本文最后更新于 2026年3月3日 晚上
引入
标准的扩散模型:将高斯噪声映射为数据。
问题:如果先验是非高斯的,例如图像编辑(image editing)任务,应当如何处理?
分析:这类任务的目标是在成对图像之间建立映射。
相关探索
对模型进行条件约束 (Ho and Salimans, 2022;Saharia et al., 2021) 或手动修改采样过程 (Meng et al., 2022; Song et al., 2020b)
这些方法缺乏理论原则性,且仅实现单向映射(从受损图像到清晰图像),丧失了循环一致性条件 (cycle-consistency condition)。
考虑直接对两个任意概率分布之间的传输过程进行建模。
基于 ODE 的流匹配方法 (Lipman et al., 2023;Albergo and Vanden-Eijnden, 2023; Liu et al., 2022a) 学习两个任意概率分布之间的确定性路径,这类方法主要应用于图像生成问题,尚未在图像翻译任务中得到研究。此外,在图像生成方面,ODE方法尚未取得与扩散模型相当的实证成果。
薛定谔桥 (De Bortoli et al., 2021) 学习两个概率分布之间的熵最优传输,但这类模型依赖昂贵的 迭代近似方法。包括扩散桥匹配 (Shi et al., 2023; Peluchetti, 2023) 在内的最新扩展方法同样需要昂贵的迭代计算。
引入
Stanford 的 Linqi Zhou 等人提出一种可扩展的替代方案,以统一基于扩散的无条件生成方法 和基于传输的分布转换方法 ,并将这一通用框架命名为 去噪扩散桥模型 [1]
本文从扩散桥的反向时间视角出发——扩散桥是一种以给定端点为条件的扩散过程,并基于这一角度建立了分布转换的通用框架。
具体而言,我们利用这一点来推广和改进架构预条件 (architecture pre-conditioning)、噪声调度 (noise schedule) 和模型采样器 (model sampler),从而降低输入敏感性并提升性能稳定性。
随后,我们分别使用 DDBMs 在像素空间和潜空间上的模型来处理高维图像。对于标准图像翻译任务,DDBMs 在图像质量 (以FID指标衡量) 和翻译保真度 (以LPIPS、MSE为衡量指标) 上均取得更优结果。此外,如果将问题简化为图像生成任务,其性能与标准扩散模型相当。
实证研究中,我们将DDBMs应用于像素空间和潜空间中的复杂图像数据集。在标准图像平移任务上,DDBMs较基线方法取得显著提升;当将源分布设为噪声以简化为图像生成任务时,DDBMs在FID指标上仍能达到与最先进方法相当的水平,尽管其设计初衷是解决更通用的任务。
知识准备
2.1 扩散模型下的生成式建模
生成模型的本质:将数据分布 q data ( x ) q_{\text{data}}(\mathbf{x}) q data ( x ) p prior ( x ) p_{\text{prior}}(\mathbf{x}) p prior ( x )
扩散过程
该过程由一组时间索引变量 { x t } t = 0 T \{\mathbf{x}_t\}_{t=0}^T { x t } t = 0 T
x 0 ∼ p 0 ( x ) : = q data ( x ) , x T ∼ p T ( x ) : = p prior ( x ) \begin{equation*}
\mathbf{x}_0 \sim p_0(\mathbf{x}) := q_{\text{data}}(\mathbf{x}), \quad \mathbf{x}_T \sim p_T(\mathbf{x}) := p_{\text{prior}}(x)
\end{equation*}
x 0 ∼ p 0 ( x ) := q data ( x ) , x T ∼ p T ( x ) := p prior ( x )
该过程可建模为如下SDE的解:
d x t = f ( x t , t ) d t + g ( t ) d w t \begin{equation}
d\mathbf{x}_t = \mathbf{f}(\mathbf{x}_t, t)dt + g(t)d\mathbf{w}_t
\end{equation}
d x t = f ( x t , t ) d t + g ( t ) d w t
其中,
f : R d × [ 0 , T ] → R d \mathbf{f}: \mathbb{R}^d \times [0, T] \to \mathbb{R}^d f : R d × [ 0 , T ] → R d g : [ 0 , T ] → R g: [0, T] \to \mathbb{R} g : [ 0 , T ] → R w t \mathbf{w}_t w t
沿着时间正向进行该扩散过程,会约束最终变量 x T \mathbf{x}_T x T p prior ( x ) p_{\text{prior}}(\mathbf{x}) p prior ( x )
d x t = ( f ( x t , t ) − g ( t ) 2 ∇ x t log p ( x t ) ) d t + g ( t ) d w t \begin{equation}
d\mathbf{x}_t = \left(\mathbf{f}(\mathbf{x}_t, t) - g(t)^2 \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_t)\right)dt + g(t)d\mathbf{w}_t
\end{equation}
d x t = ( f ( x t , t ) − g ( t ) 2 ∇ x t log p ( x t ) ) d t + g ( t ) d w t
其中,p ( x t ) : = p ( x t , t ) p(\mathbf{x}_t) := p(\mathbf{x}_t, t) p ( x t ) := p ( x t , t ) x t \mathbf{x}_t x t t t t
此外,还可推导出一个与上式具有相同边缘分布的等效确定性过程 ,称为 `概率流ODE (probability flow ODE):
d x t = [ f ( x t , t ) − 1 2 g ( t ) 2 ∇ x t log p ( x t ) ] d t \begin{equation}
d\mathbf{x}_t = \left[\mathbf{f}(\mathbf{x}_t, t) - \frac{1}{2}g(t)^2 \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_t)\right]dt
\end{equation}
d x t = [ f ( x t , t ) − 2 1 g ( t ) 2 ∇ x t log p ( x t ) ] d t
特别地,可从 x T ∼ q data ( y ) \mathbf{x}_T \sim q_{\text{data}}(y) x T ∼ q data ( y ) q data q_{\text{data}} q data
去噪分数匹配
分数 ∇ x t log p ( x t ) \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_t) ∇ x t log p ( x t )
L ( θ ) = E x t ∼ p ( x t ∣ x 0 ) , x 0 ∼ q data ( x ) , t ∼ U ( 0 , T ) [ ∥ s θ ( x t , t ) − ∇ x t log p ( x t ∣ x 0 ) ∥ 2 ] \begin{equation}
\mathcal{L}(\theta) = \mathbb{E}_{\mathbf{x}_t \sim p(\mathbf{x}_t | \mathbf{x}_0), \mathbf{x}_0 \sim q_{\text{data}}(\mathbf{x}), t \sim \mathcal{U}(0, T)} \left[\left\| s_\theta(\mathbf{x}_t, t) - \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_t | \mathbf{x}_0) \right\|^2 \right]
\end{equation}
L ( θ ) = E x t ∼ p ( x t ∣ x 0 ) , x 0 ∼ q data ( x ) , t ∼ U ( 0 , T ) [ ∥ s θ ( x t , t ) − ∇ x t log p ( x t ∣ x 0 ) ∥ 2 ]
使得上述损失的极小值 s θ ∗ ( x t , t ) s_\theta^*(\mathbf{x}_t, t) s θ ∗ ( x t , t ) p ( x t ∣ x 0 ) p(\mathbf{x}_t | \mathbf{x}_0) p ( x t ∣ x 0 ) x t = α t x 0 + σ t ϵ \mathbf{x}_t = \alpha_t \mathbf{x}_0 + \sigma_t \epsilon x t = α t x 0 + σ t ϵ α t \alpha_t α t σ t \sigma_t σ t ϵ ∼ N ( 0 , I ) \epsilon \sim N(0, I) ϵ ∼ N ( 0 , I ) x t \mathbf{x}_t x t
S N R = α t 2 / σ t 2 SNR = \alpha_t^2 / \sigma_t^2
SNR = α t 2 / σ t 2
2.2 具有固定端点的扩散过程
Doob’s h-transform: 可将 任意SDE 变成一个过定点 x T \mathbf{x}_T x T
去噪扩散桥模型示意图
DDBM采用由 漂移调整(drift adjustment) 引导的扩散过程,朝向终点 x T = y \mathbf{x}_T = y x T = y 去噪桥分数(denoising bridge score) 来学习逆转此类桥接过程,从而允许从任意 x T = y ∼ q data ( y ) \mathbf{x}_T = y \sim q_{\text{data}}(y) x T = y ∼ q data ( y ) x 0 \mathbf{x}_0 x 0 确定性的双向过程 。白色节点为随机节点,灰色节点为确定性节点。
式 (1) 所定义的扩散过程可通过 Doob’s h-transform 几乎必然地到达特定目标点 y ∈ R d y \in \mathbb{R}^d y ∈ R d
d x t = f ( x t , t ) d t + g ( t ) 2 h ( x t , t , y , T ) + g ( t ) d w t , x 0 ∼ q data ( x ) , x T = y \begin{equation}
d\mathbf{x}_t = f(\mathbf{x}_t, t)dt + g(t)^2 \mathbf{h}(\mathbf{x}_t, t, y, T) + g(t)d\mathbf{w}_t, \quad \mathbf{x}_0 \sim q_{\text{data}}(x), \, \mathbf{x}_T = y
\end{equation}
d x t = f ( x t , t ) d t + g ( t ) 2 h ( x t , t , y , T ) + g ( t ) d w t , x 0 ∼ q data ( x ) , x T = y
其中,
h ( x , t , y , T ) = ∇ x t log p ( x T ∣ x t ) ∣ x t = x , x T = y \begin{equation*}
\mathbf{h}(x, t, y, T) = \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_T | \mathbf{x}_t) \big|_{\mathbf{x}_t=x, \mathbf{x}_T=y}
\end{equation*}
h ( x , t , y , T ) = ∇ x t log p ( x T ∣ x t ) x t = x , x T = y
表示原始 SDE 生成的从 t t t T T T 对数转移核 在点 x t = x \mathbf{x}_t = x x t = x x T = y \mathbf{x}_T = y x T = y x t \mathbf{x}_t x t T T T y y y
此外,条件概率 p ( x T = y ∣ x t ) p(\mathbf{x}_T = y | \mathbf{x}_t) p ( x T = y ∣ x t ) f ( x t , t ) = 0 \mathbf{f}(\mathbf{x}_t, t) = \mathbf{0} f ( x t , t ) = 0 h \mathbf{h} h
当初始点 x 0 \mathbf{x}_0 x 0 扩散桥 ,其能够将任意给定的 x 0 \mathbf{x}_0 x 0 x T \mathbf{x}_T x T
去噪扩散桥
3.1 时间反向SDE和概率流ODE
假设扩散桥的两个端点均存在于 R d \mathbb{R}^d R d ( x 0 , x T ) = ( x , y ) ∼ q data ( x , y ) (\mathbf{x}_0, \mathbf{x}_T) = (\mathbf{x}, \mathbf{y}) \sim q_{\text{data}}(\mathbf{x}, y) ( x 0 , x T ) = ( x , y ) ∼ q data ( x , y ) q data ( x , y ) q_{\text{data}}(\mathbf{x}, \mathbf{y}) q data ( x , y ) q data ( x , y ) q_{\text{data}}(\mathbf{x}, \mathbf{y}) q data ( x , y ) q data ( x ∣ y ) q_{\text{data}}(\mathbf{x} | \mathbf{y}) q data ( x ∣ y )
VE桥(左)和VP桥(右)及其SDE可视化(上)和ODE可视化(下)
受扩散桥的启发,我们构建了具有边缘分布 q ( x t ) q(\mathbf{x}_t) q ( x t ) { x t } t = 0 T \{\mathbf{x}_t\}_{t=0}^T { x t } t = 0 T q ( x 0 , x T ) q(\mathbf{x}_0, \mathbf{x}_T) q ( x 0 , x T ) q data ( x 0 , x T ) q_{\text{data}}(\mathbf{x}_0, \mathbf{x}_T) q data ( x 0 , x T ) q ( x t ∣ x T ) q(\mathbf{x}_t | \mathbf{x}_T) q ( x t ∣ x T ) q ( x t ∣ x T ) q(\mathbf{x}_t | \mathbf{x}_T) q ( x t ∣ x T )
定理1:条件概率 q ( x t ∣ x T ) q(\mathbf{x}_t | \mathbf{x}_T) q ( x t ∣ x T )
d x t = [ f ( x t , t ) − g 2 ( t ) ( s ( x t , t , y , T ) − h ( x t , t , y , T ) ) ] d t + g ( t ) d w ^ t , x T = y \begin{equation}
d\mathbf{x}_t = \left[ \mathbf{f}(\mathbf{x}_t, t) - g^2(t) \left( \mathbf{s}(\mathbf{x}_t, t, y, T) - \mathbf{h}(\mathbf{x}_t, t, y, T) \right) \right] dt + g(t)d\hat{\mathbf{w}}_t, \, \mathbf{x}_T = y
\end{equation}
d x t = [ f ( x t , t ) − g 2 ( t ) ( s ( x t , t , y , T ) − h ( x t , t , y , T ) ) ] d t + g ( t ) d w ^ t , x T = y
及其相关的概率流ODE:
d x t = [ f ( x t , t ) − g 2 ( t ) ( 1 2 s ( x t , t , y , T ) − h ( x t , t , y , T ) ) ] d t , x T = y \begin{equation}
d\mathbf{x}_t = \left[ \mathbf{f}(\mathbf{x}_t, t) - g^2(t) \left( \frac{1}{2}\mathbf{s}(\mathbf{x}_t, t, y, T) - \mathbf{h}(\mathbf{x}_t, t, y, T) \right) \right] dt, \, \mathbf{x}_T = y
\end{equation}
d x t = [ f ( x t , t ) − g 2 ( t ) ( 2 1 s ( x t , t , y , T ) − h ( x t , t , y , T ) ) ] d t , x T = y
对于任意 ϵ > 0 \epsilon > 0 ϵ > 0 t ≤ T − ϵ t \leq T - \epsilon t ≤ T − ϵ w ^ t \hat{w}_t w ^ t s ( x , t , y , T ) = ∇ x t log q ( x t ∣ x T ) ∣ x t = x , x T = y \mathbf{s}(x, t, y, T) = \nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t | \mathbf{x}_T) \big|_{\mathbf{x}_t=x, \mathbf{x}_T=y} s ( x , t , y , T ) = ∇ x t log q ( x t ∣ x T ) x t = x , x T = y h \mathbf{h} h (5) 所定义。
特别地,上述过程的定义到 T − ϵ T - \epsilon T − ϵ
在SDE情况下,为恢复初始分布,做近似 x T − ϵ ≈ y \mathbf{x}_{T-\epsilon} \approx y x T − ϵ ≈ y ϵ \epsilon ϵ
在ODE情况下,需要从 p ( x T − ϵ ) p(\mathbf{x}_{T-\epsilon}) p ( x T − ϵ ) x T − ϵ ′ ≈ y \mathbf{x}_{T-\epsilon^\prime} \approx y x T − ϵ ′ ≈ y ϵ > ϵ ′ > 0 \epsilon > \epsilon^\prime > 0 ϵ > ϵ ′ > 0 x T − ϵ \mathbf{x}_{T-\epsilon} x T − ϵ
3.2 边缘分布与去噪桥分数匹配
定理1 中的采样过程需要对分数
s ( x , t , y , T ) = ∇ x t log q ( x t ∣ x T ) ∣ x t = x , x T = y \begin{equation*}
\mathbf{s}(x, t, y, T)=\nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t | \mathbf{x}_T)|_{\mathbf{x}_t=x, \mathbf{x}_T=y}
\end{equation*}
s ( x , t , y , T ) = ∇ x t log q ( x t ∣ x T ) ∣ x t = x , x T = y
进行近似,其中
q ( x t ∣ x T ) = ∫ x 0 q ( x t ∣ x 0 , x T ) q data ( x 0 ∣ x T ) d x 0 \begin{equation*}
q(\mathbf{x}_t | \mathbf{x}_T)=\int_{\mathbf{x}_0} q(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T) q_{\text{data}}(\mathbf{x}_0 | \mathbf{x}_T)d\mathbf{x}_0
\end{equation*}
q ( x t ∣ x T ) = ∫ x 0 q ( x t ∣ x 0 , x T ) q data ( x 0 ∣ x T ) d x 0
由于真实分数没有闭式解,此处使用神经网络来近似真实分数。这通常会产生给定数据时 x t \mathbf{x}_t x t x 0 \mathbf{x}_0 x 0 ( x 0 , x T ) (\mathbf{x}_0, \mathbf{x}_T) ( x 0 , x T ) x t \mathbf{x}_t x t
x t \mathbf{x}_t x t 闭式目标使得算法简单且可扩展。
我们详细说明如何设计边缘采样分布和易处理的分数目标,以近似真实的条件分数 ∇ x t log q ( x t ∣ x T ) \nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t | \mathbf{x}_T) ∇ x t log q ( x t ∣ x T )
关键点1:采样分布
对前一点,设计采样分布 q ( ⋅ ) q(\cdot) q ( ⋅ ) q ( x t ∣ x 0 , x T ) : = p ( x t ∣ x 0 , x T ) q(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T):=p(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T) q ( x t ∣ x 0 , x T ) := p ( x t ∣ x 0 , x T ) p ( ⋅ ) p(\cdot) p ( ⋅ ) (5) 所示的固定在两个端点的扩散分布。对于具有高斯转移核的扩散过程(例如VE、VP),我们的采样分布是如下形式的高斯分布:
q ( x t ∣ x 0 , x T ) = N ( μ ^ t , σ ^ t 2 I ) , 其中 μ ^ t = S N R T S N R t ⋅ α t α T x T + α t x 0 ( 1 − S N R T S N R t ) σ ^ t 2 = σ t 2 ( 1 − S N R T S N R t ) \begin{align}
q(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T)&=\mathcal{N}(\hat{\mu}_t, \hat{\sigma}_t^2 I), \text{其中} \notag\\
\hat{\mu}_t&=\frac{SNR_T}{SNR_t} \cdot \frac{\alpha_t}{\alpha_T} \mathbf{x}_T + \alpha_t \mathbf{x}_0 \left(1-\frac{SNR_T}{SNR_t}\right) \\
\hat{\sigma}_t^2&=\sigma_t^2 \left(1-\frac{SNR_T}{SNR_t}\right) \notag
\end{align}
q ( x t ∣ x 0 , x T ) μ ^ t σ ^ t 2 = N ( μ ^ t , σ ^ t 2 I ) , 其中 = SN R t SN R T ⋅ α T α t x T + α t x 0 ( 1 − SN R t SN R T ) = σ t 2 ( 1 − SN R t SN R T )
其中 α t \alpha_t α t σ t \sigma_t σ t S N R t = α t 2 / σ t 2 SNR_t=\alpha_t^2 / \sigma_t^2 SN R t = α t 2 / σ t 2 t t t α t = 1 \alpha_t=1 α t = 1
关键点2:训练目标
对后一点,扩散桥得益于与扩散模型类似的设置,因为预定义的信号/噪声调度会产生闭式条件分数 ∇ x t log q ( x t ∣ x 0 , x T ) \nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T) ∇ x t log q ( x t ∣ x 0 , x T ) x t ∼ q ( x t ∣ x 0 , x T ) \mathbf{x}_t \sim q(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T) x t ∼ q ( x t ∣ x 0 , x T ) s θ ( x t , x T , t ) s_\theta(\mathbf{x}_t, \mathbf{x}_T, t) s θ ( x t , x T , t )
定理2 :(Denoising Bridge Score Matching) 设 ( x 0 , x T ) ∼ q data ( x , y ) (\mathbf{x}_0, \mathbf{x}_T) \sim q_{\text{data}}(\mathbf{x}, \mathbf{y}) ( x 0 , x T ) ∼ q data ( x , y ) x t ∼ q ( x t ∣ x 0 , x T ) \mathbf{x}_t \sim q(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T) x t ∼ q ( x t ∣ x 0 , x T ) t ∼ p ( t ) t \sim p(t) t ∼ p ( t ) p ( t ) p(t) p ( t ) [ 0 , T ] [0, T] [ 0 , T ] w ( t ) w(t) w ( t )
L ( θ ) = E x t , x 0 , x T , t [ w ( t ) ∥ s θ ( x t , x T , t ) − ∇ x t log q ( x t ∣ x 0 , x T ) ∥ 2 ] \begin{equation}
\mathcal{L}(\theta)=\mathbb{E}_{\mathbf{x}_t, \mathbf{x}_0, \mathbf{x}_T, t}\left[w(t)\left\|s_\theta(\mathbf{x}_t, \mathbf{x}_T, t)-\nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T)\right\|^2\right]
\end{equation}
L ( θ ) = E x t , x 0 , x T , t [ w ( t ) ∥ s θ ( x t , x T , t ) − ∇ x t log q ( x t ∣ x 0 , x T ) ∥ 2 ]
满足 s θ ( x t , x T , t ) = ∇ x t log q ( x t ∣ x T ) s_\theta(\mathbf{x}_t, \mathbf{x}_T, t)=\nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t | \mathbf{x}_T) s θ ( x t , x T , t ) = ∇ x t log q ( x t ∣ x T )
简而言之,我们在两个端点上建立了一个易处理的扩散桥,并且通过匹配高斯桥的条件分数,我们能够学习满足边界分布 q data ( x , y ) q_{\text{data}}(x, y) q data ( x , y ) q ( x t ∣ x T ) q(\mathbf{x}_t | \mathbf{x}_T) q ( x t ∣ x T )
分布转换的广义参数化
将桥过程建立在扩散过程之上,使我们能够将分数网络参数化 s θ ( x t , x T , t ) s_\theta(\mathbf{x}_t, \mathbf{x}_T, t) s θ ( x t , x T , t )
EDM(Karras等人,2022)提出将模型输出参数化为
D θ ( x t , t ) = c skip ( t ) x t + c out ( t ) F θ ( c in ( t ) x t , c noise ( t ) ) \begin{equation*}
D_\theta(\mathbf{x}_t, t) = c_{\text{skip}}(t)\mathbf{x}_t + c_{\text{out}}(t)F_\theta(c_{\text{in}}(t)\mathbf{x}_t, c_{\text{noise}}(t))
\end{equation*}
D θ ( x t , t ) = c skip ( t ) x t + c out ( t ) F θ ( c in ( t ) x t , c noise ( t ))
其中 F θ F_\theta F θ θ \theta θ x 0 \mathbf{x}_0 x 0
分数重参数化
遵循式 (8) 中提出的采样分布,pred-x模型可以通过以下方式预测桥分数:
∇ x t log q ( x t ∣ x T ) ≈ − x t − ( S N R T S N R t ⋅ α t α T x T + α t D θ ( x t , x T , t ) ( 1 − S N R T S N R t ) ) σ t 2 ( 1 − S N R T S N R t ) = b t D θ ( x t , x T , t ) + a t x T − x t c t \begin{equation}
\nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t | \mathbf{x}_T) \approx -\frac{\mathbf{x}_t - \left( \frac{SNR_T}{SNR_t} \cdot \frac{\alpha_t}{\alpha_T} \mathbf{x}_T + \alpha_t D_\theta(\mathbf{x}_t, \mathbf{x}_T, t) \left(1 - \frac{SNR_T}{SNR_t}\right) \right)}{\sigma_t^2 \left(1 - \frac{SNR_T}{SNR_t}\right)} = \frac{b_t D_\theta(\mathbf{x}_t, \mathbf{x}_T, t) + a_t \mathbf{x}_T - \mathbf{x}_t}{c_t}
\end{equation}
∇ x t log q ( x t ∣ x T ) ≈ − σ t 2 ( 1 − SN R t SN R T ) x t − ( SN R t SN R T ⋅ α T α t x T + α t D θ ( x t , x T , t ) ( 1 − SN R t SN R T ) ) = c t b t D θ ( x t , x T , t ) + a t x T − x t
∇ x t log q ( x t ∣ x T ) ≈ b t D θ ( x t , x T , t ) + a t x T − x t c t \nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t | \mathbf{x}_T) \approx \frac{b_t D_\theta(\mathbf{x}_t, \mathbf{x}_T, t) + a_t \mathbf{x}_T - \mathbf{x}_t}{c_t}
∇ x t log q ( x t ∣ x T ) ≈ c t b t D θ ( x t , x T , t ) + a t x T − x t
缩放函数和损失权重
借鉴 Karras 等人(2022)的研究,令
a t = α t α T ⋅ S N R T S N R t , b t = α t ( 1 − S N R T S N R t ) , c t = σ t 2 ( 1 − S N R T S N R t ) \begin{equation*}
a_t = \frac{\alpha_t}{\alpha_T} \cdot \frac{SNR_T}{SNR_t}, \quad b_t = \alpha_t(1 - \frac{SNR_T}{SNR_t}), \quad c_t = \sigma_t^2(1 - \frac{SNR_T}{SNR_t})
\end{equation*}
a t = α T α t ⋅ SN R t SN R T , b t = α t ( 1 − SN R t SN R T ) , c t = σ t 2 ( 1 − SN R t SN R T )
可推导出缩放函数和权重函数 w ( t ) w(t) w ( t )
c in ( t ) = 1 a t 2 σ T 2 + b t 2 σ 0 2 + 2 a t b t σ 0 T + c t , c out ( t ) = a t 2 ( σ T 2 σ 0 2 − σ 0 T 2 ) + σ 0 2 c t × c in ( t ) c skip ( t ) = ( b t σ 0 2 + a t σ 0 T ) × c in 2 ( t ) , w ( t ) = 1 c out ( t ) 2 , c noise ( t ) = 1 4 log ( t ) \begin{align}
&c_{\text{in}}(t) = \frac{1}{\sqrt{a_t^2 \sigma_T^2 + b_t^2 \sigma_0^2 + 2a_t b_t \sigma_{0T} + c_t}}, \ c_{\text{out}}(t) = \sqrt{a_t^2 (\sigma_T^2 \sigma_0^2 - \sigma_{0T}^2) + \sigma_0^2 c_t} \times c_{\text{in}}(t) \\
&c_{\text{skip}}(t) = \left( b_t \sigma_0^2 + a_t \sigma_{0T} \right) \times c_{\text{in}}^2(t), \ w(t) = \frac{1}{c_{\text{out}}(t)^2}, \ c_{\text{noise}}(t) = \frac{1}{4} \log(t)
\end{align}
c in ( t ) = a t 2 σ T 2 + b t 2 σ 0 2 + 2 a t b t σ 0 T + c t 1 , c out ( t ) = a t 2 ( σ T 2 σ 0 2 − σ 0 T 2 ) + σ 0 2 c t × c in ( t ) c skip ( t ) = ( b t σ 0 2 + a t σ 0 T ) × c in 2 ( t ) , w ( t ) = c out ( t ) 2 1 , c noise ( t ) = 4 1 log ( t )
其中,σ 0 2 \sigma_0^2 σ 0 2 σ T 2 \sigma_T^2 σ T 2 σ 0 T \sigma_{0T} σ 0 T x 0 \mathbf{x}_0 x 0 x T \mathbf{x}_T x T
与EDM相比,唯一额外的超参数是 σ T \sigma_T σ T σ 0 T \sigma_{0T} σ 0 T x T \mathbf{x}_T x T x 0 \mathbf{x}_0 x 0 σ t = t \sigma_t = t σ t = t σ T 2 = σ 0 2 + T 2 \sigma_T^2 = \sigma_0^2 + T^2 σ T 2 = σ 0 2 + T 2 ϵ \epsilon ϵ x T = x 0 + T ϵ \mathbf{x}_T = \mathbf{x}_0 + T\epsilon x T = x 0 + T ϵ σ 0 T = σ 0 2 \sigma_{0T} = \sigma_0^2 σ 0 T = σ 0 2 S N R T / S N R t = t 2 / T 2 SNR_T/SNR_t = t^2/T^2 SN R T / SN R t = t 2 / T 2
可以证明,此时的缩放函数会简化为EDM中的缩放函数。详细推导见附录A.5。
广义时间反演 Generalized time-reversal
由于概率流ODE与分类器引导(Dhariwal和Nichol,2021;Ho和Salimans,2022)存在相似性,我们可以引入一个额外的参数 w w w
d x t = [ f ( x t , t ) − g 2 ( t ) ( 1 2 s ( x t , t , y , T ) − w h ( x t , t , y , T ) ) ] d t , x T = y \begin{equation}
d\mathbf{x}_t = \left[ \mathbf{f}(\mathbf{x}_t, t) - g^2(t) \left( \frac{1}{2} \mathbf{s}(\mathbf{x}_t, t, y, T) - w \mathbf{h}(\mathbf{x}_t, t, y, T) \right) \right] dt, \quad \mathbf{x}_T = y
\end{equation}
d x t = [ f ( x t , t ) − g 2 ( t ) ( 2 1 s ( x t , t , y , T ) − w h ( x t , t , y , T ) ) ] d t , x T = y
这使得由此产生的概率流ODE能够生成范围更广的 x t \mathbf{x}_t x t
去噪扩散桥的随机采样
使用纯粹ODE路径的问题: 扩散桥具有给定数据的固定起点 x T = y ∼ q data ( y ) \mathbf{x}_T = y \sim q_{\text{data}}(y) x T = y ∼ q data ( y )
解决方法:在采样过程中引入噪声,以提高采样质量和多样性。
高阶混合采样器。我们的采样器基于先前的高阶 ODE 采样器(Karras 等人,2022)构建,该采样器将采样步骤离散化为具有递减间隔的 t N > t N − 1 > ⋯ > t 0 t_N > t_{N-1} > \cdots > t_0 t N > t N − 1 > ⋯ > t 0 t i − 1 t_{i-1} t i − 1 t i t_i t i [ t i − s ( t i − t i − 1 ) , t i ] [t_i - s(t_i - t_{i-1}), t_i] [ t i − s ( t i − t i − 1 ) , t i ] [ t i − 1 , t i − s ( t i − t i − 1 ) ] [t_{i-1}, t_i - s(t_i - t_{i-1})] [ t i − 1 , t i − s ( t i − t i − 1 )]
去噪扩散桥混合采样器
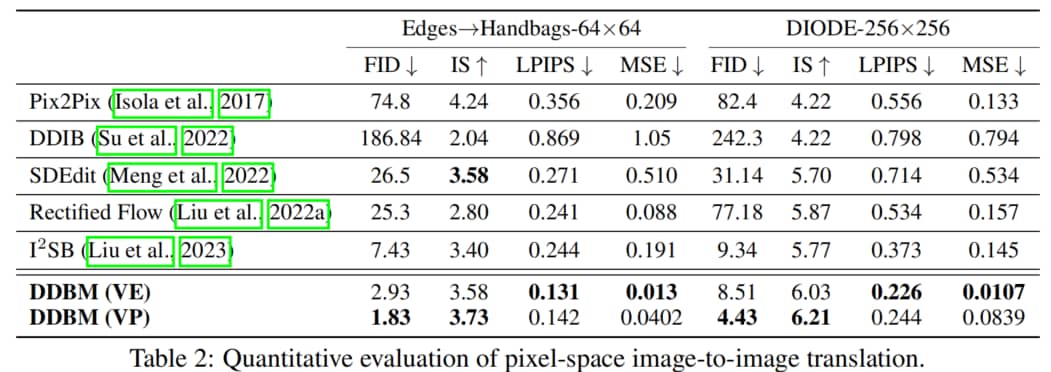
像素空间图像翻译任务的定量评估
消融实验
无条件图像生成的性能评估
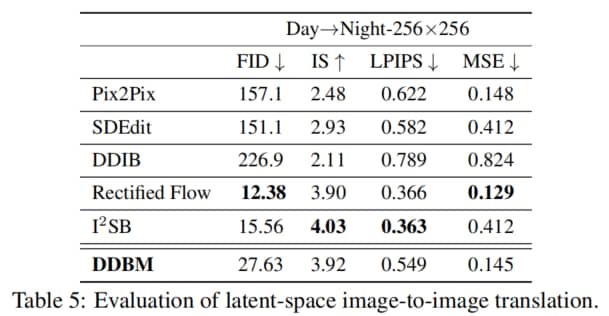
(日→夜)隐空间上的图像生成
Edges→Handbags示例
DIODE示例
6 相关工作与特殊情况
相关工作
扩散模型。扩散模型的进展(Sohl-Dickstein等人,2015;Ho等人,2020;Song等人,2020b)提升了图像生成的最先进水平,并超越了生成对抗网络(GANs)(Goodfellow等人,2014)。扩散模型的成功与其重要的设计选择密不可分,例如网络设计(Song等人,2020b;Karras等人,2022;Nichol和Dhariwal,2021;Hoogeboom等人,2023;Peebles和Xie,2023)、改进的噪声调度(Nichol和Dhariwal,2021;Karras等人,2022;Peebles和Xie,2023)、更快更准确的采样器(Song等人,2020a;Lu等人,2022a;b;Zhang和Chen,2022)以及引导方法(Dhariwal和Nichol,2021;Ho和Salimans,2022)。鉴于关于无条件生成的扩散模型已有大量文献,且这些文献在很大程度上基于上述各种设计选择,我们旨在设计我们的桥模型公式,以实现与这些文献的无缝整合。为此,我们采用时间反转的视角来直接扩展这些方法。
扩散桥、薛定谔桥与杜布h变换。扩散桥(Särkkä和Solin,2019)是概率论中的常用工具,近年来在生成建模领域得到了积极研究(Liu等人,2022b;Somnath等人,2023;De Bortoli等人,2021;Peluchetti;2023)。Heng等人(2021)研究了以固定起点/终点为条件的扩散桥,并在给定分数∇ₓᵗlog p(xₜ)近似的情况下,学习模拟桥的时间反转过程。最近,Liu等人(2022b)不再考虑具有固定端点的桥,而是利用杜布h变换在任意分布之间构建桥。通过在训练过程中模拟整个路径并进行分数匹配,学习正向桥。相比之下,其他工作(Somnath等人,2023;Peluchetti)虽然也采用杜布h变换,但提出了用于正向时间生成的无模拟算法。Delbracio和Milanfar(2023)同样构建了用于直接迭代的布朗桥,并成功应用于图像恢复任务。另一种方法是De Bortoli等人(2021)提出的迭代比例拟合(IPF),用于高效解决不同分布间转换的薛定谔桥(SB)问题。Liu等人(2023)基于一类可处理的薛定谔桥,提出了一种无模拟算法,并在图像翻译任务中表现出优异性能。最近,通过IPF扩展薛定谔桥,桥匹配(Shi等人,2023)提出使用迭代马尔可夫拟合来解决薛定谔桥问题。Peluchetti(2023)也开发了一种类似的算法用于分布转换。与我们的工作更相关的是Li等人(2023)的研究,其提出在离散时间中直接反转布朗桥以实现分布转换。而我们的方法则展示了如何在连续时间中基于现有的VP和VE扩散过程构建桥模型,且大多数先前工作中考虑的布朗桥只是VE桥的一个特例。我们还证明,若实现得当,VP桥能取得非常优异的实证性能。尽管Peluchetti的研究中也采用正向时间扩散的视角,并提出了VE/VP桥调度,但我们的框架具有额外的实证优势(可复用扩散模型的设计)和理论优势(与OT流匹配(Lipman等人,2023;Tong等人,2023b)及整流流(Liu等人,2022a)相关联)。
流与最优传输。基于流匹配的工作(Lipman等人,2023;Tong等人,2023b;Pooladian等人,2023;Tong等人,2023a)学习基于ODE的传输映射,以连接两个分布。Lipman等人(2023)证明,通过匹配预定义传输映射的速度场,可构建与扩散模型相当的强大生成模型。为改进这一方法,Tong等人(2023b)、Pooladian等人(2023)利用小批量无模拟最优传输(OT)来挖掘分布间的潜在耦合。整流流(Liu等人,2022a)直接构建最优传输桥,并使用神经网络拟合中间速度场。另一类工作利用随机插值(Albergo和Vanden-Eijnden,2023)构建流模型,直接避免使用杜布h函数,并提供了一种简便的分布间插值映射构建方法。Albergo等人(2023)提出了基于随机插值的通用理论,统一了流模型和扩散模型,并表明可从ODE和SDE两种视角构建桥。与这些方法不同,我们的模型采用了与这类模型不同的去噪桥分数匹配损失。从这一视角出发,我们能够将扩散模型中许多已被证实成功的设计(这些设计无法直接应用于上述工作)扩展到桥框架中,在推动图像翻译任务达到新高度的同时,保持在无条件生成任务中的优异性能。
6.1 去噪扩散桥模型的特殊情况
情况1:无条件扩散过程
对于无条件扩散过程(将数据映射到噪声),我们首先可以证明,当 x T ∼ q data ( y ∣ x ) = N ( α T x , σ T 2 I ) \mathbf{x}_T \sim q_{\text{data}}(y | x) = \mathcal{N}(\alpha_T x, \sigma_T^2 I) x T ∼ q data ( y ∣ x ) = N ( α T x , σ T 2 I ) p ( x 0 ) = q data ( x ) p(\mathbf{x}_0) = q_{\text{data}}(x) p ( x 0 ) = q data ( x ) p ( x t ) p(\mathbf{x}_t) p ( x t ) x T \mathbf{x}_T x T
p ( x t ∣ x 0 ) = N ( α t x 0 , σ t I ) \begin{equation}
p(\mathbf{x}_t | \mathbf{x}_0) = \mathcal{N}(\alpha_t \mathbf{x}_0, \sigma_t I)
\end{equation}
p ( x t ∣ x 0 ) = N ( α t x 0 , σ t I )
进一步可以证明,当从高斯分布中采样 x T \mathbf{x}_T x T
情况2:OT-Flow Matching and Rectified Flow
OT流匹配(Lipman等人,2023;Tong等人,2023b)和整流流(Liu等人,2022a)。这些工作学习匹配通过ODE(而非SDE)定义的确定性动态。在这种特定情况下,它们处理由 x T − x 0 \mathbf{x}_T - \mathbf{x}_0 x T − x 0
为说明我们的框架对这类方法的泛化性,首先定义一族扩散桥,其方差由 c ∈ ( 0 , 1 ) c \in (0,1) c ∈ ( 0 , 1 ) p ( x t ∣ x 0 , x T ) = N ( μ ^ t , c 2 σ ^ t 2 I ) p(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T) = \mathcal{N}(\hat{\mu}_t, c^2 \hat{\sigma}_t^2 I) p ( x t ∣ x 0 , x T ) = N ( μ ^ t , c 2 σ ^ t 2 I ) μ ^ t \hat{\mu}_t μ ^ t σ ^ t \hat{\sigma}_t σ ^ t σ t 2 = c 2 t \sigma_t^2 = c^2 t σ t 2 = c 2 t x 0 \mathbf{x}_0 x 0 x t \mathbf{x}_t x t T = 1 T=1 T = 1 x t \mathbf{x}_t x t
lim c → 0 [ f ( x t , t ) − c 2 g 2 ( t ) ( 1 2 ∇ x t log p ( x t ∣ x 0 , x 1 ) − ∇ x t log p ( x 1 ∣ x t ) ) ] = x 1 − x 0 \begin{equation}
\lim_{c \to 0} \left[ f(\mathbf{x}_t, t) - c^2 g^2(t) \left( \frac{1}{2} \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_1) - \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_1 | \mathbf{x}_t) \right) \right] = \mathbf{x}_1 - \mathbf{x}_0
\end{equation}
c → 0 lim [ f ( x t , t ) − c 2 g 2 ( t ) ( 2 1 ∇ x t log p ( x t ∣ x 0 , x 1 ) − ∇ x t log p ( x 1 ∣ x t ) ) ] = x 1 − x 0
图3:与最相关基线方法的定性比较。
其中,括号内的项是给定 x 0 \mathbf{x}_0 x 0 x 1 \mathbf{x}_1 x 1 x T − x 0 \mathbf{x}_T - \mathbf{x}_0 x T − x 0 x T \mathbf{x}_T x T
参考文献
[1] Denoising Diffusion Bridge Models
Zhou, L., Lou, A., Khanna, S., & Ermon, S. ICLR 2024, https://arxiv.org/abs/2309.16948 .
[2] Diffusion Bridge Implicit Models
Zheng, K., He, G., Chen, J., Bao, F., & Zhu, J. ICLR 2025, https://arxiv.org/abs/2405.15885 .
[3] Reverse-time diffusion equation models
B.D. Anderson. Stochastic Processes and their Applications, Vol 12(3), pp. 313--326. Elsevier. 1982.