充阶段:接收 prompt,运行模型得到激活值;天生就是并行的,能一次性处理所有 tokens,受计算能力限制;
解码阶段:逐个进行自回归生成 token;因为一次生成一个 token,很难充分利用所有的 GPU,会受到内存限制(因为要不断移动数据)。
加速解码的方法有这些:
- 用更轻量的 (cheaper) 模型(通过模型剪枝 (pruning)、量化 (quantization)、蒸馏 (distillation) 来实现);
- 推测解码 (Speculative Decoding):先用更轻量的“草稿”模型 (draft model) 生成多个 tokens,再用完整模型并行给这些 tokens 打分(精确解码);
- 系统优化 (Systems Optimizations) 手段:KV 缓存 (KV caching)、批处理 (batching)
Assignment 2
要完成的任务如下:
- 在 Triton 里实现一个 Fused RMSNorm Kernel;
- 实现分布式数据并行训练;
- 实现优化器状态分片;
- 对这些实现进行基准测试 (Benchmark) 和性能分析。
Scaling Laws
Goal:进行小规模的实验,并以此预测大规模下的超参数和损失情况。
Question:给定计算量 (FLOPs) 预算 时,到底是使用更大的模型(),还是在更多的 tokens()上训练?
计算最优的缩放法则可参考 [Kaplan+ 2020] [Hoffmann+ 2022]
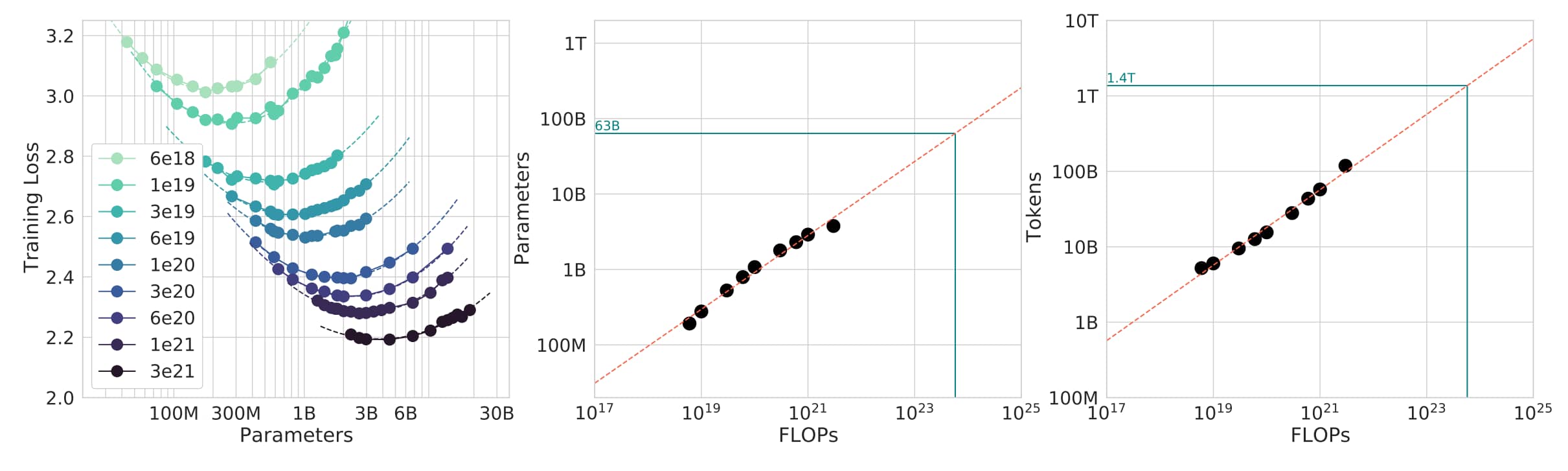
Scaling Laws 论文结果
简单来说就是:(比如 1.4B 参数的模型,应该用 28B 个 tokens 来训练)。不过,这个结论没把推理时的成本考虑进去。
注:这是经验公式。
Assignment 3
要完成的任务如下:
- 基于之前的运行结果,定义一个训练API(输入超参数,输出损失)。
- 提交“训练任务”(在计算量预算限制下),并收集数据点。
- 用这些数据点拟合出一个 scaling law。
- 提交放大后的超参数对应的预测。
- Leaderboard:在计算量预算下,让损失最小化。
Data
要明确我们希望模型具备哪些能力:是多语言能力?还是代码相关能力?或者数学方面的能力?
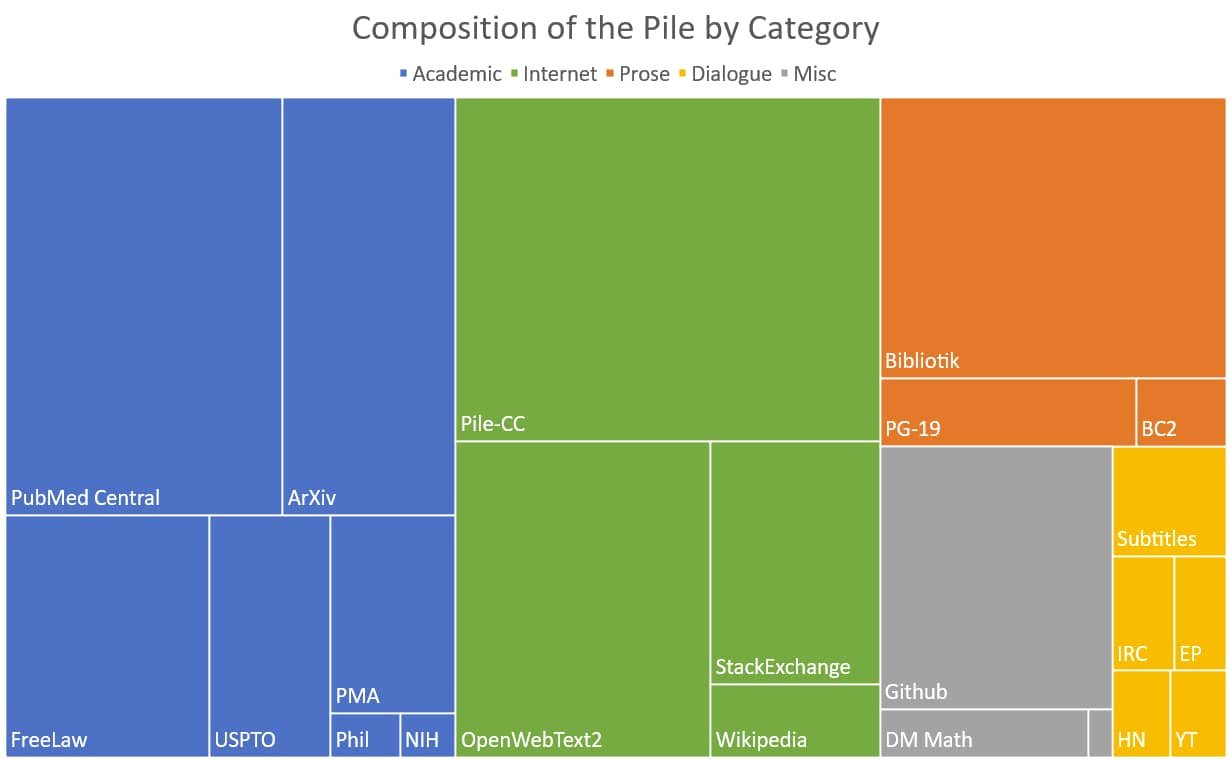
不同数据来源的比例
Evaluation
- 困惑度 (perplexity):是语言模型的经典评估方式。
- 标准化测试:比如 MMLU、HellaSwag、GSM8K 这类测试。
- 指令遵循(评估):例如 AlpacaEval、IFEval、WildBench 这些相关评估。
- 测试时计算的扩展:像思维链 (chain-of-thought, CoT)、集成 (ensembling) 等方法。
- 用语言模型当评判:评估生成类任务。
- 对整个系统评估:检索增强生成 (Retrieval-Augmented Generation, RAG)、智能体(agents)。
Data curation
- 数据不是平白无故就有的,需要主动去获取。比如可以关注网络数据。
- 数据来源:从互联网抓取的网页、书籍、arXiv上的论文、GitHub上的代码等。
- 能不能依据“合理使用”原则,用有版权的数据来训练模型?[Henderson+ 2023]。
- 有时候可能得给数据授权 [Google与Reddit的合作]。
- 数据格式常见的有 HTML、PDF、计算机文件/代码的目录 (directories)(不是简单的纯文本格式)。
Data processing
- 转换 (Transformation):将HTML、PDF格式转换为文本(保留内容、部分结构,还可能需要改写);
- 过滤 (Filtering):保留高质量数据,去除有害内容(借助分类器实现);
- 去重 (Deduplication):节省计算资源、避免模型记忆重复信息;可使用 Bloom filters 或 MinHash 算法。
Assignment 4
要完成的任务如下:
- 将 Common Crawl 的 HTML 转换为文本。
- 训练分类器,筛选出优质且无害的内容。
- 用 MinHash 进行去重操作。
- Leaderboard:在给定的标记预算下,最小化困惑度。
Alignment
到目前为止,基础模型 (base model) 只是有原始潜力,很擅长预测下一个标记。而 对齐 (alignment) 能让模型真正变得有用。
对齐的目标包括:
- 让语言模型能遵循指令;
- 调整风格(像格式、长度、语气这类方面);
- 融入安全性(比如对有害问题拒绝回答)。
对齐有两个阶段:
- 有监督微调 (supervised fine-tuning, SFT);
- 从反馈中学习 (learning from feedback, LFF)
SFT
- 数据类型 (Instruction data):用的是(prompt, response)的成对指令数据(这类数据往往需要人工标注)
- 直觉上:基础模型本身已有相关能力,只需少量例子就能“唤醒”这些能力 [Zhou+ 2023]
- 通过有监督学习微调模型,让 最大化。
LFF
想法:目前已有一个初步能遵循指令的模型,要在不花费高昂标注成本的情况下优化它。
Preference data
数据:从一个给定的 prompt,生成多个回答 [A, B]
用户提供偏好:A < B 或 A > B。
Verifiers
- 形式化验证器 (Formal Verifiers):适用于代码、数学等严谨领域,能严格验证结果对错。
- 学习型验证器 (Learned Verifiers):通过 LM-as-a-judge 的方式对抗学习
Algorithms
- 近端策略优化 (Proximal Policy Optimization, PPO):来自强化学习领域 [Schulman+ 2017] [Ouyang+ 2022]
- 直接策略优化 (Direct Policy Optimization, DPO):用于偏好数据,特点是更简单 [Rafailov+ 2023]
- 组相对偏好优化 (Group Relative Preference Optimization, GRPO):移除价值函数 [Shao+ 2024]
Assignment 5
要完成的任务如下:
- 实现有监督微调;
- 实现直接偏好优化 (Direct Preference Optimization, DPO);
- 实现组相对偏好优化 (Group Relative Preference Optimization, GRPO)。
第一部分-Tokenization
This unit was inspired by Andrej Karpathy’s video on tokenization; check it out![video]
1.1 Intro to Tokenization
原始文本一般用 Unicode字符串 表示
1 | |
语言模型对 token序列(token通常用整数索引表示)赋予概率分布。
1 | |
因此我们不仅需要 “encodes strings into tokens”,还需要 “decodes tokens back into strings” 的程序。
- Tokenizer 是一个类,专门实现 encode 和 decode 这两种方法;
- vocabulary size 指的是 “可能的 token 的总数量”。
1.2 Tokenization Examples
To get a feel for how tokenizers work, play with this interactive site
Observation
- 一个单词和它前面的空格是同一个token的一部分(例如,
" world")。 - 开头的单词和中间的单词表示方式不同(例如,
"hello hello")。 - 数字会被每几位拆分成一个token。
下面是OpenAI的GPT - 2分词器(tiktoken)的实际操作演示。
1 | |
验证 encode() 和 decode() 的往返一致性:
1 | |
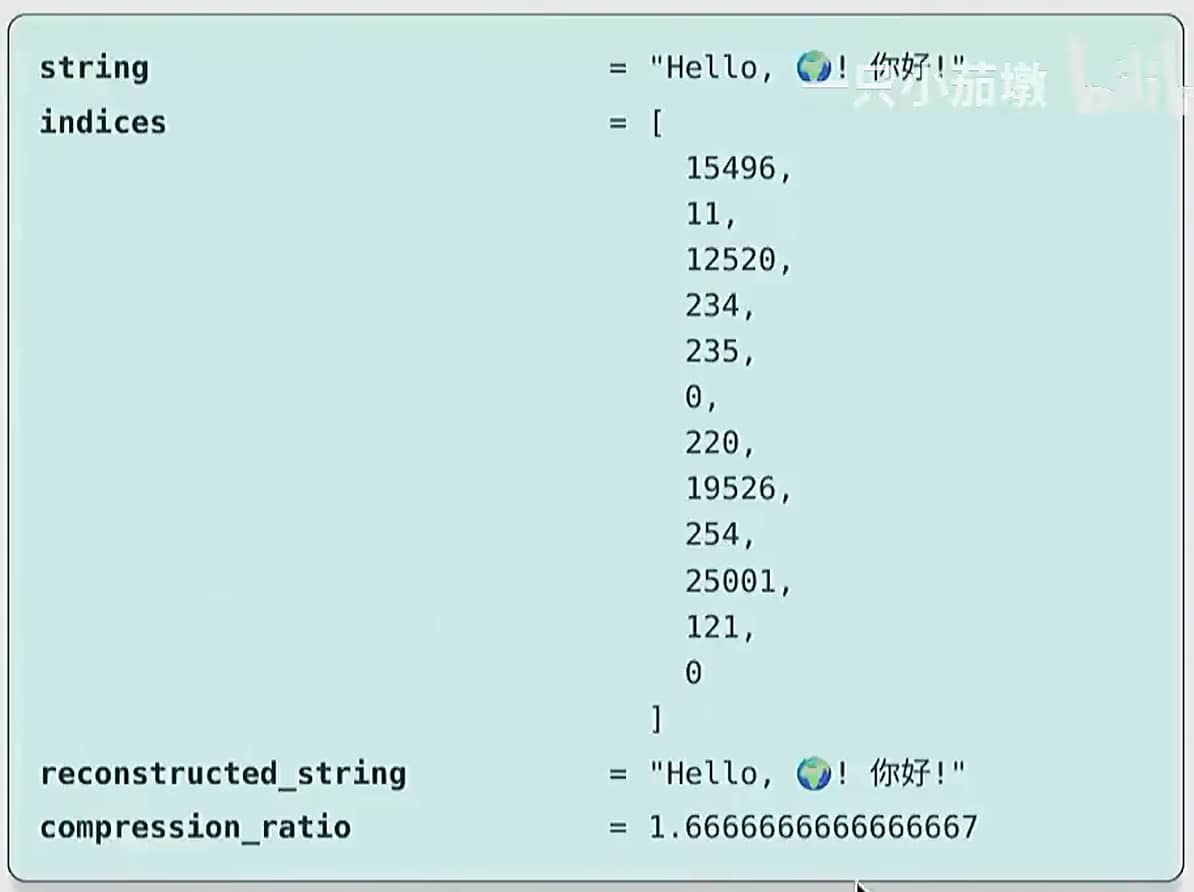
GPT-2 分词器样例
注释:每个词元代表1.6字节的数据
1.3 Character Tokenizer
Character based tokenization
基于字符的分词
Unicode 字符串是 Unicode 字符的序列。每个字符都可以通过函数 ord 转换为码点 (code point)(整数)
1 | |
它可以通过 chr 函数转换回来。
1 | |
现在让我们构建一个分词器并确保它能往返转换:
1 | |
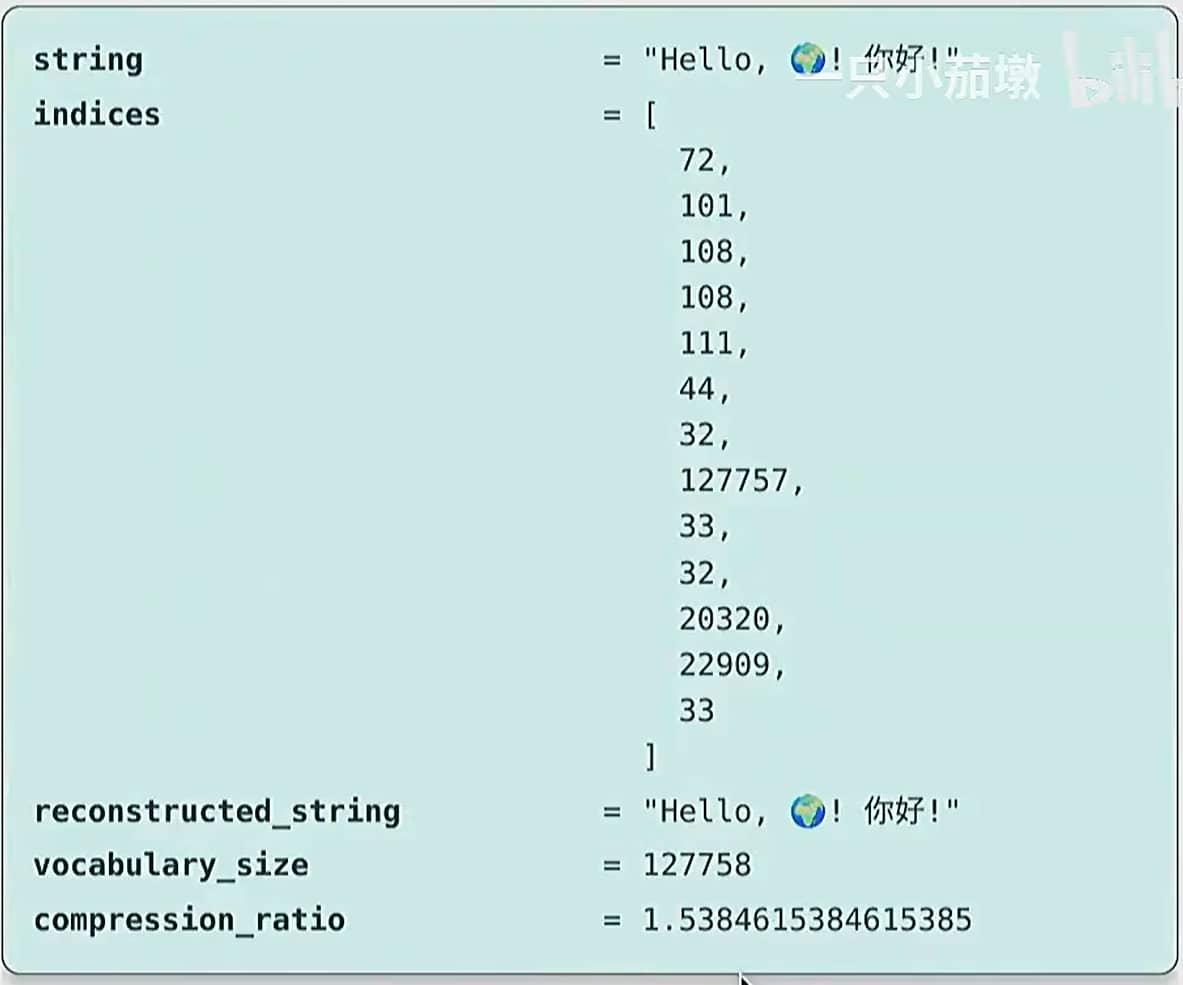
Character-based tokenizer 可视化结果
大约有 15 万个 Unicode 字符。[Wikipedia]
上述做法会产生两个问题:
- 问题1:这是一个非常大的词汇表。
- 问题2:许多字符非常罕见(例如,🌍),这是对词汇表的低效使用。
1.4 Byte Tokenizer
Byte based tokenization
基于字节的分词
Unicode 字符串可以表示为字节序列,字节可以用 0 到 255 之间的整数表示。最常见的 Unicode 编码是 UTF-8
一些Unicode字符由一个字节表示:
1 | |
其他字符需要多个字节:
1 | |
现在让我们构建一个分词器并确保它能往返转换:
1 | |
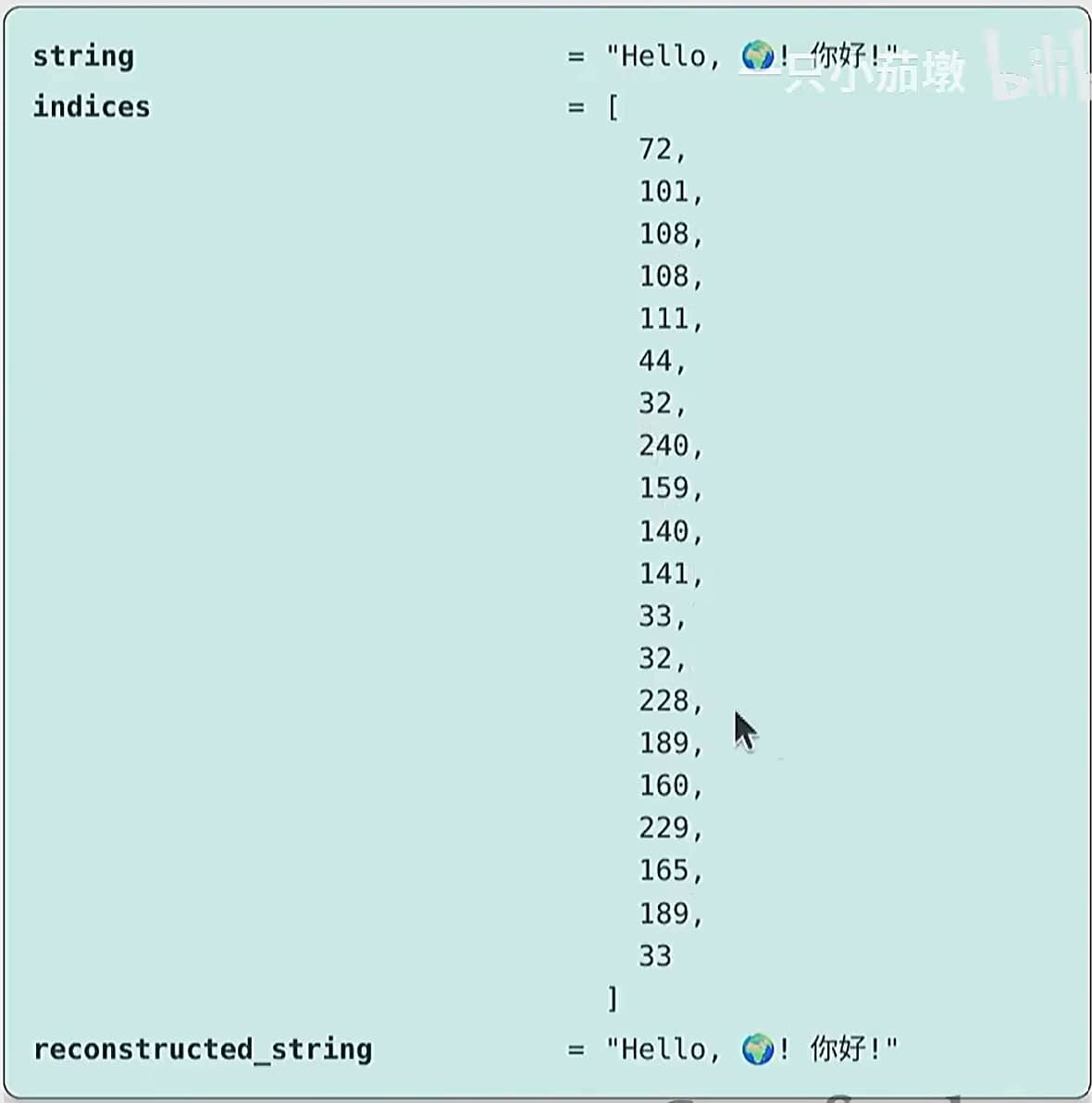
Byte-based tokenizer 可视化结果
词汇表很不错且很小:一个字节可以表示 256 个值。
压缩率很糟糕,这意味着序列会太长。考虑到 Transformer 的上下文长度是有限的(因为注意力是二次方复杂度的),所以这样不太好。
1.5 Word Tokenizer
Word based tokenization
基于词的分词
另一种方法(更接近 NLP 领域的传统做法)是将字符串拆分为单词。
1 | |
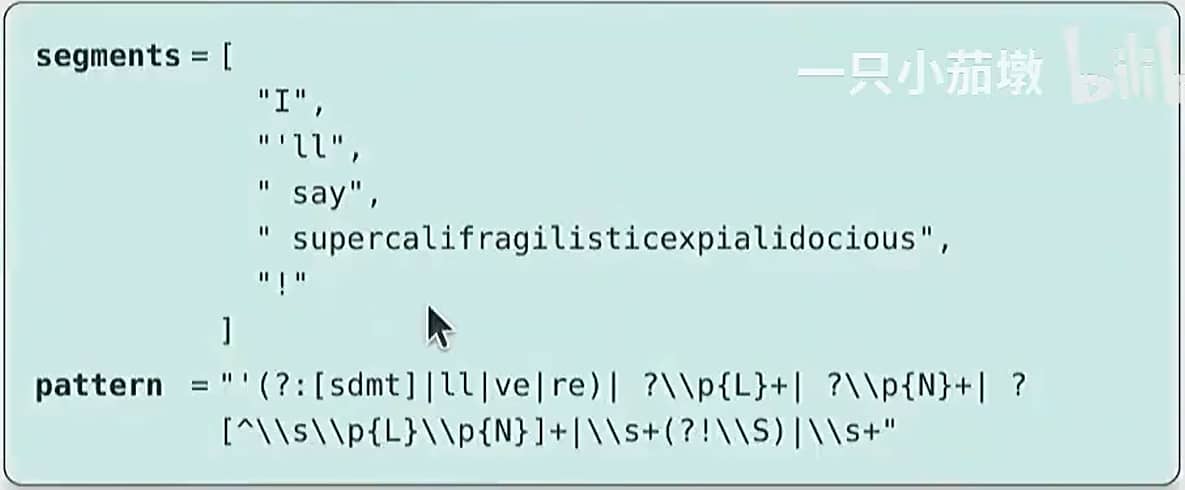
Word-based tokenizer 可视化结果
这个正则表达式会将所有字母数字字符组合在一起(形成单词)。
这里有一个更精巧的版本:
1 | |
要将其转化为一个分词器 (Tokenizer),我们需要把这些片段 (segments) 映射为整数。然后,我们可以建立每个片段到整数的映射。
但存在一些问题:
- 单词的数量极其庞大(类似 Unicode 字符的情况)。
- 很多单词十分罕见,模型无法从它们身上学到太多东西。
- 这显然无法提供固定的词汇表大小。
在训练阶段没见过的新单词会被赋予一个特殊的 UNK 标记,这很不优雅,还会搞乱困惑度(perplexity) 的计算。
1.6 BPE Tokenizer
Byte Pair Encoding (BPE)
字节对编码 [维基百科]
BPE算法由Philip Gage于1994年提出,用于数据压缩。[article]
它被应用于 NLP 领域的神经机器翻译。[Sennrich+ 2015](在此之前,论文一直使用 word-based tokenization)
BPE 随后被 GPT-2 使用。[Radford+ 2019]
Basic idea:在原始文本上训练分词器,以自动确定词汇表。
Intuition:常见的字符序列由单个 token 表示,罕见的序列由多个 token 表示。
为了效率,GPT-2 论文使用 word-based tokenization 将文本拆分为初始片段,然后在每个片段上运行原始 BPE 算法。
大致流程:从每个字节作为一个 token 开始,逐步合并出现频率最高的相邻 token 对。
Training the tokenizer
1 | |
代码如下:
1 | |
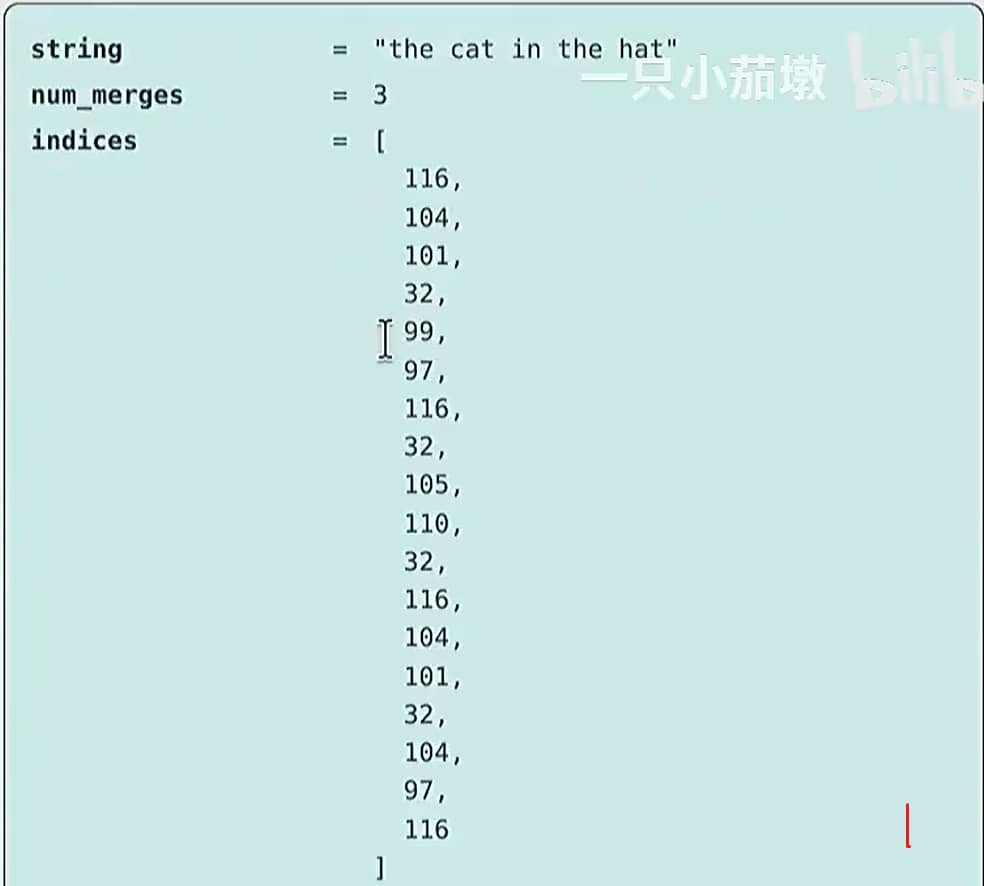
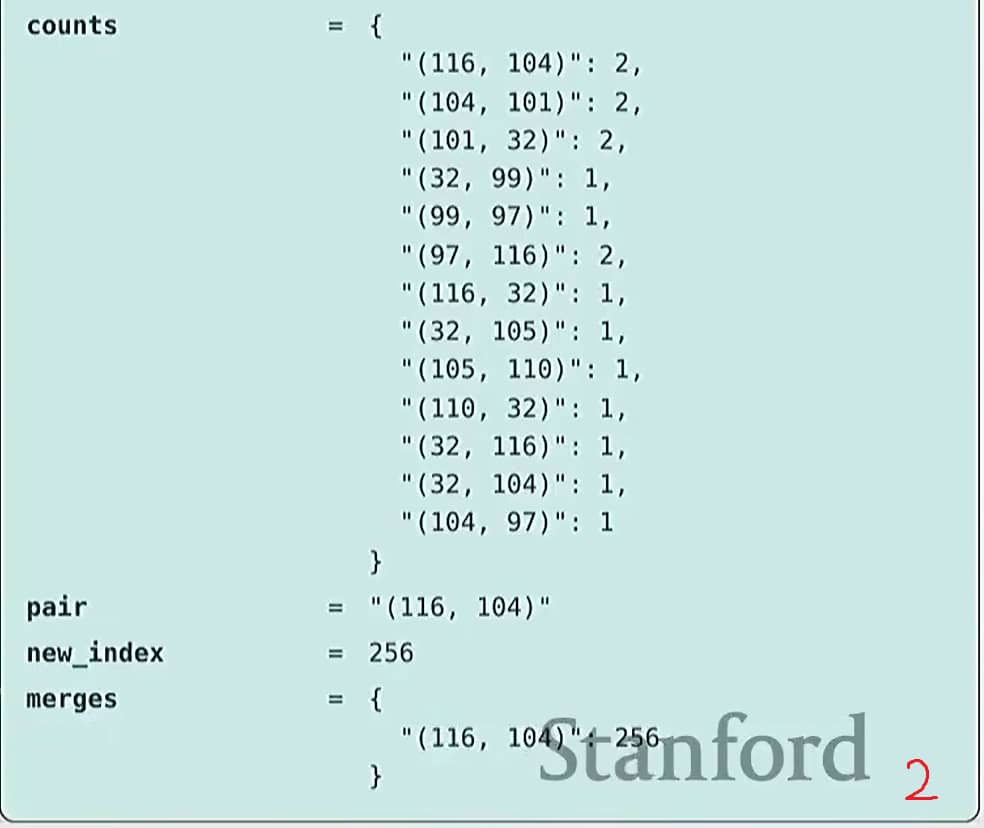





BPE 算法的可视化过程
Using the tokenizer
现在,给定一个新文本,我们可以对其进行编码。
1 | |
上述算法非常简单,所以也很低效。在作业1中,需要通过以下方式进一步拓展:
encode()目前会遍历所有合并操作,事实上只需要遍历有影响的合并操作。- 检测并保留特殊 token(例如,
<|endoftext|>)。 - 使用预分词(例如,GPT-2分词器正则表达式)。
- 尽量让实现尽可能快。
1.7 Summary
总结
- 分词器 (Tokenizer):strings <-> tokens (indices)
- Character-based, Byte-based, Word-based tokenization 都非常不优
- BPE 是一种有效的启发式方法,它会参考语料库的统计信息 (corpus statistics),以自适应地分配 tokens
- Tokenization 是一种“必要之恶”,也许有一天我们可以直接基于字节来做这件事……