本文最后更新于 2026年1月16日 上午
2025/08/04 - 至今
主要参考资料
本篇文章主要基于《Elucidating the Design Space of Diffusion-Based
数学推导参考:B站讲解 Double童发发 - EDM论文讲解之扩散模型通用框架系列 、苏剑林-科学空间-一般框架之SDE篇
整体脉络、相关图片参考:B站讲座 -【双语】NVIDIA - EDM 以及 论文相关博文
本文按照上述讲座顺序,分为四个部分:
第一部分:通用框架
第二部分:确定性采样
第三部分:随机采样
第四部分:预处理与训练
核心问题:如何将Diffusion Models表达在一个统一框架下?
回顾
Score Matching
加噪公式:x t = x 0 + σ t ε \mathbf{x}_t = \mathbf{x}_0 + \sigma_t \varepsilon x t = x 0 + σ t ε
概率分布形式:p ( x t ∣ x 0 ) = N ( x t ; x 0 , σ t 2 I ) p(\mathbf{x}_t | \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_t;\mathbf{x}_0,\sigma_t^2 \mathbf{I}) p ( x t ∣ x 0 ) = N ( x t ; x 0 , σ t 2 I )
Flow Matching
加噪公式:x t = ( 1 − t ) x 0 + t ε \mathbf{x}_t = (1-t) \mathbf{x}_0 + t \varepsilon x t = ( 1 − t ) x 0 + tε
概率分布形式:p ( x t ∣ x 0 ) = N ( x t ; ( 1 − t ) x 0 , t 2 I ) p(\mathbf{x}_t | \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_t; (1-t)\mathbf{x}_0, t^2 \mathbf{I}) p ( x t ∣ x 0 ) = N ( x t ; ( 1 − t ) x 0 , t 2 I )
DDPM/DDIM
加噪公式:x t = α ˉ t x 0 + 1 − α ˉ t ε \mathbf{x}_t = \sqrt{\bar{\alpha}_t} \mathbf{x}_0 + \sqrt{1-\bar{\alpha}_t} \varepsilon x t = α ˉ t x 0 + 1 − α ˉ t ε
概率分布形式:p ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) p(\mathbf{x}_t | \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1-\bar{\alpha}_t)\mathbf{I}) p ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I )
Song等人将其 前向SDE 定义为:
d x = f ( x , t ) d t + g ( t ) d ω t \mathrm{d}\boldsymbol{x} = \boldsymbol{f}(\boldsymbol{x}, t)\mathrm{d}t + g(t)\mathrm{d}\omega_t
d x = f ( x , t ) d t + g ( t ) d ω t
其中
ω t \omega_t ω t f ( ⋅ , t ) : R d → R d \boldsymbol{f}(\cdot, t): \mathbb{R}^d \to \mathbb{R}^d f ( ⋅ , t ) : R d → R d 漂移系数 ;g ( ⋅ ) : R → R g(\cdot): \mathbb{R} \to \mathbb{R} g ( ⋅ ) : R → R 扩散系数 d d d
在 方差保持(VP) 和 方差爆炸(VE) 公式中,这两个系数的选择不同;且 f ( ⋅ , t ) \boldsymbol{f}(\cdot, t) f ( ⋅ , t ) f ( x , t ) = f ( t ) x \boldsymbol{f}(\boldsymbol{x}, t) = f(t)\boldsymbol{x} f ( x , t ) = f ( t ) x f ( ⋅ ) : R → R f(\cdot): \mathbb{R} \to \mathbb{R} f ( ⋅ ) : R → R
d x = f ( t ) x d t + g ( t ) d ω t \mathrm{d}\boldsymbol{x} = f(t)\boldsymbol{x}\mathrm{d}t + g(t)\mathrm{d}\omega_t
d x = f ( t ) x d t + g ( t ) d ω t
该SDE的扰动核 具有如下一般形式:
p 0 t ( x ( t ) ∣ x ( 0 ) ) = N ( x ( t ) ; s ( t ) x ( 0 ) , s 2 ( t ) σ 2 ( t ) I ) p_{0t}(\boldsymbol{x}(t) \mid \boldsymbol{x}(0)) = \mathcal{N}\big(\boldsymbol{x}(t);\ s(t)\boldsymbol{x}(0),\ s^2(t)\sigma^2(t)\boldsymbol{I}\big)
p 0 t ( x ( t ) ∣ x ( 0 )) = N ( x ( t ) ; s ( t ) x ( 0 ) , s 2 ( t ) σ 2 ( t ) I )
其中 N ( x ; μ , Σ ) \mathcal{N}(\boldsymbol{x};\ \boldsymbol{\mu},\ \boldsymbol{\Sigma}) N ( x ; μ , Σ ) 均值为 μ \boldsymbol{\mu} μ Σ \boldsymbol{\Sigma} Σ 在 x \boldsymbol{x} x
s ( t ) = exp ( ∫ 0 t f ( ξ ) d ξ ) , σ ( t ) = ∫ 0 t g 2 ( ξ ) s 2 ( ξ ) d ξ s(t) = \exp\left( \int_0^t f(\xi)\mathrm{d}\xi \right), \quad \sigma(t) = \sqrt{ \int_0^t \frac{g^2(\xi)}{s^2(\xi)} \mathrm{d}\xi }
s ( t ) = exp ( ∫ 0 t f ( ξ ) d ξ ) , σ ( t ) = ∫ 0 t s 2 ( ξ ) g 2 ( ξ ) d ξ
边缘分布 p t ( x ) p_t(\boldsymbol{x}) p t ( x ) x ( 0 ) \boldsymbol{x}(0) x ( 0 )
p t ( x ) = ∫ R d p 0 t ( x ∣ x 0 ) p data ( x 0 ) d x 0 p_t(\boldsymbol{x}) = \int_{\mathbb{R}^d} p_{0t}(\boldsymbol{x} \mid \boldsymbol{x}_0)\, p_{\text{data}}(\boldsymbol{x}_0)\,\mathrm{d}\boldsymbol{x}_0
p t ( x ) = ∫ R d p 0 t ( x ∣ x 0 ) p data ( x 0 ) d x 0
Song等人定义了 概率流ODE ,使采样出的 x \boldsymbol{x} x p t ( x ) p_t(\boldsymbol{x}) p t ( x )
d x = [ f ( t ) x − 1 2 g ( t ) 2 ∇ x log p t ( x ) ] d t \mathrm{d}\boldsymbol{x} = \left[ f(t)\boldsymbol{x} - \frac{1}{2}g(t)^2 \nabla_{\boldsymbol{x}} \log p_t(\boldsymbol{x}) \right] \mathrm{d}t
d x = [ f ( t ) x − 2 1 g ( t ) 2 ∇ x log p t ( x ) ] d t
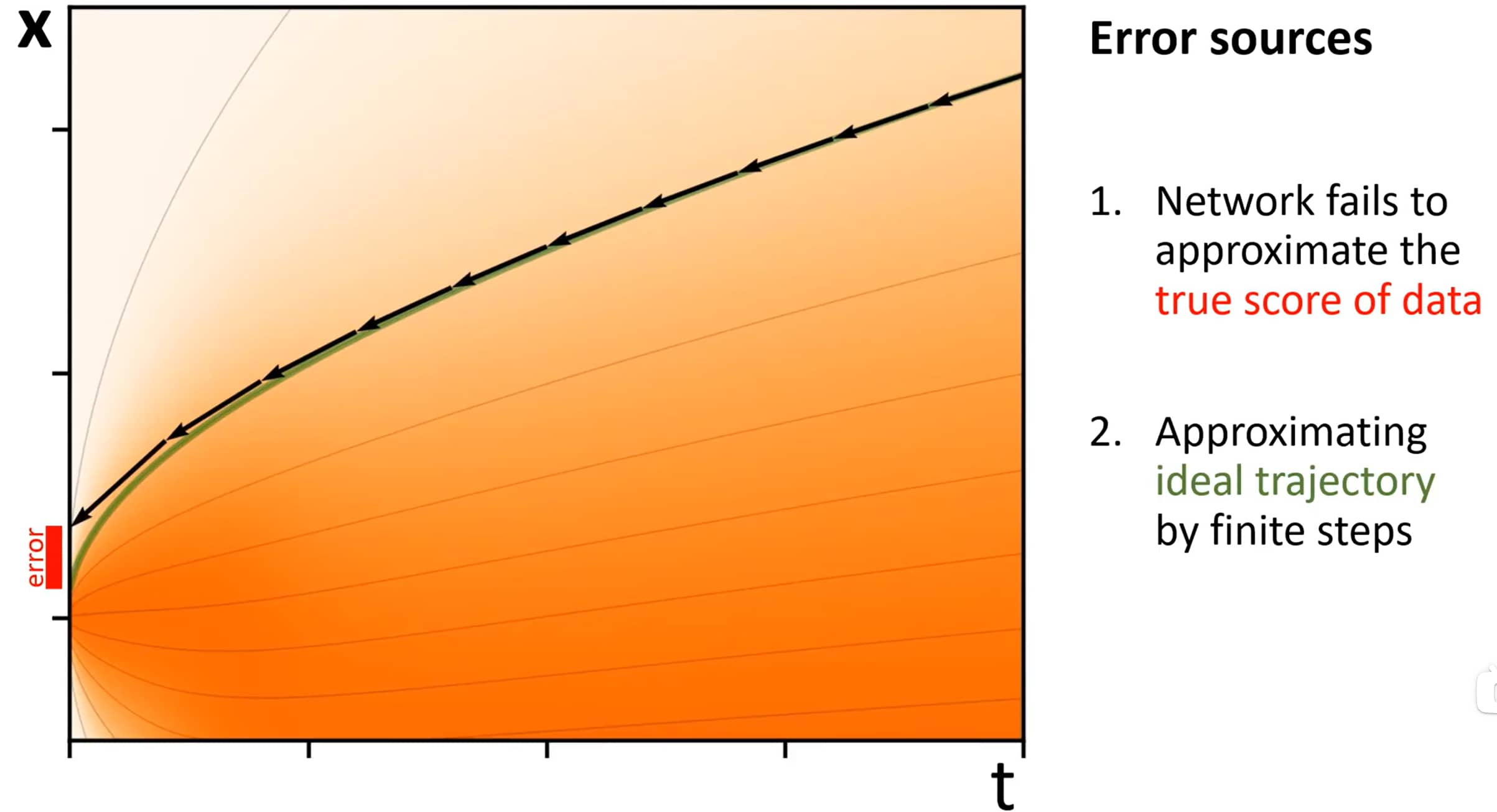
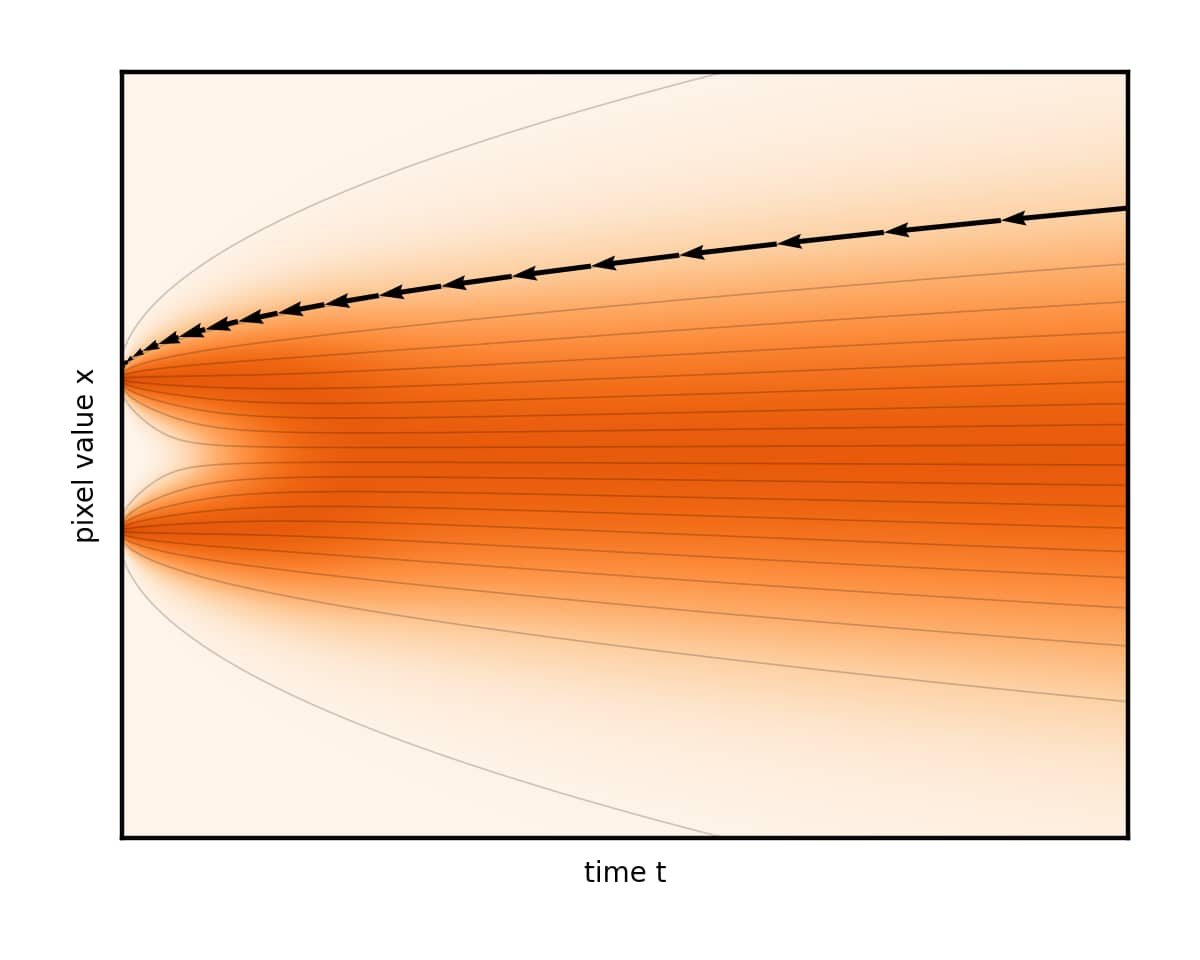
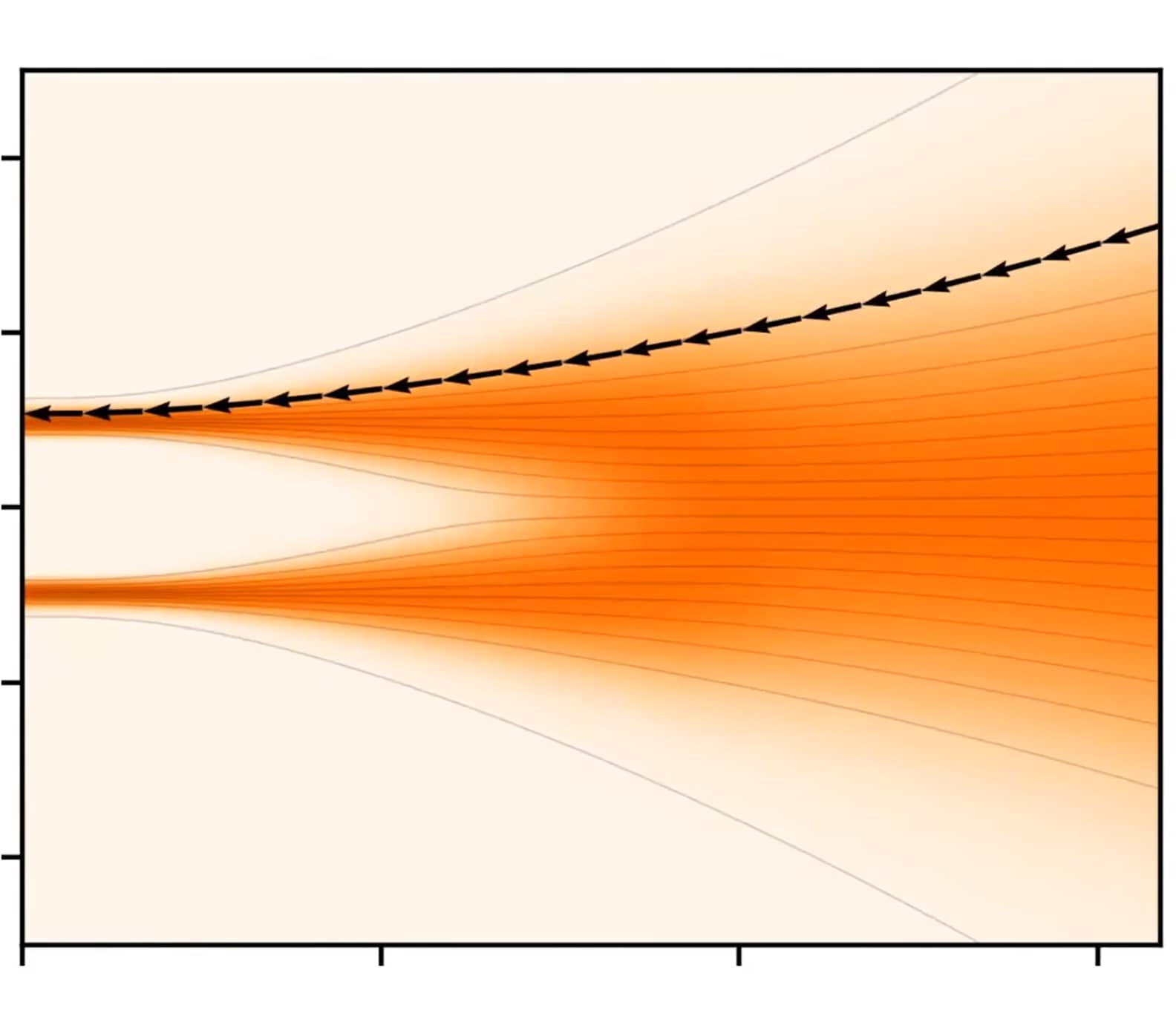
通过连续时间随机过程将数据扰动至纯噪声
SDE视角下,扩散模型出现的两个问题
网络无法逼近数据的 真实得分 :这导致采样轨迹朝着错误方向演进。上图当前轨迹(黑色)为错误采样链,在左侧与目标之间存在error;
通过有限步长逼近 理想轨迹 :为了近似绿色轨迹,如果每步太长,则会显著偏离目标轨迹;如果每步太短,则会消耗过多计算资源。
事实上,以上两点分别对应于 Traning过程 和 Sampling过程 。
轨迹
确定性采样的改进
基于ODE的确定性采样
不改变训练过程,只关注于采样过程。
改进Heun步
概率流ODE的改造
原始ODE公式围绕函数 f f f g g g 间接推导 。由于概率流ODE的核心是边缘分布 ,所以我们的目标是 直接基于 σ ( t ) \sigma(t) σ ( t ) s ( t ) s(t) s ( t ) 。
概率流ODE的核心特征是:若将服从分布 p ( x a ; σ ( t a ) ) p(x_a;\sigma(t_a)) p ( x a ; σ ( t a )) x a x_a x a t a t_a t a t b t_b t b x b x_b x b p ( x b ; σ ( t b ) ) p(x_b;\sigma(t_b)) p ( x b ; σ ( t b ))
d x = − σ ˙ ( t ) σ ( t ) ∇ x log p ( x ; σ ( t ) ) d t (1) dx = -\dot{\sigma}(t)\sigma(t)\nabla_x \log p(x;\sigma(t))dt \tag{1}
d x = − σ ˙ ( t ) σ ( t ) ∇ x log p ( x ; σ ( t )) d t ( 1 )
其中,符号“˙ \dot{} ˙ ∇ x log p ( x ; σ ) \nabla_x \log p(x;\sigma) ∇ x log p ( x ; σ )
关键事实:概率流ODE的每一种具体形式,本质上都是同一标准ODE的重新参数化;改变 σ ( t ) \sigma(t) σ ( t ) t t t s ( t ) s(t) s ( t ) x \boldsymbol{x} x
去噪得分匹配
提出一种 D θ D_\theta D θ s θ s_\theta s θ ε θ \varepsilon_\theta ε θ v θ v_\theta v θ
假设 D ( x ; σ ) D(\boldsymbol{x};\sigma) D ( x ; σ ) x = y + n \boldsymbol{x} = \boldsymbol{y} + \boldsymbol{n} x = y + n y \boldsymbol{y} y n \boldsymbol{n} n σ \sigma σ σ \sigma σ p d a t a p_{data} p d a t a L 2 L_2 L 2
E y ∼ p d a t a E n ∼ N ( 0 , σ 2 I ) ∥ D ( y + n ; σ ) − y ∥ 2 2 (2) \mathbb{E}_{\boldsymbol{y} \sim p_{data}} \mathbb{E}_{\boldsymbol{n} \sim \mathcal{N}(0,\sigma^2 I)} \|D(y + n;\sigma) - y\|_2^2 \tag{2}
E y ∼ p d a t a E n ∼ N ( 0 , σ 2 I ) ∥ D ( y + n ; σ ) − y ∥ 2 2 ( 2 )
有,
∇ x log p ( x ; σ ) = D ( x ; σ ) − x σ 2 (3) \nabla_x \log p(x;\sigma) = \frac{D(x;\sigma) - x}{\sigma^2} \tag{3}
∇ x log p ( x ; σ ) = σ 2 D ( x ; σ ) − x ( 3 )
出噪声成分,而式 <a href="#eq:1">(1)</a> 会随时间对该噪声成分进行放大(或减弱)。
图1展示了理想状态下 D D D D ( x ; σ ) D(x;\sigma) D ( x ; σ ) D θ ( x ; σ ) D_\theta(x;\sigma) D θ ( x ; σ ) <a href="#eq:2">(2)</a> 进行训练。需注意,D θ D_\theta D θ x x x
与时间相关的信号缩放
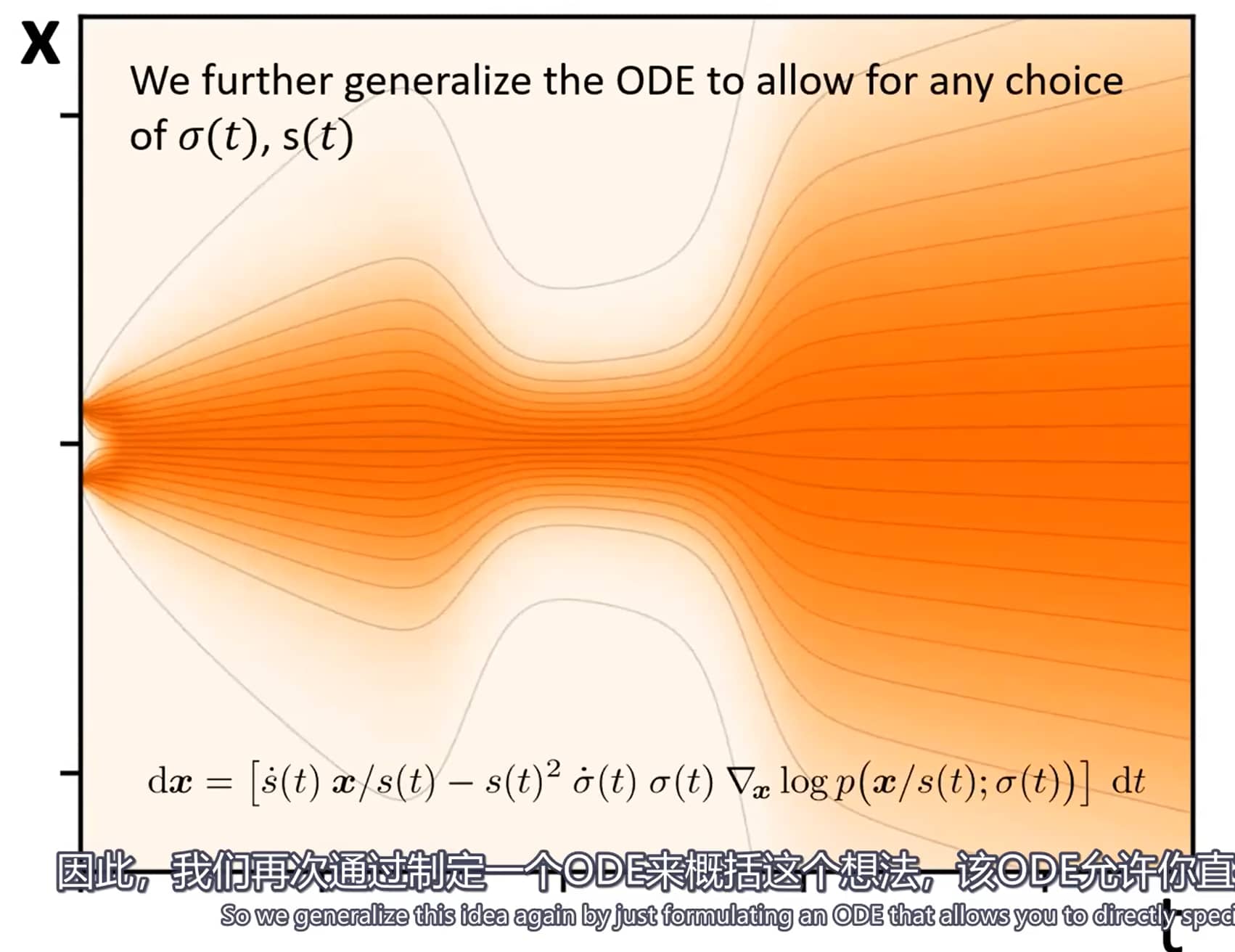
部分方法(见附录C.1)会引入额外的缩放调度函数 s ( t ) s(t) s ( t ) x = s ( t ) x ^ x = s(t)\hat{x} x = s ( t ) x ^ x ^ \hat{x} x ^ <a href="#eq:1">(1)</a> 的推广形式:
d x = [ s ˙ ( t ) s ( t ) x − s ( t ) 2 σ ˙ ( t ) σ ( t ) ∇ x log p ( x s ( t ) ; σ ( t ) ) ] d t (4) dx = \left[ \frac{\dot{s}(t)}{s(t)} x - s(t)^2 \dot{\sigma}(t) \sigma(t) \nabla_x \log p\left( \frac{x}{s(t)} ; \sigma(t) \right) \right] dt \tag{4}
d x = [ s ( t ) s ˙ ( t ) x − s ( t ) 2 σ ˙ ( t ) σ ( t ) ∇ x log p ( s ( t ) x ; σ ( t ) ) ] d t ( 4 )
需注意,在评估得分函数时,我们会显式取消对 x x x p ( x ; σ ) p(x;\sigma) p ( x ; σ ) s ( t ) s(t) s ( t )
在扩散模型研究中,提升采样输出质量和/或降低采样计算成本是常见的研究方向。我们的假设是:与采样过程相关的选择在很大程度上独立于其他组件,例如网络架构和训练细节。换句话说,D θ D_\theta D θ σ ( t ) \sigma(t) σ ( t ) s ( t ) s(t) s ( t ) { t i } \{t_i\} { t i } D θ D_\theta D θ
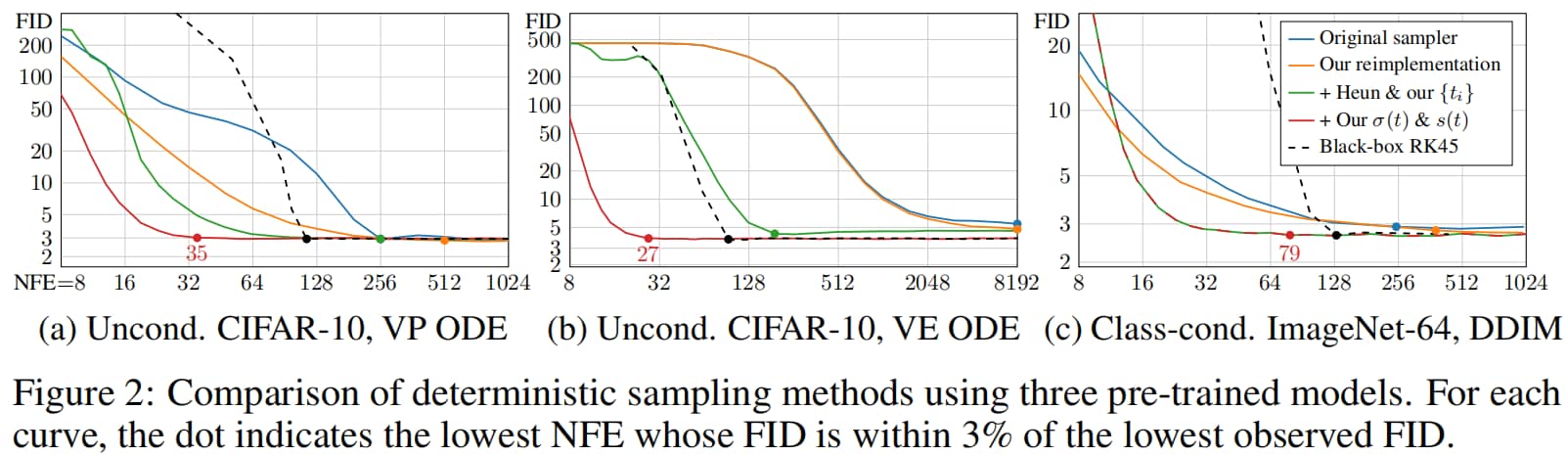
为验证这一假设,我们在三个预训练模型上评估了不同的采样器,每个模型分别代表一种不同的理论框架和模型类别。我们首先使用这些模型的原始采样器实现来测量基准结果,然后利用表1中的公式将这些采样器纳入我们的统一框架,之后再应用我们提出的改进方案。这使我们能够评估不同的实际选择方案,并提出适用于所有模型的采样过程通用性改进。
我们以弗雷歇初始距离(Fréchet Inception Distance, FID)[15]作为结果质量的评估指标,该指标通过计算50000张生成图像与所有可用真实图像之间的距离得到。图2展示了FID随神经函数评估次数(Neural Function Evaluations, NFE)变化的情况,其中NFE指生成单张图像所需的 D θ D_\theta D θ D θ D_\theta D θ
原始确定性采样器的结果以蓝色显示,而这些方法在我们统一框架中的重新实现版本(橙色)得到了相近但始终更优的结果。这种差异源于原始实现中的某些疏漏,以及我们在DDIM(模型)情况下对离散噪声水平的更细致处理;具体参见附录C。需注意,尽管各原始代码库的结构差异很大,但我们的重新实现版本完全由算法1和表1定义。
离散化与高阶积分器
待求解的ODE可通过将式(3)代入式(4)得到——此举可定义逐点梯度,而ODE的解可通过数值积分求得,即对离散时间区间取有限步长。这一过程需同时选择积分方案(如欧拉法或龙格-库塔法的变体)与离散采样时间 { t 0 , t 1 , … , t N } \{t_0, t_1, \dots, t_N\} { t 0 , t 1 , … , t N }
==========================
对常微分方程(ODE)进行数值求解,本质上是对其真实解轨迹的近似。在每一步迭代中,求解器都会引入截断误差,该误差会在 N N N N N N
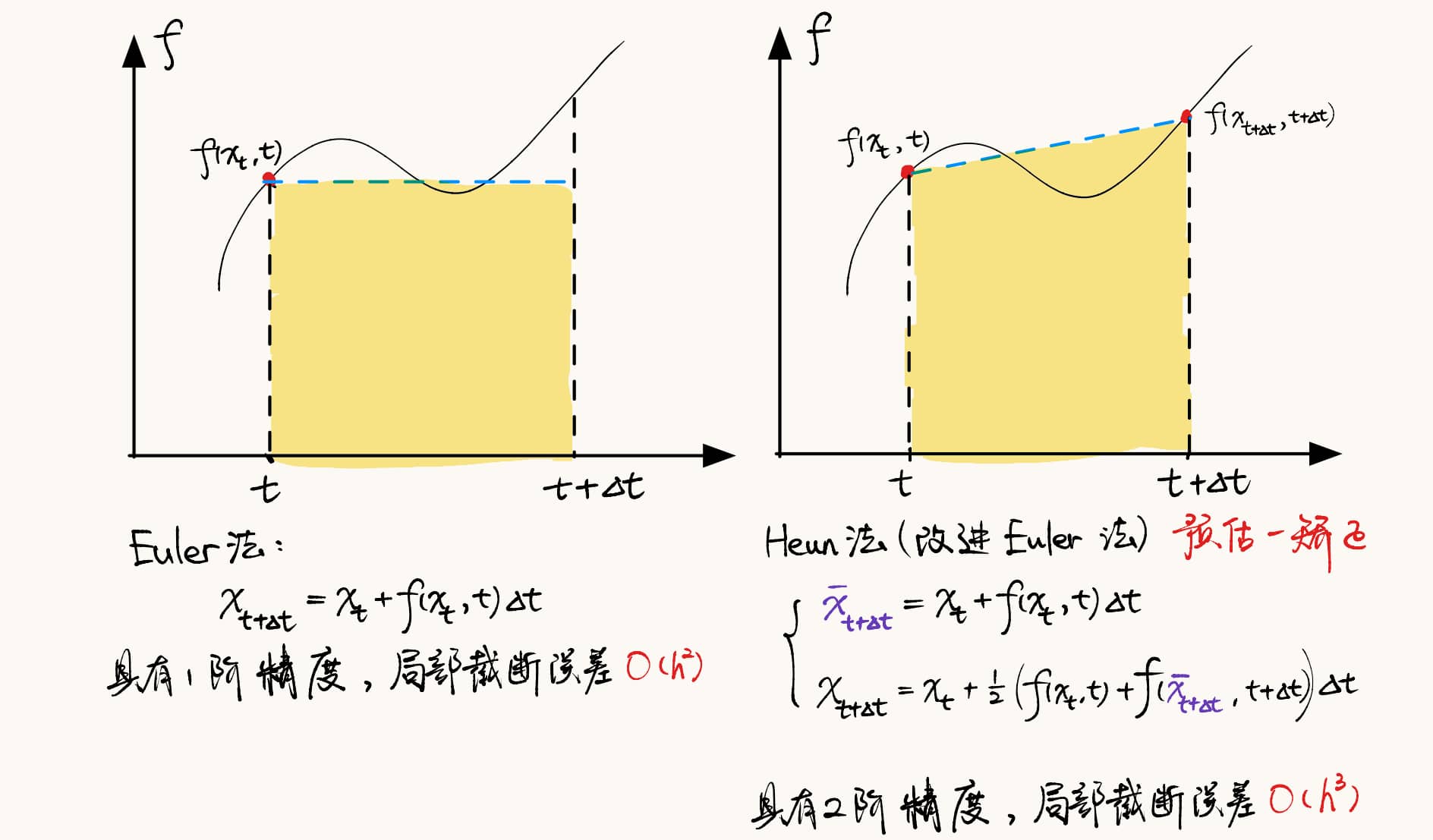
常用的欧拉法是一阶ODE求解器,其局部误差关于步长 h h h O ( h 2 ) O(h^2) O ( h 2 )
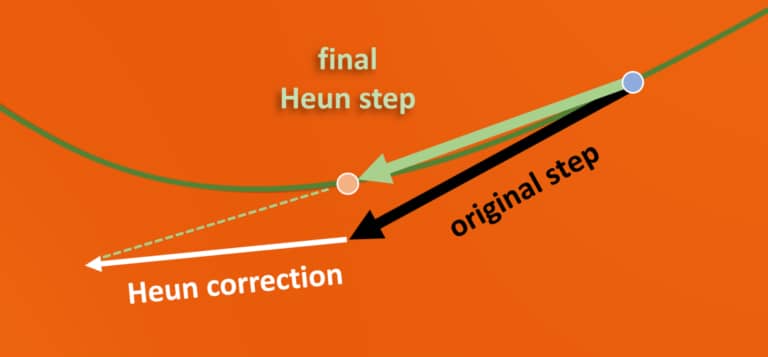
使用二阶Heun步的确定性采样算法
Euler法和Heun法
每一步都需要对 D θ D_\theta D θ
如算法1所示,该方法为 x i + 1 x_{i+1} x i + 1 t i t_i t i t i + 1 t_{i+1} t i + 1 d x d t \frac{dx}{dt} d t d x O ( h 3 ) O(h^3) O ( h 3 ) D θ D_\theta D θ σ = 0 \sigma=0 σ = 0
关于二阶求解器的通用类别,我们将在附录D.2中展开讨论。
时间步 { t i } \{t_i\} { t i } σ \sigma σ
EDM 采用如下参数化方案:
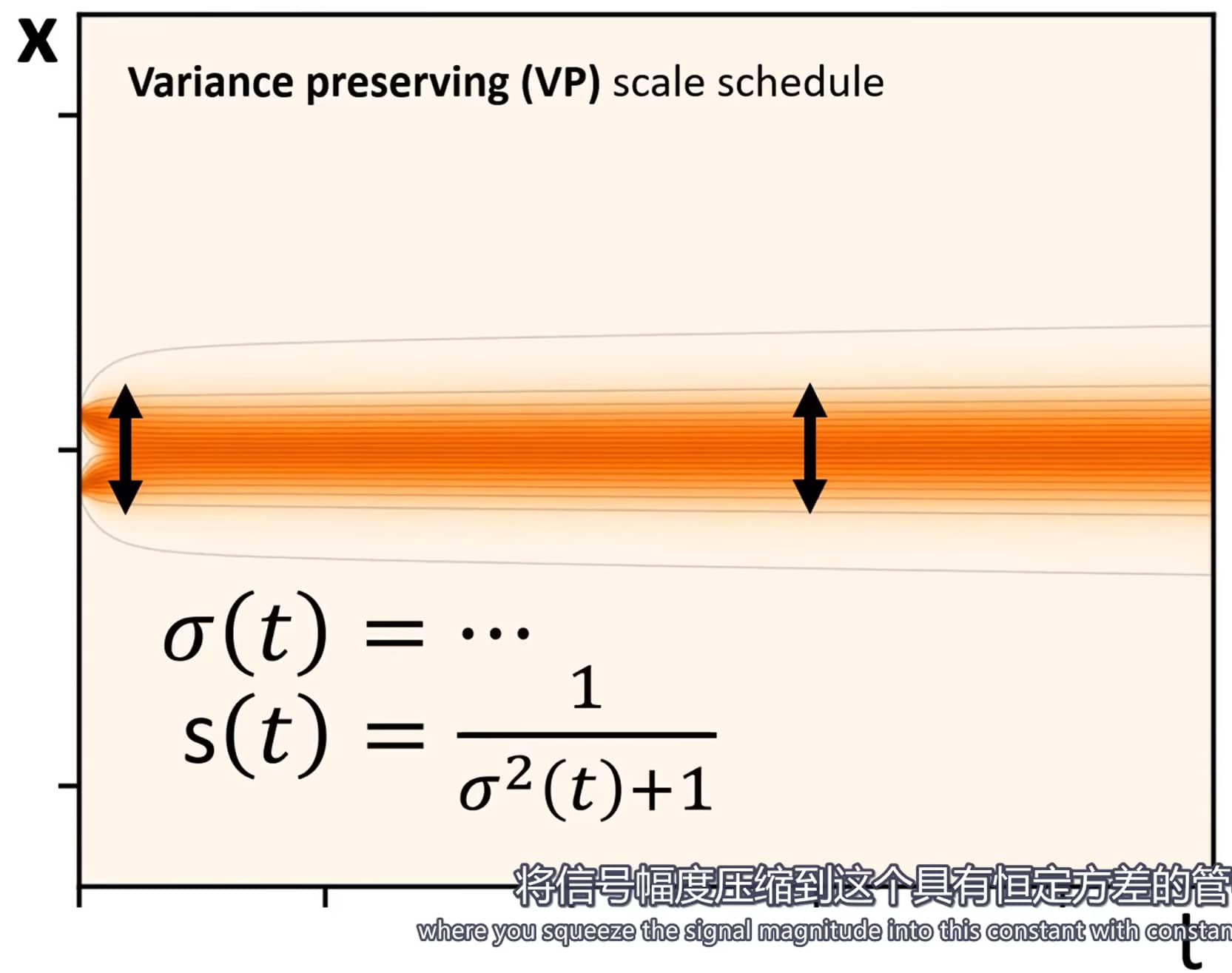
缩放因子 s ( t ) = 1 s(t) = 1 s ( t ) = 1
噪声水平序列 { σ i } \{\sigma_i\} { σ i }
σ i < N = ( σ m a x 1 ρ + i N − 1 ( σ m i n 1 ρ − σ m a x 1 ρ ) ) ρ , σ N = 0 (5) \sigma_{i<N} = \left( \sigma_{max}^{\frac{1}{\rho}} + \frac{i}{N-1} \left( \sigma_{min}^{\frac{1}{\rho}} - \sigma_{max}^{\frac{1}{\rho}} \right) \right)^\rho, \quad \sigma_N = 0 \tag{5}
σ i < N = ( σ ma x ρ 1 + N − 1 i ( σ min ρ 1 − σ ma x ρ 1 ) ) ρ , σ N = 0 ( 5 )
其中,ρ \rho ρ σ m a x \sigma_{max} σ ma x σ m i n \sigma_{min} σ min ρ = 3 \rho=3 ρ = 3 ρ \rho ρ σ m i n \sigma_{min} σ min ρ \rho ρ
改进后确定性采样方法的效果
Heun方法与式(5)的实验结果以图2中的绿色曲线展示。我们观察到所有场景下均有一致性提升:Heun方法能以显著更低的NFE达到与欧拉法相同的FID。
整合分析
表1给出了在本文框架下重现三种早期方法的确定性变体所需的公式。选择这些方法,一方面是因为它们应用广泛,另一方面,选择这些方法,不仅因为它们能实现最先进(state-of-the-art, SOTA)的性能,还因为它们源自不同的理论基础。我们的部分公式与原文献看起来差异较大,这是因为我们移除了其中的间接表述和递归结构;具体细节参见附录C。这种重新构建框架的主要目的,是清晰呈现此前研究中常相互纠缠的所有独立组件。在我们的框架中,组件之间不存在隐式依赖——原则上,对单个公式的任何选择(在合理范围内)都能得到一个可正常运行的模型。换句话说,修改某一个组件并不需要为了维持某项性质(例如模型在极限情况下收敛到数据分布)而对其他部分进行修改。当然,在实际应用中,某些选择和组合的效果必然会优于其他选择和组合。
随机采样
纠偏过程
确定性采样具有诸多优势,例如可通过反转ODE将真实图像转化为对应的 latent 表示(潜变量表示)。然而,与“每一步向图像中注入新噪声”的随机采样相比,确定性采样往往会导致更差的输出质量[47,49]。既然ODE与随机微分方程(SDE)在理论上可恢复相同的分布,那么随机性的具体作用究竟是什么?
研究背景
Song等人[49]提出的SDE可推广为[20,58]:概率流ODE(式1)与时变朗之万扩散(Langevin diffusion)SDE[14]之和(详见附录B.5),具体形式如下:
d x ± = − σ ˙ ( t ) σ ( t ) ∇ x log p ( x ; σ ( t ) ) d t ⏟ 概率流ODE ± β ( t ) σ ( t ) 2 ∇ x log p ( x ; σ ( t ) ) d t ⏟ 确定性噪声衰减 + 2 β ( t ) σ ( t ) d ω t ⏟ 噪声注入 (6) \mathrm{d}\boldsymbol{x}_\pm =
\underbrace{
\textcolor{lime}{-\dot{\sigma}(t)\sigma(t)\nabla_{\boldsymbol{x}} \log p(\boldsymbol{x}; \sigma(t)) \,\mathrm{d}t}
}_{\text{概率流ODE}}
\pm \underbrace{
\textcolor{orange}{\beta(t)\sigma(t)^2\nabla_{\boldsymbol{x}} \log p(\boldsymbol{x}; \sigma(t)) \,\mathrm{d}t}}_{\substack{\text{确定性噪声衰减}}}
+
\underbrace{\textcolor{cyan}{\sqrt{2\beta(t)}\sigma(t) \,\mathrm{d}\omega_t}
}_{\substack{\text{噪声注入}}} \tag{6}
d x ± = 概率流 ODE − σ ˙ ( t ) σ ( t ) ∇ x l o g p ( x ; σ ( t )) d t ± 确定性噪声衰减 β ( t ) σ ( t ) 2 ∇ x l o g p ( x ; σ ( t )) d t + 噪声注入 2 β ( t ) σ ( t ) d ω t ( 6 )
其中,ω t \omega_t ω t d x + dx_+ d x + d x − dx_- d x −
朗之万项可进一步拆解为“基于得分的确定性去噪项”与“随机性噪声注入项”,这两项对噪声水平的净贡献相互抵消。由此,β ( t ) \beta(t) β ( t ) β ( t ) = σ ˙ ( t ) / σ ( t ) \beta(t) = \dot{\sigma}(t)/\sigma(t) β ( t ) = σ ˙ ( t ) / σ ( t )
这一视角揭示了随机性在实际应用中的作用:隐式朗之万扩散会在特定时刻将样本推向目标边际分布,主动修正早期采样步骤中产生的误差。但另一方面,用离散SDE求解器步骤近似朗之万项的过程本身也会引入误差。现有研究[3,24,47,49]表明,非零的 β ( t ) \beta(t) β ( t ) β ( t ) \beta(t) β ( t )
第一项
− σ ˙ ( t ) σ ( t ) ∇ x log p ( x ; σ ( t ) ) d t -\dot{\sigma}(t)\sigma(t)\nabla_{\boldsymbol{x}} \log p(\boldsymbol{x};\sigma(t))\mathrm{d}t − σ ˙ ( t ) σ ( t ) ∇ x log p ( x ; σ ( t )) d t
这个部分就是EDM框架下的通用PDE/ODE形式,只是在 s ( t ) = 1 s(t)=1 s ( t ) = 1
第二项
± β ( t ) σ 2 ( t ) ∇ x log p ( x ; σ ( t ) ) d t \pm \beta(t)\sigma^2(t)\nabla_{\boldsymbol{x}} \log p(\boldsymbol{x};\sigma(t))\mathrm{d}t ± β ( t ) σ 2 ( t ) ∇ x log p ( x ; σ ( t )) d t
这一部分是确定性噪声衰减项,代入Score与单纯去噪模型 D θ ( x ; σ ) D_\theta(\boldsymbol{x};\sigma) D θ ( x ; σ )
± β ( t ) σ 2 ( t ) ∇ x log p ( x ; σ ( t ) ) d t = ± β ( t ) σ 2 ( t ) D θ ( x ; σ ( t ) ) − x σ 2 ( t ) d t = ± β ( t ) ( D θ ( x ; σ ( t ) ) − x ) d t \begin{align*}
\pm \beta(t)\sigma^2(t)\nabla_{\boldsymbol{x}} \log p(\boldsymbol{x};\sigma(t))\mathrm{d}t &= \pm \beta(t)\sigma^2(t)\frac{D_\theta(\boldsymbol{x};\sigma(t)) - \boldsymbol{x}}{\sigma^2(t)}\mathrm{d}t \\
&= \pm \beta(t)\left( D_\theta(\boldsymbol{x};\sigma(t)) - \boldsymbol{x} \right)\mathrm{d}t
\end{align*}
± β ( t ) σ 2 ( t ) ∇ x log p ( x ; σ ( t )) d t = ± β ( t ) σ 2 ( t ) σ 2 ( t ) D θ ( x ; σ ( t )) − x d t = ± β ( t ) ( D θ ( x ; σ ( t )) − x ) d t
由于 D θ ( x ; σ ) D_\theta(\boldsymbol{x};\sigma) D θ ( x ; σ ) x = y + n \boldsymbol{x} = \boldsymbol{y} + \boldsymbol{n} x = y + n y \boldsymbol{y} y n \boldsymbol{n} n n ∼ N ( 0 , σ 2 ( t ) I ) \boldsymbol{n} \sim \mathcal{N}(0, \sigma^2(t)\mathbf{I}) n ∼ N ( 0 , σ 2 ( t ) I )
± β ( t ) ( D θ ( x ; σ ( t ) ) − x ) ≈ ± β ( t ) ( y − x ) d t = ∓ β ( t ) n d t \pm \beta(t)\left( D_\theta(\boldsymbol{x};\sigma(t)) - \boldsymbol{x} \right) \approx \pm \beta(t)(\boldsymbol{y} - \boldsymbol{x})\mathrm{d}t = \mp \beta(t)\boldsymbol{n}\mathrm{d}t
± β ( t ) ( D θ ( x ; σ ( t )) − x ) ≈ ± β ( t ) ( y − x ) d t = ∓ β ( t ) n d t
也即,第二部分的值实际上与噪声水平成正比,噪声水平越大对 x \boldsymbol{x} x
第三项
2 β ( t ) σ ( t ) d w t \sqrt{2\beta(t)}\sigma(t)\mathrm{d}w_t 2 β ( t ) σ ( t ) d w t
由于维纳过程 d w t \mathrm{d}w_t d w t
2 β ( t ) σ ( t ) d w t = 2 β ( t ) σ ( t ) ε d t = 2 β ( t ) n ′ d t \begin{align*}
\sqrt{2\beta(t)}\sigma(t)\mathrm{d}w_t &= \sqrt{2\beta(t)}\sigma(t)\boldsymbol{\varepsilon}\sqrt{\mathrm{d}t} \\
&= \sqrt{2\beta(t)}\boldsymbol{n}^\prime\sqrt{\mathrm{d}t}
\end{align*}
2 β ( t ) σ ( t ) d w t = 2 β ( t ) σ ( t ) ε d t = 2 β ( t ) n ′ d t
这里,噪声 n \boldsymbol{n} n n ′ \boldsymbol{n}^\prime n ′ N ( 0 , σ 2 ( t ) I ) \mathcal{N}(0, \sigma^2(t)\mathbf{I}) N ( 0 , σ 2 ( t ) I ) n \boldsymbol{n} n ε \boldsymbol{\varepsilon} ε
β ( t ) σ 2 ( t ) ∇ x log p ( x ; σ ( t ) ) d t + 2 β ( t ) σ ( t ) d w t = − β ( t ) n d t + 2 β ( t ) n ′ d t \beta(t)\sigma^2(t)\nabla_{\boldsymbol{x}} \log p(\boldsymbol{x};\sigma(t))\mathrm{d}t + \sqrt{2\beta(t)}\sigma(t)\mathrm{d}w_t
= -\beta(t)\boldsymbol{n}\mathrm{d}t + \sqrt{2\beta(t)}\boldsymbol{n}^\prime \sqrt{\mathrm{d}t}
β ( t ) σ 2 ( t ) ∇ x log p ( x ; σ ( t )) d t + 2 β ( t ) σ ( t ) d w t = − β ( t ) n d t + 2 β ( t ) n ′ d t
观察公式(15),在向前SDE当中,同时在进行着相同水平噪声的加噪和去噪过程,β ( t ) \beta(t) β ( t )
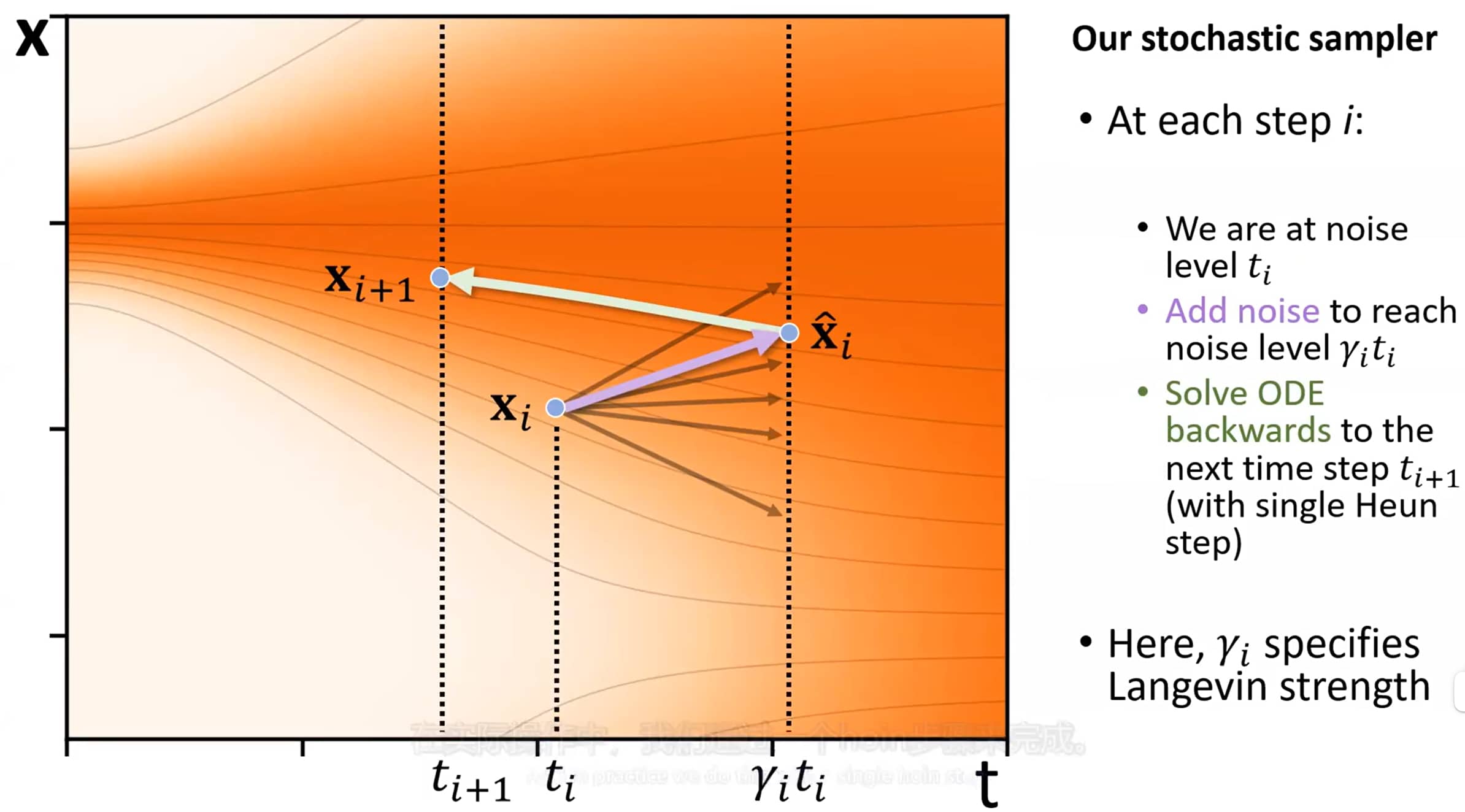
本文提出的随机采样器
我们提出的随机采样器,将二阶确定性ODE积分器与“添加-移除噪声”的显式朗之万式“扰动(churn)”相结合,伪代码详见算法2。在每一步 i i i t i t_i t i σ ( t i ) \sigma(t_i) σ ( t i ) x i x_i x i
EDM随机采样器具体算法
第一步,根据系数 γ i ≥ 0 \gamma_i \geq 0 γ i ≥ 0 t ^ i = t i + γ i t i \hat{t}_i = t_i + \gamma_i t_i t ^ i = t i + γ i t i x ^ i \hat{x}_i x ^ i t ^ i \hat{t}_i t ^ i t i + 1 t_{i+1} t i + 1 t i + 1 t_{i+1} t i + 1 x i + 1 x_{i+1} x i + 1
需强调的是,该方法并非通用的随机微分方程(SDE)求解器,而是针对该特定问题定制的采样流程。其正确性源于两个子步骤的交替执行——每个子步骤均能维持正确的分布(ODE步骤中存在的截断误差除外)。Song等人[49]提出的预测-校正采样器,与本文方法在概念结构上具有相似性。
Q:为什么要控制 γ i ≤ 2 − 1 \gamma_i \leq \sqrt{2}-1 γ i ≤ 2 − 1
A:这是为了加噪水平不至于太大,导致远离正确采样路径。
比如,令 ε i ∼ N ( 0 , σ 2 ( t i ) I ) \varepsilon_i \sim \mathcal{N}(0, \sigma^2(t_i)\mathbf{I}) ε i ∼ N ( 0 , σ 2 ( t i ) I ) γ i = 2 − 1 \gamma_i = \sqrt{2} - 1 γ i = 2 − 1
t i ^ = t i + γ i t i = t i + ( 2 − 1 ) t i = 2 t i \hat{t_i} = t_i + \gamma_i t_i = t_i + (\sqrt{2} - 1) t_i = \sqrt{2} t_i
t i ^ = t i + γ i t i = t i + ( 2 − 1 ) t i = 2 t i
于是
x i ^ = x i + t i ^ 2 − t i 2 = x i + t i ε i \hat{x_i} = x_i + \sqrt{\hat{t_i}^2 - t_i^2} = x_i + t_i \varepsilon_i
x i ^ = x i + t i ^ 2 − t i 2 = x i + t i ε i
其中,x i ∼ N ( x , t i 2 I ) x_i \sim \mathcal{N}(x,t_i^2 \ \mathbf{I}) x i ∼ N ( x , t i 2 I ) x x x t i ε i ∼ N ( 0 , t i 2 I ) t_i \varepsilon_i \sim \mathcal{N}(0, t_i^2 \ \mathbf{I}) t i ε i ∼ N ( 0 , t i 2 I )
本文方法与欧拉-丸山法的核心差异分析
我们首先注意到:欧拉-丸山法在对式(6)进行离散化时,存在一个细微偏差。可将欧拉-丸山法理解为“先添加噪声,再执行ODE步”,但它并非从噪声注入后的中间状态开始执行ODE步,而是假设在迭代步骤初始时,x x x σ \sigma σ
在我们的方法中,算法2第7行用于评估 D θ D_\theta D θ x i x_i x i t i t_i t i x ^ i \hat{x}_i x ^ i t ^ i \hat{t}_i t ^ i Δ t \Delta t Δ t
实际应用考量
增加随机性虽能有效校正早期采样步骤产生的误差,但也存在自身缺陷。我们观察到(详见附录E.1):在所有数据集和去噪器网络中,过度执行类似朗之万过程的“噪声添加-移除”操作,会导致生成图像的细节逐渐丢失;此外,在噪声水平极低和极高的情况下,图像还会出现颜色过饱和的偏移问题。我们推测,实际应用中的去噪器会使式(3)中的向量场产生轻微的非保守性,这一现象违背了朗之万扩散的前提假设,进而导致上述不利影响。值得注意的是,我们使用解析去噪器(如图1b中的去噪器)进行的实验,并未出现此类质量退化问题。
若图像质量退化由 D θ ( x ; σ ) D_\theta(x;\sigma) D θ ( x ; σ ) t i ∈ [ S t m i n , S t m a x ] t_i \in [S_{tmin}, S_{tmax}] t i ∈ [ S t min , S t ma x ] γ i = S c h u r n / N \gamma_i = S_{churn}/N γ i = S c h u r n / N S c h u r n S_{churn} S c h u r n γ i \gamma_i γ i
最后,我们发现:将 S n o i s e S_{noise} S n o i se D θ ( x ; σ ) D_\theta(x;\sigma) D θ ( x ; σ ) L 2 L_2 L 2
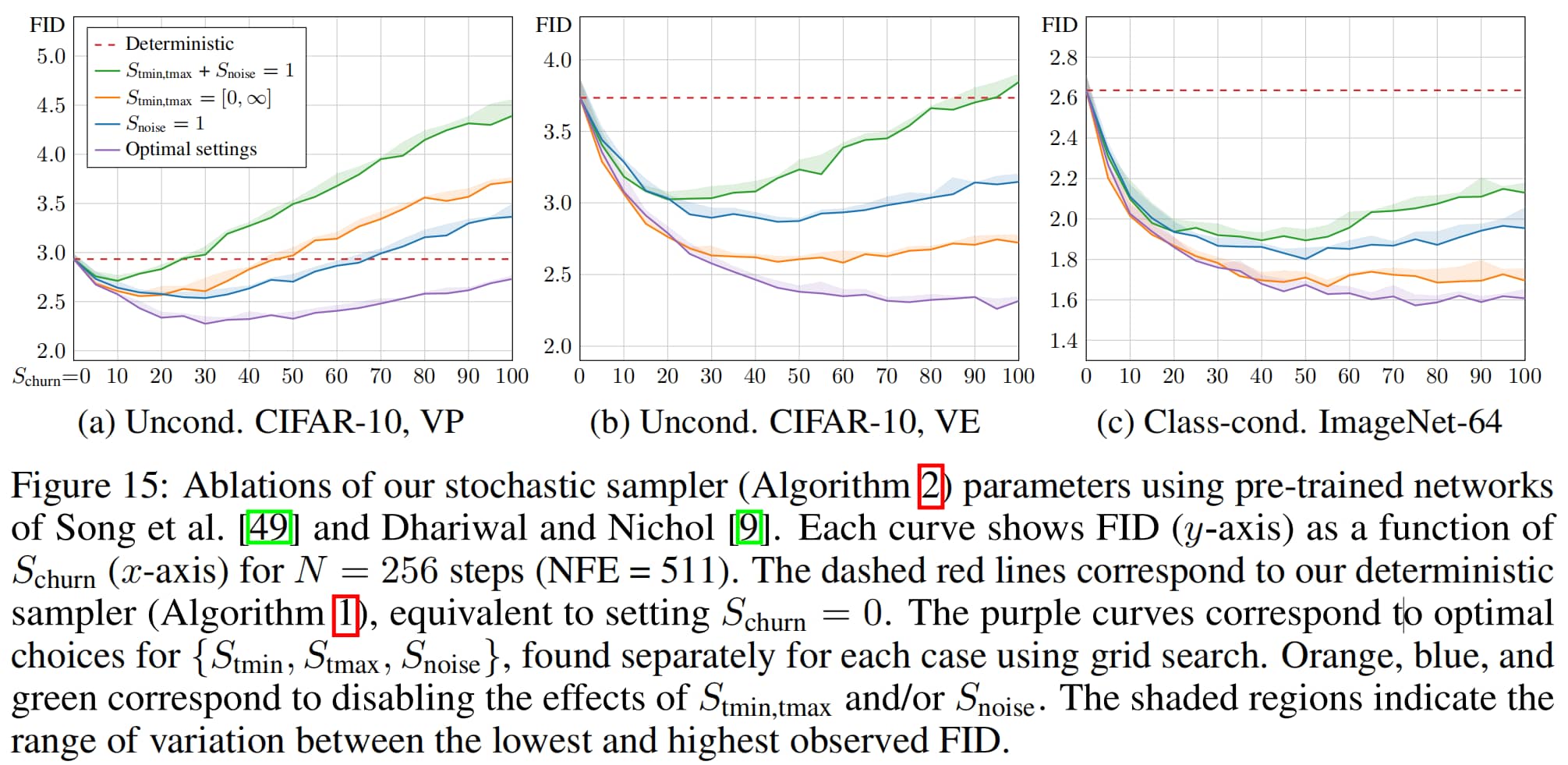
随机采样超参示意图
EDM随机采样参数设置
EDM采样总结
上图中,红色线代表确定性采样的结果,橙色线代表不采用 S tmin S_{\text{tmin}} S tmin S tmax S_{\text{tmax}} S tmax S tmin S_{\text{tmin}} S tmin S tmax S_{\text{tmax}} S tmax S noise S_{\text{noise}} S noise S noise S_{\text{noise}} S noise
确定性采样可以在更短的时间达到更低的FID,表明可以加速采样
随机性采样在更多步数以后可以达到更低的FID,效果比确定性采样要好
随机性采样以超参数设置与更多迭代步数为代价,换来了更好的采样性能
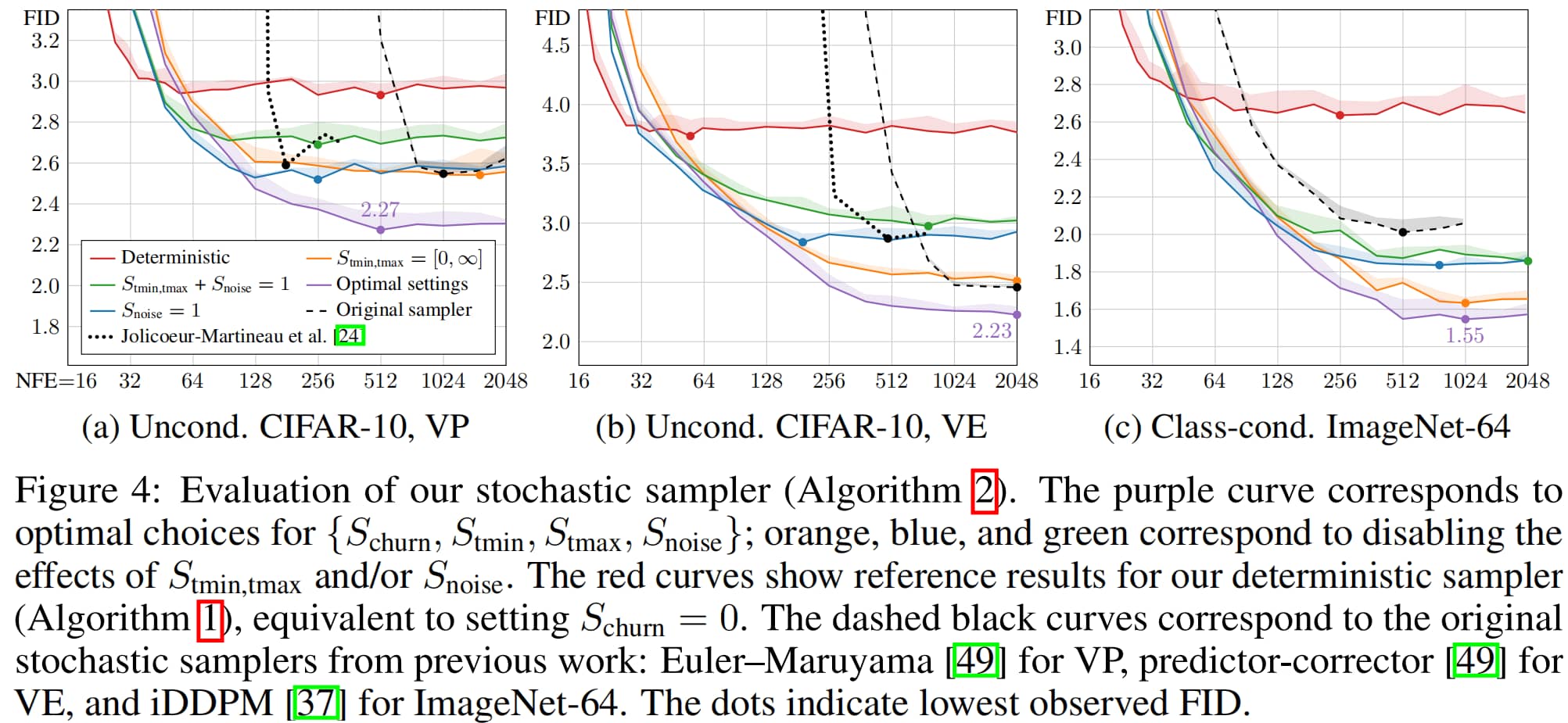
评估结果
图4显示,本文提出的随机采样器显著优于以往的采样器[24,37,49],尤其是在步数较少的情况下。Jolicoeur-Martineau等人[24]采用了标准的高阶自适应SDE求解器[41],该求解器的性能可作为此类自适应求解器的通用基准。本文的采样器则针对具体应用场景进行了定制(例如,将噪声注入与ODE步序贯执行),且并非自适应求解器。目前尚未有定论的是:在扩散模型采样中,自适应求解器是否能比参数调优后的固定调度方案带来净收益。
仅通过改进采样器,我们就将原本FID(弗雷歇初始距离)为2.07的ImageNet-64模型[9],优化至FID 1.55,该结果已非常接近当前最先进(SOTA)水平;此前,级联扩散模型[17]的FID为1.48(注:原文此处内容未完整呈现,暂译至此)。
此前,级联扩散模型(cascaded diffusion)[17]的FID为1.48,无分类器引导(classifier-free guidance)[18]的FID为1.55,StyleGAN-XL[45]的FID为1.52。虽然我们的结果展示了通过改进采样器可实现的潜在收益,但也凸显了随机性的主要缺陷:若要获得最佳结果,必须做出多项依赖特定模型的启发式选择(无论这些选择是隐式还是显式的)。事实上,我们不得不通过网格搜索,逐案例确定 { S c h u r n , S t m i n , S t m a x , S n o i s e } \{S_{churn}, S_{tmin}, S_{tmax}, S_{noise}\} { S c h u r n , S t min , S t ma x , S n o i se }
预处理与训练
回顾
DDPM/DDIM/VP
损失函数
L VP = E x t , ε ∼ N ( 0 , I ) λ ( t ) ∥ ε θ ( x t ; t ) − ε ∥ 2 2 \mathcal{L}_{\text{VP}} = \mathbb{E}_{\boldsymbol{x}_t, \boldsymbol{\varepsilon} \sim \mathcal{N}(0, \mathbf{I})} \lambda(t) \left\| \boldsymbol{\varepsilon}_\theta(\boldsymbol{x}_t; t) - \boldsymbol{\varepsilon} \right\|_2^2
L VP = E x t , ε ∼ N ( 0 , I ) λ ( t ) ∥ ε θ ( x t ; t ) − ε ∥ 2 2
其中,ε \boldsymbol{\varepsilon} ε ε ∼ N ( 0 , I ) \boldsymbol{\varepsilon} \sim \mathcal{N}(0, \mathbf{I}) ε ∼ N ( 0 , I ) ε θ \boldsymbol{\varepsilon}_\theta ε θ
带入EDM框架的去噪模型 D θ ( x ; σ ) D_\theta(\boldsymbol{x}; \sigma) D θ ( x ; σ ) x t \boldsymbol{x}_t x t x 0 \boldsymbol{x}_0 x 0
DDPM的一步加噪公式:
x t = α ˉ t x 0 + 1 − α ˉ t ε \boldsymbol{x}_t = \sqrt{\bar{\alpha}_t} \boldsymbol{x}_0 + \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\varepsilon}
x t = α ˉ t x 0 + 1 − α ˉ t ε
可变形为,
x 0 = x t − 1 − α ˉ t ε α ˉ t \boldsymbol{x}_0 = \frac{\boldsymbol{x}_t - \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\varepsilon}}{\sqrt{\bar{\alpha}_t}}
x 0 = α ˉ t x t − 1 − α ˉ t ε
套用DDPM加噪公式,去噪器 D θ D_\theta D θ
D θ ( x t ; σ ( t ) ) ≈ x 0 ≈ x t − 1 − α ˉ t ε α ˉ t ≈ 1 α ˉ t x t − 1 − α ˉ t α ˉ t ε θ ( x t ; t ) D_\theta(\boldsymbol{x}_t; \sigma(t)) \approx \boldsymbol{x}_0 \approx \frac{\boldsymbol{x}_t - \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\varepsilon}}{\sqrt{\bar{\alpha}_t}} \approx \frac{1}{\sqrt{\bar{\alpha}_t}} \boldsymbol{x}_t - \frac{\sqrt{1 - \bar{\alpha}_t}}{\sqrt{\bar{\alpha}_t}} \boldsymbol{\varepsilon}_\theta(\boldsymbol{x}_t; t)
D θ ( x t ; σ ( t )) ≈ x 0 ≈ α ˉ t x t − 1 − α ˉ t ε ≈ α ˉ t 1 x t − α ˉ t 1 − α ˉ t ε θ ( x t ; t )
SMLD/VE
损失函数为:
L SM = E x , σ ∼ N ( 0 , I ) λ ( σ ) ∥ s θ ( x ; σ ) − ∇ x log p ( x ; σ ) ∥ 2 2 \mathcal{L}_{\text{SM}} = \mathbb{E}_{\boldsymbol{x}, \sigma \sim \mathcal{N}(0, \mathbf{I})} \lambda(\sigma) \left\| s_\theta(\boldsymbol{x}; \sigma) - \nabla_{\boldsymbol{x}} \log p(\boldsymbol{x}; \sigma) \right\|_2^2
L SM = E x , σ ∼ N ( 0 , I ) λ ( σ ) ∥ s θ ( x ; σ ) − ∇ x log p ( x ; σ ) ∥ 2 2
同样,∇ x log p ( x ; σ ) \nabla_{\boldsymbol{x}} \log p(\boldsymbol{x}; \sigma) ∇ x log p ( x ; σ ) s θ s_\theta s θ
按上文中 D θ D_\theta D θ
∇ x log p ( x ; σ ) ≈ D θ ( x ; σ ) − x σ 2 \nabla_{\boldsymbol{x}} \log p(\boldsymbol{x}; \sigma) \approx \frac{D_\theta(\boldsymbol{x}; \sigma) - \boldsymbol{x}}{\sigma^2}
∇ x log p ( x ; σ ) ≈ σ 2 D θ ( x ; σ ) − x
整理成 D θ D_\theta D θ
D θ ( x ; σ ) ≈ x + σ 2 ∇ x log p ( x ; σ ) ≈ x + σ 2 s θ ( x ; σ ) D_\theta(\boldsymbol{x}; \sigma) \approx \boldsymbol{x} + \sigma^2 \nabla_{\boldsymbol{x}} \log p(\boldsymbol{x}; \sigma) \approx \boldsymbol{x} + \sigma^2 s_\theta(\boldsymbol{x}; \sigma)
D θ ( x ; σ ) ≈ x + σ 2 ∇ x log p ( x ; σ ) ≈ x + σ 2 s θ ( x ; σ )
Flow Matching
损失函数为:
L FM = E x t , t , ε ∼ N ( 0 , I ) λ ( t ) ∥ v θ ( x t ; t ) − ( x 0 − ε ) ∥ 2 2 \mathcal{L}_{\text{FM}} = \mathbb{E}_{\boldsymbol{x}_t, t, \boldsymbol{\varepsilon} \sim \mathcal{N}(0, \mathbf{I})} \lambda(t) \left\| v_\theta(\boldsymbol{x}_t; t) - (\boldsymbol{x}_0 - \boldsymbol{\varepsilon}) \right\|_2^2
L FM = E x t , t , ε ∼ N ( 0 , I ) λ ( t ) ∥ v θ ( x t ; t ) − ( x 0 − ε ) ∥ 2 2
其中,x 0 \boldsymbol{x}_0 x 0 ε ∼ N ( 0 , I ) \boldsymbol{\varepsilon} \sim \mathcal{N}(0, \mathbf{I}) ε ∼ N ( 0 , I )
因为 D θ ( x ; σ ) ≈ x 0 D_\theta(\boldsymbol{x}; \sigma) \approx \boldsymbol{x}_0 D θ ( x ; σ ) ≈ x 0
v θ ( x t ; t ) ≈ D θ ( x t ; σ ( t ) ) − ε v_\theta(\boldsymbol{x}_t; t) \approx D_\theta(\boldsymbol{x}_t; \sigma(t)) - \boldsymbol{\varepsilon}
v θ ( x t ; t ) ≈ D θ ( x t ; σ ( t )) − ε
Flow Matching 加噪公式:
x t = ( 1 − t ) x 0 + t ε \boldsymbol{x}_t = (1 - t)\boldsymbol{x}_0 + t\boldsymbol{\varepsilon}
x t = ( 1 − t ) x 0 + t ε
由 Flow Matching 加噪公式,可得:
ε = x t − ( 1 − t ) x 0 t ≈ x t − ( 1 − t ) D θ ( x t ; σ ( t ) ) t \boldsymbol{\varepsilon} = \frac{\boldsymbol{x}_t - (1 - t)\boldsymbol{x}_0}{t} \approx \frac{\boldsymbol{x}_t - (1 - t)D_\theta(\boldsymbol{x}_t; \sigma(t))}{t}
ε = t x t − ( 1 − t ) x 0 ≈ t x t − ( 1 − t ) D θ ( x t ; σ ( t ))
代回,
v θ ( x t ; t ) ≈ D θ ( x t ; σ ( t ) ) − ε = D θ ( x t ; σ ( t ) ) − x t − ( 1 − t ) D θ ( x t ; σ ( t ) ) t = 1 t D θ ( x t ; σ ( t ) ) − 1 t x t \begin{align*}
v_\theta(\boldsymbol{x}_t; t) &\approx D_\theta(\boldsymbol{x}_t; \sigma(t)) - \boldsymbol{\varepsilon} \\
&= D_\theta(\boldsymbol{x}_t; \sigma(t)) - \frac{\boldsymbol{x}_t - (1 - t)D_\theta(\boldsymbol{x}_t; \sigma(t))}{t} \\
&= \frac{1}{t} D_\theta(\boldsymbol{x}_t; \sigma(t)) - \frac{1}{t} \boldsymbol{x}_t
\end{align*}
v θ ( x t ; t ) ≈ D θ ( x t ; σ ( t )) − ε = D θ ( x t ; σ ( t )) − t x t − ( 1 − t ) D θ ( x t ; σ ( t )) = t 1 D θ ( x t ; σ ( t )) − t 1 x t
把 D θ D_\theta D θ
D θ ( x t ; σ ( t ) ) ≈ x t + t v θ ( x t ; t ) D_\theta(\boldsymbol{x}_t; \sigma(t)) \approx \boldsymbol{x}_t + t\,v_\theta(\boldsymbol{x}_t; t)
D θ ( x t ; σ ( t )) ≈ x t + t v θ ( x t ; t )
大一统训练模型
Q:为什么要加入多个前处理和后处理操作?
A:为了使 D θ D_\theta D θ L \mathcal{L} L
两种选择:
在目标附近采用更短的步长;
扭曲噪声调度,以在目标附近花费更多时间。
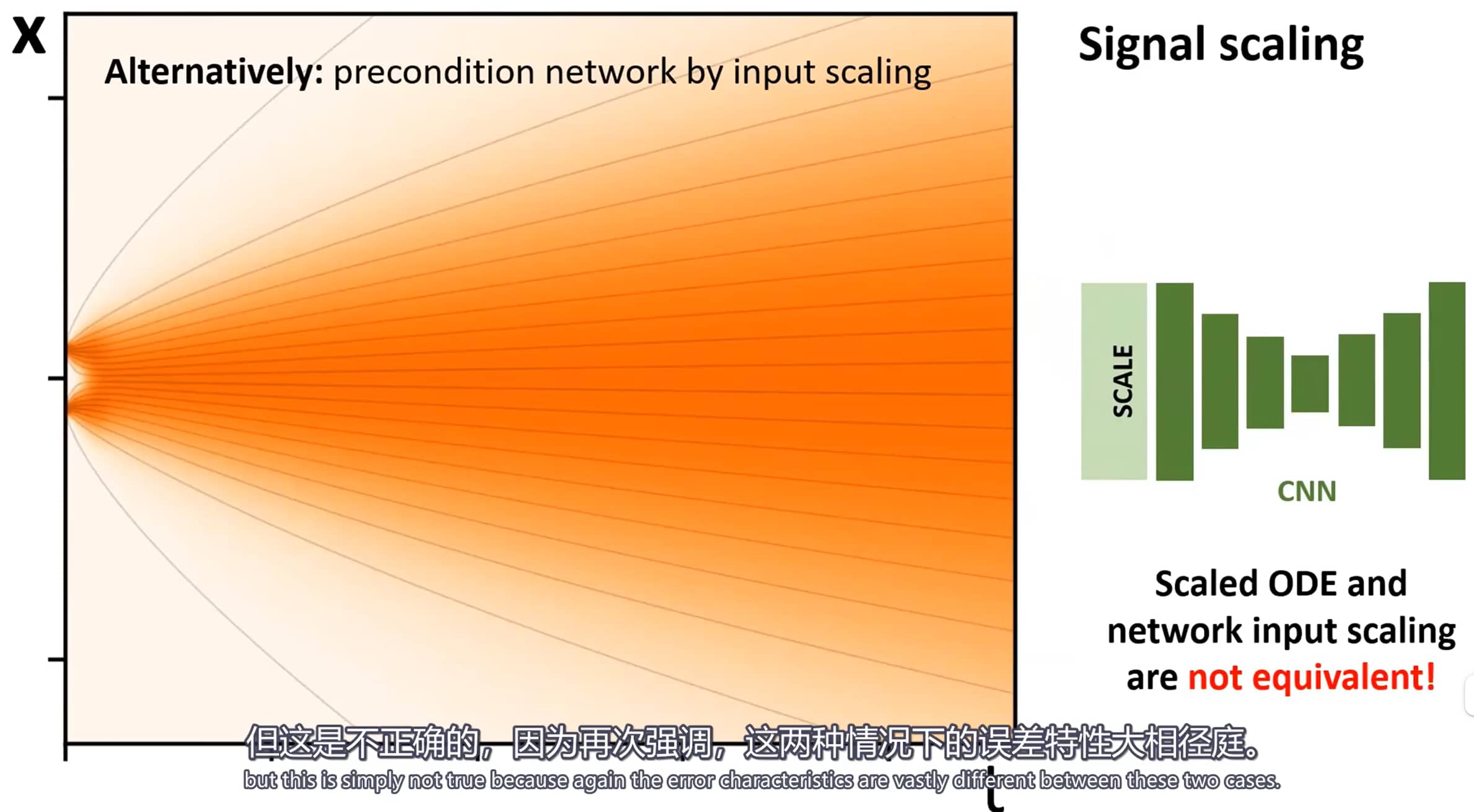
信号尺度差异过大会导致神经网络难以训练
===========================
在有监督训练神经网络的领域,存在多种已知的良好实践。例如,建议将输入和输出信号的幅度固定为特定值(如单位方差),并避免单样本梯度幅度出现大幅波动。
直接训练神经网络对去噪器 D D D x = y + n \boldsymbol{x} = \boldsymbol{y} + \boldsymbol{n} x = y + n y \boldsymbol{y} y n \boldsymbol{n} n n ∼ N ( 0 , σ 2 I ) \boldsymbol{n} \sim \mathcal{N}(0, \sigma^2 \boldsymbol{I}) n ∼ N ( 0 , σ 2 I ) σ \sigma σ
因此,常规做法是不将 D θ D_\theta D θ F θ F_\theta F θ F θ F_\theta F θ D θ D_\theta D θ
对比上面三式,可以总结出如下通式,
借鉴此前“自适应混合信号与噪声”的参数化思路,我们提出为神经网络添加与 σ \sigma σ y \boldsymbol{y} y n \boldsymbol{n} n D θ D_\theta D θ
D θ ( x ; σ ) = c s k i p ( σ ) x + c o u t ( σ ) F θ ( c i n ( σ ) x ; c n o i s e ( σ ) ) (6) D_\theta(x;\sigma) = c_{skip}(\sigma)x + c_{out}(\sigma)F_\theta\left(c_{in}(\sigma)x; c_{noise}(\sigma)\right) \tag{6}
D θ ( x ; σ ) = c s ki p ( σ ) x + c o u t ( σ ) F θ ( c in ( σ ) x ; c n o i se ( σ ) ) ( 6 )
其中,
F θ F_\theta F θ c s k i p ( σ ) c_{skip}(\sigma) c s ki p ( σ ) c i n ( σ ) c_{in}(\sigma) c in ( σ ) c o u t ( σ ) c_{out}(\sigma) c o u t ( σ ) c n o i s e ( σ ) c_{noise}(\sigma) c n o i se ( σ ) σ \sigma σ F θ F_\theta F θ
注1:c i n c_{in} c in
例如,DDPM/DDIM 中 s ( t ) = α ˉ t s(t) = \sqrt{\bar{\alpha}_t} s ( t ) = α ˉ t c i n ( σ ) = α ˉ ( σ − 1 ( σ ) ) c_{in}(\sigma) = \sqrt{\bar{\alpha}(\sigma^{-1}(\sigma))} c in ( σ ) = α ˉ ( σ − 1 ( σ )) s ( t ) = 1 s(t) = 1 s ( t ) = 1 c i n ( σ ) = 1 c_{in}(\sigma) = 1 c in ( σ ) = 1 s ( t ) = 1 − t s(t) = 1 - t s ( t ) = 1 − t c i n ( σ ) = 1 − t = 1 − σ − 1 ( σ ) c_{in}(\sigma) = 1 - t = 1 - \sigma^{-1}(\sigma) c in ( σ ) = 1 − t = 1 − σ − 1 ( σ )
注2:c n o i s e ( σ ) c_{noise}(\sigma) c n o i se ( σ ) σ \sigma σ x x x
例如,在 DDPM/DDIM 的 ε θ ( x t , t ) \varepsilon_\theta (x_t,t) ε θ ( x t , t ) c n o i s e c_{noise} c n o i se t t t c n o i s e = σ − 1 ( σ ( t ) ) = t c_{noise} = \sigma^{-1}(\sigma(t)) = t c n o i se = σ − 1 ( σ ( t )) = t c n o i s e c_{noise} c n o i se c n o i s e = log ( 1 2 σ ) c_{noise} = \log (\frac{1}{2} \sigma) c n o i se = log ( 2 1 σ )
c n o i s e = σ − 1 ( σ ( t ) ) = t c_{noise} = \sigma^{-1}(\sigma(t)) = t c n o i se = σ − 1 ( σ ( t )) = t
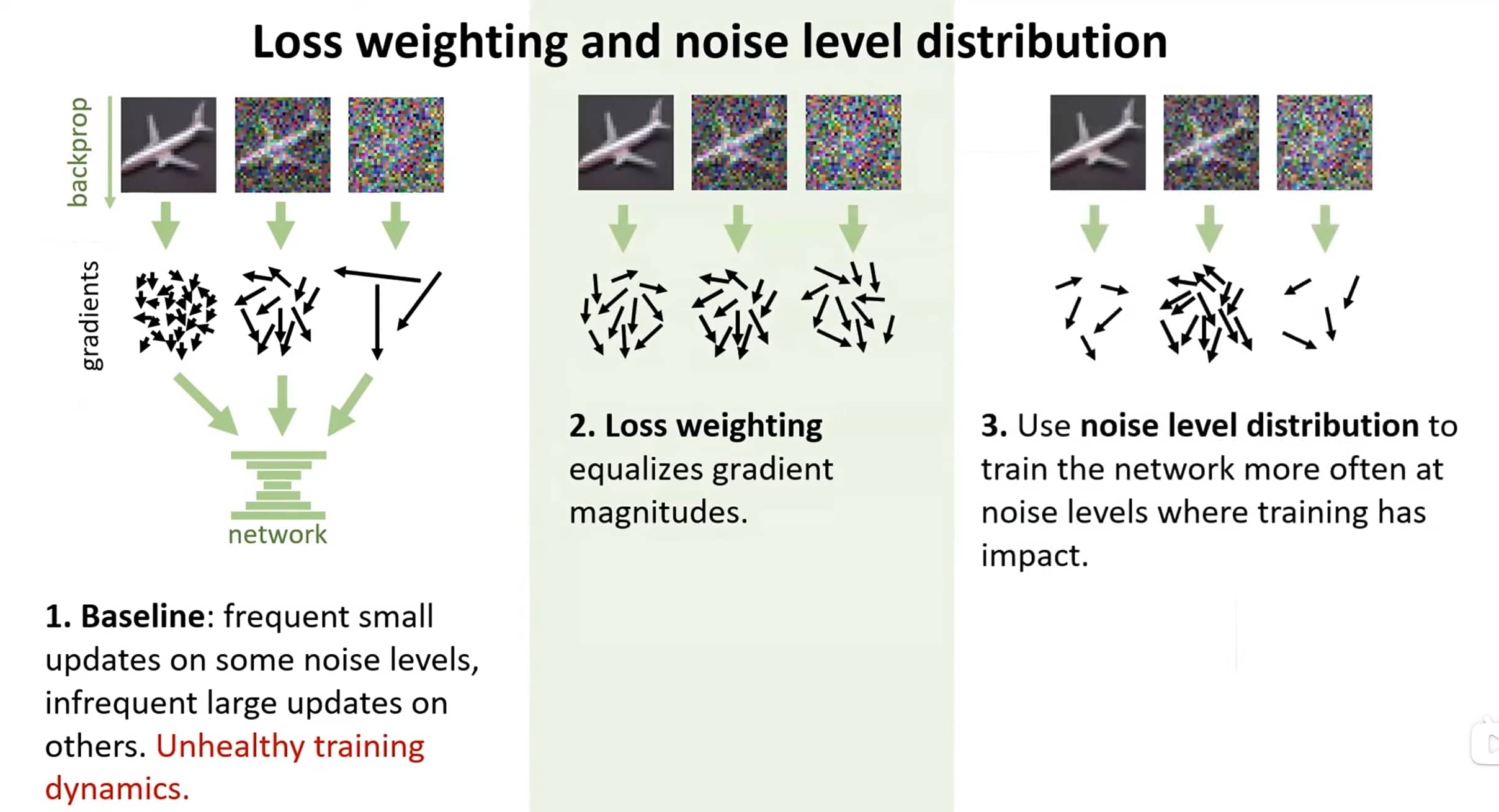
损失加权
对式(2)在所有噪声水平上取加权期望,可得到整体训练损失:E σ , y , n [ λ ( σ ) ∥ D ( y + n ; σ ) − y ∥ 2 2 ] \mathbb{E}_{\sigma,y,n}\left[\lambda(\sigma)\|D(y+n;\sigma) - y\|_2^2\right] E σ , y , n [ λ ( σ ) ∥ D ( y + n ; σ ) − y ∥ 2 2 ] σ ∼ p t r a i n \sigma \sim p_{train} σ ∼ p t r ain y ∼ p d a t a y \sim p_{data} y ∼ p d a t a n ∼ N ( 0 , σ 2 I ) n \sim \mathcal{N}(0,\sigma^2I) n ∼ N ( 0 , σ 2 I ) σ \sigma σ p t r a i n ( σ ) p_{train}(\sigma) p t r ain ( σ ) λ ( σ ) \lambda(\sigma) λ ( σ )
既然 D θ ( x ; σ ) D_\theta(\boldsymbol{x};\sigma) D θ ( x ; σ )
L diff = E σ ∼ p train , x , y ∼ p data [ λ ( σ ) ∥ D θ ( x ; σ ) − y ∥ 2 2 ] = E σ ∼ p train , y ∼ p data , n ∼ N ( 0 , σ 2 I ) [ λ ( σ ) ∥ D θ ( y + n ; σ ) − y ∥ 2 2 ] \begin{align*}
\mathcal{L}_{\text{diff}} &= \mathbb{E}_{\sigma \sim p_{\text{train}},\boldsymbol{x},\boldsymbol{y} \sim p_{\text{data}}} \left[ \lambda(\sigma) \| D_\theta(\boldsymbol{x}; \sigma) - \boldsymbol{y} \|_2^2 \right] \\
&= \mathbb{E}_{\sigma \sim p_{\text{train}},\boldsymbol{y} \sim p_{\text{data}}, \boldsymbol{n} \sim \mathcal{N}(0, \sigma^2 \mathbf{I})} \left[ \lambda(\sigma) \| D_\theta(\boldsymbol{y} + \boldsymbol{n}; \sigma) - \boldsymbol{y} \|_2^2 \right]
\end{align*}
L diff = E σ ∼ p train , x , y ∼ p data [ λ ( σ ) ∥ D θ ( x ; σ ) − y ∥ 2 2 ] = E σ ∼ p train , y ∼ p data , n ∼ N ( 0 , σ 2 I ) [ λ ( σ ) ∥ D θ ( y + n ; σ ) − y ∥ 2 2 ]
p train p_{\text{train}} p train σ \sigma σ
结合式 <a href="#eq:6">(6)</a>,我们可将该损失用网络 F θ F_\theta F θ
L diff = E σ , y , n [ λ ( σ ) ∥ c skip ( σ ) ( y + n ) + c out ( σ ) F θ ( c in ( σ ) ( y + n ) ; c noise ( σ ) ) − y ∥ 2 2 ] = E σ , y , n [ λ ( σ ) c o u t ( σ ) 2 ⏟ 有效权重 ∥ F θ ( c i n ( σ ) ⋅ ( y + n ) ; c n o i s e ( σ ) ) ⏟ 网络输出 − 1 c o u t ( σ ) ( y − c s k i p ( σ ) ⋅ ( y + n ) ) ⏟ 有效训练目标 ∥ 2 2 ] \begin{align*}
\mathcal{L}_\text{diff} &= \mathbb{E}_{\sigma,\boldsymbol{y},\boldsymbol{n}} \left[ \lambda(\sigma) \left\| c_{\text{skip}}(\sigma)(\boldsymbol{y}+\boldsymbol{n}) + c_{\text{out}}(\sigma) F_\theta\left( c_{\text{in}}(\sigma)(\boldsymbol{y}+\boldsymbol{n}); c_{\text{noise}}(\sigma) \right) - \boldsymbol{y} \right\|_2^2 \right] \\
&= \mathbb{E}_{\sigma,\boldsymbol{y},\boldsymbol{n}}\left[ \underbrace{\lambda(\sigma)c_{out}(\sigma)^2}_{\text{有效权重}} \left\| \underbrace{F_\theta\left(c_{in}(\sigma)\cdot(\boldsymbol{y}+\boldsymbol{n}); c_{noise}(\sigma)\right)}_{\text{网络输出}} - \underbrace{\frac{1}{c_{out}(\sigma)}\left(\boldsymbol{y} - c_{skip}(\sigma)\cdot(\boldsymbol{y}+\boldsymbol{n})\right)}_{\text{有效训练目标}} \right\|_2^2 \right] \tag{7}
\end{align*}
L diff = E σ , y , n [ λ ( σ ) ∥ c skip ( σ ) ( y + n ) + c out ( σ ) F θ ( c in ( σ ) ( y + n ) ; c noise ( σ ) ) − y ∥ 2 2 ] = E σ , y , n 有效权重 λ ( σ ) c o u t ( σ ) 2 网络输出 F θ ( c in ( σ ) ⋅ ( y + n ) ; c n o i se ( σ ) ) − 有效训练目标 c o u t ( σ ) 1 ( y − c s ki p ( σ ) ⋅ ( y + n ) ) 2 2 ( 7 )
超参数的选取
要使得训练稳定,不能使得噪声不同的时候,损失函数产生大幅度的变化,因此EDM考虑了以下四点来设计 c in ( σ ) c_{\text{in}}(\sigma) c in ( σ ) c out ( σ ) c_{\text{out}}(\sigma) c out ( σ ) c skip ( σ ) c_{\text{skip}}(\sigma) c skip ( σ ) λ ( σ ) \lambda(\sigma) λ ( σ )
此处没有提到 c n o i s e c_{noise} c n o i se
超参数选取主要遵循以下原则:
神经网络的输入保持单位方差,规范了 c in ( σ ) c_{\text{in}}(\sigma) c in ( σ )
训练目标保持单位方差,规范了 c out ( σ ) c_{\text{out}}(\sigma) c out ( σ ) c skip ( σ ) c_{\text{skip}}(\sigma) c skip ( σ )
等价对待所有的噪声水平损失函数,规范了 λ ( σ ) \lambda(\sigma) λ ( σ )
对 c in ( σ ) c_{\text{in}}(\sigma) c in ( σ )
D y , n [ c in ( σ ) ( y + n ) ] = 1 ⇒ c in ( σ ) = 1 σ 2 + σ data 2 \mathbb{D}_{\boldsymbol{y},\boldsymbol{n}} \left[ c_{\text{in}}(\sigma)(\boldsymbol{y} + \boldsymbol{n}) \right] = 1 \Rightarrow c_{\text{in}}(\sigma) = \frac{1}{\sigma^2 + \sigma_{\text{data}}^2}
D y , n [ c in ( σ ) ( y + n ) ] = 1 ⇒ c in ( σ ) = σ 2 + σ data 2 1
对 c out ( σ ) , c skip ( σ ) c_{\text{out}}(\sigma), c_{\text{skip}}(\sigma) c out ( σ ) , c skip ( σ )
D y , n [ 1 c out ( σ ) ( y − c skip ( σ ) ( y + n ) ) ] = 1 ⇒ c out 2 ( σ ) = ( 1 − c skip ( σ ) ) 2 σ data 2 + c skip 2 ( σ ) σ 2 \mathbb{D}_{\boldsymbol{y},\boldsymbol{n}} \left[ \frac{1}{c_{\text{out}}(\sigma)} \left( \boldsymbol{y} - c_{\text{skip}}(\sigma)(\boldsymbol{y} + \boldsymbol{n}) \right) \right] = 1 \Rightarrow
c_{\text{out}}^2(\sigma) = \left( 1 - c_{\text{skip}}(\sigma) \right)^2 \sigma_{\text{data}}^2 + c_{\text{skip}}^2(\sigma) \sigma^2
D y , n [ c out ( σ ) 1 ( y − c skip ( σ ) ( y + n ) ) ] = 1 ⇒ c out 2 ( σ ) = ( 1 − c skip ( σ ) ) 2 σ data 2 + c skip 2 ( σ ) σ 2
可以发现上式的 c out ( σ ) c_{\text{out}}(\sigma) c out ( σ ) c skip ( σ ) c_{\text{skip}}(\sigma) c skip ( σ ) c out ( σ ) c_{\text{out}}(\sigma) c out ( σ ) F θ F_\theta F θ c out ( σ ) c_{\text{out}}(\sigma) c out ( σ ) F θ F_\theta F θ c skip ( σ ) c_{\text{skip}}(\sigma) c skip ( σ )
c skip ( σ ) = arg min c skip ( σ ) c out 2 ( σ ) c_{\text{skip}}(\sigma) = \arg\min_{c_{\text{skip}}(\sigma)} c_{\text{out}}^2(\sigma)
c skip ( σ ) = arg c skip ( σ ) min c out 2 ( σ )
这是一个凸优化问题,令其导数为0,
d c out 2 ( σ ) d σ = 0 \frac{\mathrm{d}c_{\text{out}}^2(\sigma)}{\mathrm{d}\sigma} = 0
d σ d c out 2 ( σ ) = 0
经过运算可得,
c skip ( σ ) = σ data 2 σ 2 + σ data 2 c_{\text{skip}}(\sigma) = \frac{\sigma_{\text{data}}^2}{\sigma^2 + \sigma_{\text{data}}^2}
c skip ( σ ) = σ 2 + σ data 2 σ data 2
代回,得到,
c out ( σ ) = σ ⋅ σ data σ 2 + σ data 2 c_{\text{out}}(\sigma) = \frac{\sigma \cdot \sigma_{\text{data}}}{\sqrt{\sigma^2 + \sigma_{\text{data}}^2}}
c out ( σ ) = σ 2 + σ data 2 σ ⋅ σ data
对 λ ( σ ) \lambda(\sigma) λ ( σ )
令 w ( σ ) = 1 w(\sigma) = 1 w ( σ ) = 1
λ ( σ ) C out 2 ( σ ) = 1 ⇒ λ ( σ ) = σ 2 + σ data 2 ( σ ⋅ σ data ) 2 \lambda(\sigma) C_{\text{out}}^2(\sigma) = 1 \Rightarrow \lambda(\sigma) = \frac{\sigma^2 + \sigma_{\text{data}}^2}{\left( \sigma \cdot \sigma_{\text{data}} \right)^2}
λ ( σ ) C out 2 ( σ ) = 1 ⇒ λ ( σ ) = ( σ ⋅ σ data ) 2 σ 2 + σ data 2
λ ( σ ) = 1 c out 2 ( σ ) \lambda(\sigma) = \frac{1}{c_{\text{out}}^2(\sigma)}
λ ( σ ) = c out 2 ( σ ) 1
该形式清晰呈现了 F θ F_\theta F θ
我们在表1中列出的(预处理函数)选择方案,是通过以下要求推导得到的:网络输入和训练目标需具有单位方差(由 c i n c_{in} c in c o u t c_{out} c o u t F θ F_\theta F θ c s k i p c_{skip} c s ki p c n o i s e c_{noise} c n o i se
表2展示了一系列训练配置的弗雷歇初始距离(FID),所有结果均使用第3节提出的确定性采样器评估。我们以Song等人[49]提出的基准训练配置为起点,该配置在方差保持(VP)和方差爆炸(VE)两种场景下差异显著,因此我们分别提供了两种场景的结果(对应配置A)。为了获得更具意义的对比基准,我们重新调整了基础超参数(对应配置B),并通过移除最低分辨率层、同时将最高分辨率层的容量翻倍,提升了模型的表达能力(对应配置C);更多细节详见附录F.3。随后,我们将 { c i n 、 c o u t 、 c n o i s e 、 c s k i p } \{c_{in}、c_{out}、c_{noise}、c_{skip}\} { c in 、 c o u t 、 c n o i se 、 c s ki p }
=========================
式(8)表明,按照式(7)的预处理方式训练F θ F_\theta F θ λ ( σ ) c o u t ( σ ) 2 \lambda(\sigma)c_{out}(\sigma)^2 λ ( σ ) c o u t ( σ ) 2 λ ( σ ) = 1 / c o u t ( σ ) 2 \lambda(\sigma) = 1/c_{out}(\sigma)^2 λ ( σ ) = 1/ c o u t ( σ ) 2 σ \sigma σ
最后,我们需要确定训练时的噪声采样分布 p t r a i n ( σ ) p_{train}(\sigma) p t r ain ( σ ) σ \sigma σ p t r a i n ( σ ) p_{train}(\sigma) p t r ain ( σ )
表2显示,当我们提出的 p t r a i n p_{train} p t r ain λ \lambda λ λ \lambda λ
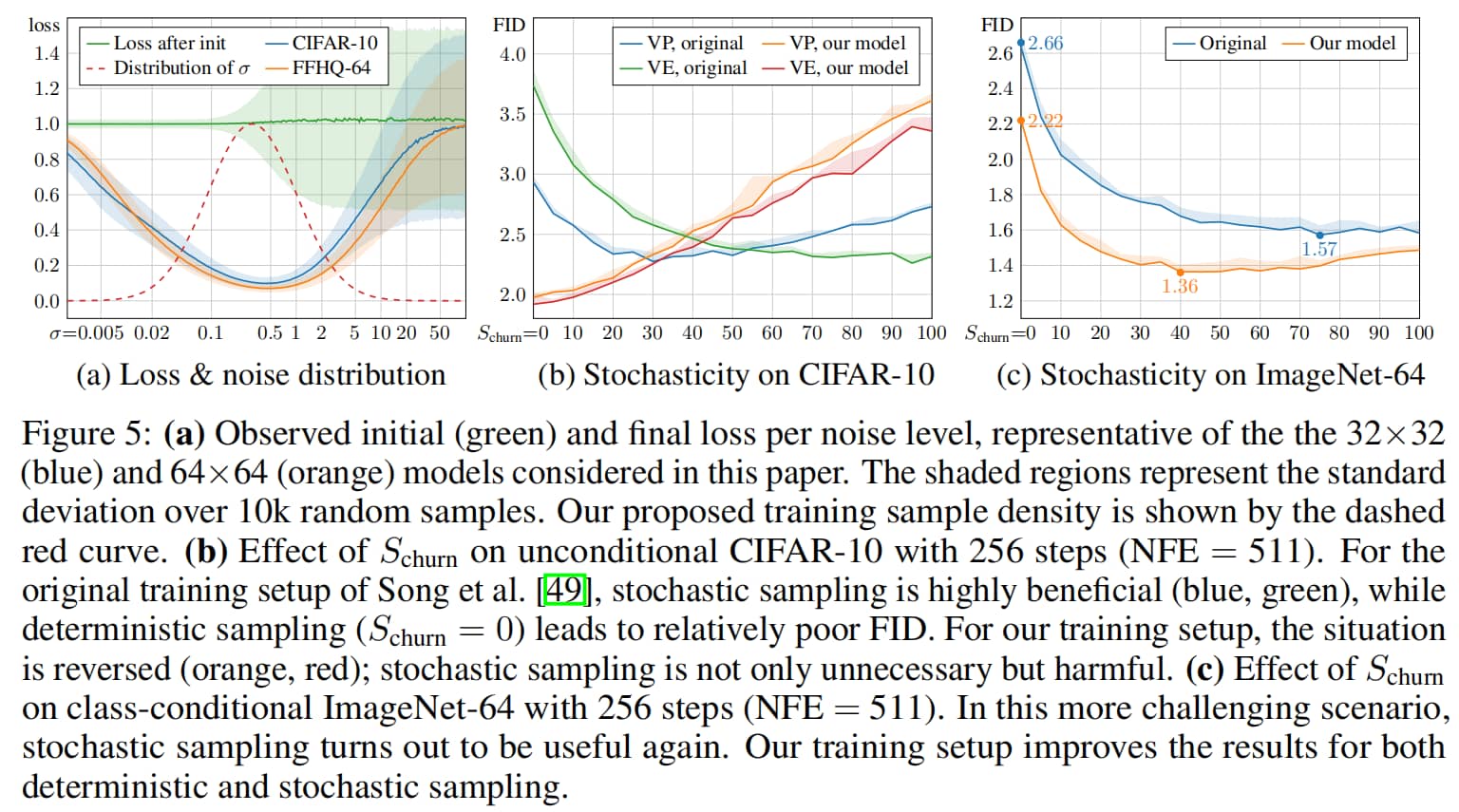
图5:(a) 观测到的初始(绿色)与最终损失随噪声水平变化曲线,分别代表本文研究的32×32(蓝色)和64×64(橙色)模型。阴影区域表示10,000次采样样本的标准差。我们提出的训练样本密度由红色虚线曲线表示。(b) churn参数在256步采样(NFE=511)下对无条件CIFAR-10数据集的影响。在Song等人[49]原始训练配置中,随机采样(蓝色、绿色)效果显著优于确定性采样(churn=0),后者导致相对较差的FID指标。而采用我们的训练配置时(橙色、红色),情况发生逆转——随机采样不仅不必要反而有害。(c) churn参数在256步采样(NFE=511)下对类别条件ImageNet-64数据集的影响。在这个更具挑战性的场景中,随机采样再次展现出优势。我们的训练配置同时提升了确定性采样和随机采样的效果。
σ \sigma σ EDM 设计 p t r a i n ( σ ) p_{train}(\sigma) p t r ain ( σ )
ln ( σ ) ∼ N ( P mean , P std 2 ) , P mean = − 1.2 , P std = 1.2 \ln (\sigma) \sim \mathcal{N}(P_{\text{mean}}, P_{\text{std}}^2), \quad P_{\text{mean}} = -1.2, \ P_{\text{std}} = 1.2
ln ( σ ) ∼ N ( P mean , P std 2 ) , P mean = − 1.2 , P std = 1.2
采用上述分布的原因:
根据实验结果,损失函数下降比较多的地方是中等噪声水平;
当噪声水平较低时,模型预测的相对误差较大,损失函数难以下降;
当噪声水平较高时,对真实图像扰动较大,每一个样本的学习目标与样本均值目标差距较大,损失函数也难以下降。
于是,EDM 选择让网络侧重于在中等噪声水平下学习。如上图(a)
增强正则化
为防止小规模数据集训练扩散模型时常见的过拟合问题,我们借鉴了生成对抗网络(GAN)领域的增强流程[25]。该流程包含多种几何变换(详见附录F.2),我们在向训练图像添加噪声前对其应用这些变换。为防止增强操作“泄露”到生成图像中,我们将增强参数作为条件输入传入 F θ F_\theta F θ
表2显示,数据增强能带来一致性的性能提升(对应配置F):在类别条件和无条件CIFAR-10任务上,模型分别取得了1.79和1.97的新最先进(SOTA)FID,超过了此前1.85[45]和2.10[53]的记录。
随机采样再探讨
有趣的是,如图5b、c所示,随着模型本身性能的提升,随机采样的必要性似乎在降低。在CIFAR-10数据集上使用我们的训练配置时(图5b),确定性采样能取得最佳结果,而任何程度的随机采样都会产生不利影响。
ImageNet-64实验
作为最后一项实验,我们基于提出的训练改进方案,从零开始训练了一个类别条件ImageNet-64模型。该模型取得了新的最先进(SOTA)FID,数值为1.36,而此前的纪录为1.48[17]。我们采用了ADM架构[9]且未做任何修改,同时使用我们的E配置进行训练,并仅做了少量调优;详细细节参见附录F.3。我们发现过拟合问题无需担忧,因此未采用增强正则化。如图5c所示,随机采样的最优强度远低于预训练模型的情况,但与CIFAR-10数据集不同,随机采样的效果明显优于确定性采样。这表明,对于多样性更高的数据集,随机采样仍能持续带来收益。
留着
轨迹曲率与噪声调度
ODE解轨迹的形状由函数 σ ( t ) \sigma(t) σ ( t ) s ( t ) s(t) s ( t ) d x d t \frac{dx}{dt} d t d x
我们认为,这两个函数的最优选择是 σ ( t ) = t \sigma(t) = t σ ( t ) = t s ( t ) = 1 s(t) = 1 s ( t ) = 1 d x d t = x − D ( x ; t ) t \frac{dx}{dt} = \frac{x - D(x;t)}{t} d t d x = t x − D ( x ; t ) σ \sigma σ t t t
这一选择带来的直接结果是:在任意 x x x t t t t = 0 t=0 t = 0 D θ ( x ; t ) D_\theta(x;t) D θ ( x ; t ) σ \sigma σ
将 σ ( t ) = t \sigma(t) = t σ ( t ) = t s ( t ) = 1 s(t) = 1 s ( t ) = 1
讨论
本节中为改进确定性采样所做的各项选择,已汇总至表1的“采样(Sampling)”部分。这些选择共同作用,大幅降低了生成高质量结果所需的神经函数评估次数(NFE):方差保持(VP)模型降低7.3倍,方差爆炸(VE)模型降低300倍,去噪扩散隐式模型(DDIM)降低3.2倍,对应图2中突出显示的NFE数值。在实际应用中,在单张NVIDIA V100显卡上,每秒可生成26.3张高质量的CIFAR-10图像。
这种一致性的改进验证了我们的假设:采样过程与各模型的原始训练方式相互正交(即彼此独立,互不影响)。为进一步验证,我们将自适应RK45方法[11]结合本文提出的调度方案进行实验,结果以图2中的黑色虚线展示;该复杂常微分方程(ODE)求解器的计算成本远超其带来的收益,因此并非最优选择。
6 结论
我们将扩散模型纳入统一框架的方法,呈现出了模块化的设计结构。这使得我们能够针对性研究各个组件,进而有可能更好地覆盖可行设计空间。在我们的测试中,这种设计使我们能够直接替换各类早期模型中的采样器,从而显著提升结果性能。例如,在ImageNet-64数据集上,我们的采样器将一个普通模型(FID为2.07)转变为能与此前最先进(SOTA)模型(FID为1.48[17])竞争的模型;而结合训练改进后,模型更是取得了1.36的SOTA FID。在CIFAR-10数据集上,我们仅需35次模型评估、采用确定性采样并使用小型网络,就取得了新的最先进结果。
当前的高分辨率扩散模型要么依赖独立的超分辨率步骤[17,36,40]、子空间投影[23]、超大网络[9,49],要么采用混合方法[39,42,53]——我们认为,我们的研究贡献与这些扩展方向相互正交。尽管如此,对于更高分辨率的数据集,我们的许多参数值可能仍需重新调整。此外,我们认为,随机采样与训练目标之间的精确相互作用,仍是未来值得研究的有趣问题。
预处理与训练
回顾两个误差来源:
Preconditioning
改进Heun步
算法2